一、前言:
今天对es集群做扩容节点操作,新增了一台节点,启动节点后,没过15分钟,监控报警节点es服务端口异常。 第一次看日志并没有发现太明显的错误,于是并没有做操作,直接将该节点重新启动。
结果不到10分钟时间,节点又崩溃了,看来得排查下问题原因。
二、环境信息:
- 内存:128G
- cpu: 40C
- es版本:5.6.2
节点只部署了es服务。
es JVM配置信息:
-Xms32g
-Xmx32g
-XX:+UseG1GC
-XX:+ExplicitGCInvokesConcurrent
-XX:+UseGCOverheadLimit
-XX:InitiatingHeapOccupancyPercent=40
-XX:ParallelGCThreads=20
-XX:ConcGCThreads=8
-XX:MaxGCPauseMillis=100
-XX:G1ReservePercent=15
三、问题描述:
- es集群没有明显的日志报错。
- 节点的gc日志没有明显的异常。
- es安装目录下出现了一个
hs_err_pidxxxx.log文件。
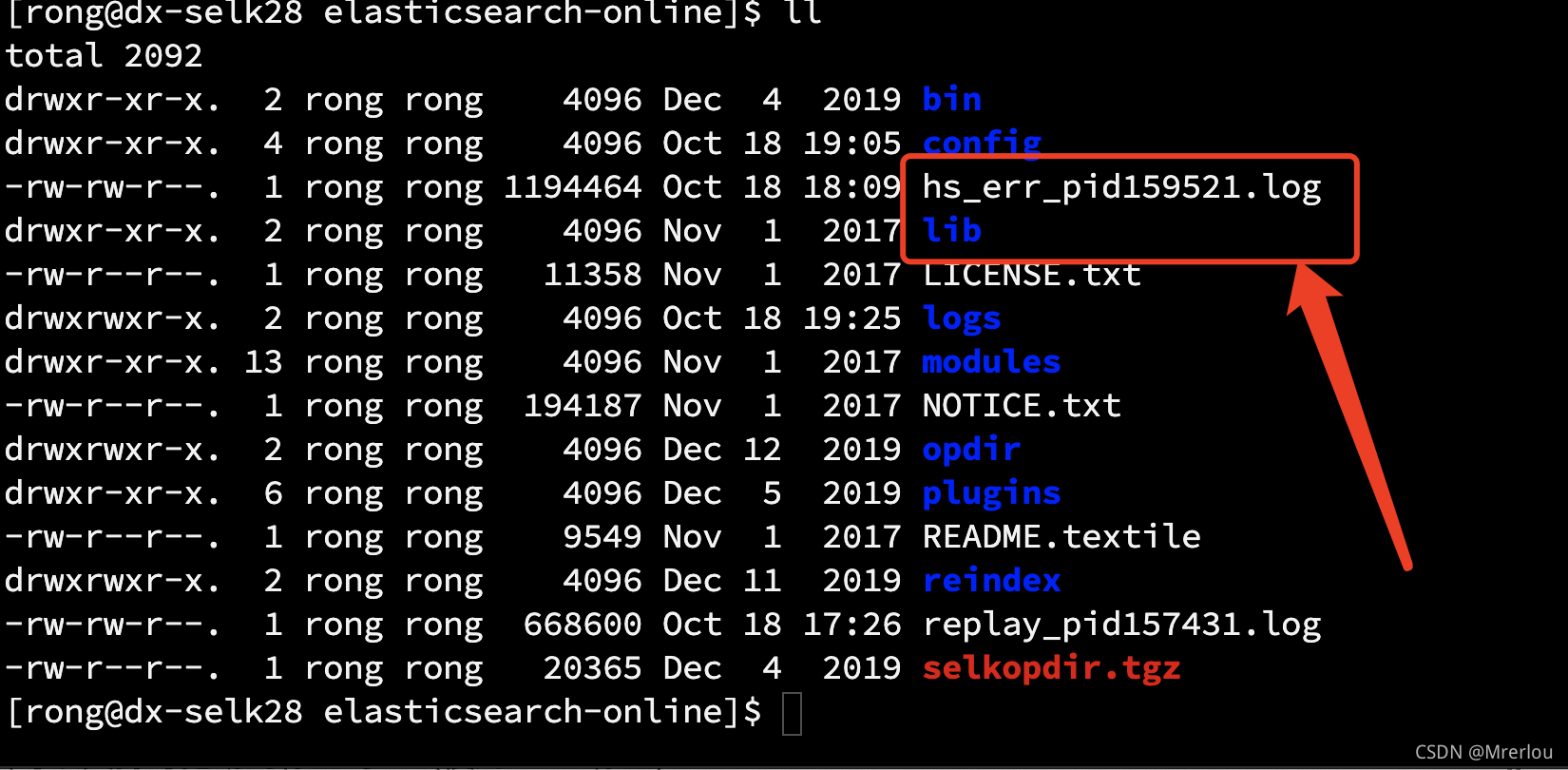
pidxxx.log文件大多是因为JVM异常,或者是操作系统引发的错误。并不是GC异常。
查看hs_err_pidxxxx.log内容:
# Out of Memory Error (os_linux.cpp:2627), pid=159521, tid=139711002605312
#
# JRE version: Java(TM) SE Runtime Environment (8.0_73-b02) (build 1.8.0_73-b02)
# Java VM: Java HotSpot(TM) 64-Bit Server VM (25.73-b02 mixed mode linux-amd64 )
# Failed to write core dump. Core dumps have been disabled. To enable core dumping, try "ulimit -c unlimited" before starting Java again
#
--------------- T H R E A D ---------------
Current thread (0x00007fc334011000): JavaThread "elasticsearch[dx-selk28.dx][[kefu_dx_push_task_v1][0]: Lucene Merge Thread #13]" daemon [_thread_new, id=161099, stack(0x00007f11009e7000,0x00007f1100ae8000)]
Stack: [0x00007f11009e7000,0x00007f1100ae8000], sp=0x00007f1100ae69c0, free space=1022k
Native frames: (J=compiled Java code, j=interpreted, Vv=VM code, C=native code)
V [libjvm.so+0xaba71a] VMError::report_and_die()+0x2ba
V [libjvm.so+0x4f9ecb] report_vm_out_of_memory(char const*, int, unsigned long, VMErrorType, char const*)+0x8b
V [libjvm.so+0x91b553] os::Linux::commit_memory_impl(char*, unsigned long, bool)+0x103
V [libjvm.so+0x91b61c] os::pd_commit_memory(char*, unsigned long, bool)+0xc
V [libjvm.so+0x9150da] os::commit_memory(char*, unsigned long, bool)+0x2a
四、问题原因:
这个问题是由于/proc/meminfo下的vm.overcommit_memory被设置成不允许overcommit造成的
首先了解一下overcommit的意思: 用户进程申请的是虚拟地址, 而这个虚拟地址是不允许任意申请的, 因为虚拟内存需要物理内存做支撑, 如果分配太多虚拟内存, 会对性能参数影响vm. overcommit就是对虚拟内存的过量分配
vm.overcommit_memory的用处: 控制过量分配的策略. 这个参数一共有3个可选值:
- 0: Heuristic overcommit handling. 就是由操作系统自己决定过量分配策略
- 1: Always overcommit. 一直允许过量分配
- 2: Don’t overcommit. 不允许过量分配
我们使用sysctl vm.overcommit_memory来查看, 发现vm.overcommit_memory = 2, 即采用的是不允许过量分配的设置。
Committed_AS: OS会预测启动这个程序时, 所有的进程可能会用到多少的内存, 如果超过了CommitLimit, 就会报错。
五、解决方案:
解决方案是sudo sysctl vm.overcommit_memory=0, 即vm.overcommit_memory = 0, 允许系统自己决定过量分配策略。
参考链接:
- https://www.jianshu.com/p/3f8692eb3660