2015年6月27日,清华大学FIT楼多功能报告厅,中国中文信息学会青年工委系列学术活动——知识图谱研究青年学者研讨会。
由于我毕设是与知识图谱、实体消歧、实体对齐、知识集成相关的,所以去听了这个报告;同时报告中采用手写笔记,所以没有相应的PPT和原图(遗憾),很多图是我自己画的找的,可能存在遗漏或表述不清的地方,请海涵~很多算法还在学习研究中,最后希望文章对大家有所帮助吧!感谢那些分享的牛人,知识版权归他们所有。
目录:
一.面向知识图谱的信息抽取技术
二.常识知识在结构化知识库构建中的应用
三.浅谈逻辑规则在知识图谱表示学习中的应用
四.大规模知识图谱表示学习
五.知识图谱中推理技术及工具介绍
六.多语言知识图谱中的知识链接
七.知识图谱关键技术和在企业中的应用
PPT免费下载地址:http://download.csdn.net/detail/eastmount/9159689
一.面向知识图谱的信息抽取技术——韩先培(中科院)
下图是我自己根据讲述内容笔记绘制的大纲:
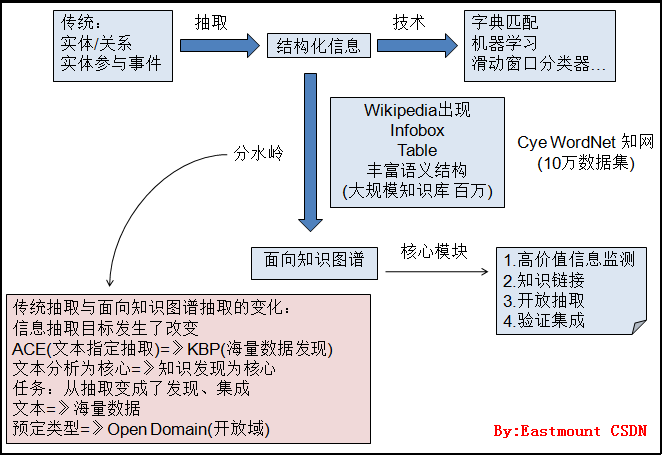
传统知识抽取主要是抽取是以实体、关系和事件为主的结构化信息抽取;随着维基百科的出现,导致了面向知识图谱的信息抽取,主要的变化包括:抽取目标发生了变化,从ACE文本分析抽取到KBP海量数据发现集成,同时传统的抽取是预指定类型到现在的基于开放域、变化数据的抽取。
韩先陪老师主要从以下四个部分分别进行了详细的讲解。
1.高价值信息检测
以知识为核心的高价值信息包括:高价值结构和高价值文本。其中高价值结构例如Wikipedia的InfoBox(消息盒),Web Table等。再如高价值文本:
姚明身高2.29m
姚明爸爸身高2.08m,姚明比他爸高21cm
显然第一段文字信息获取价值更高,第二段文字还需要分析关系+身高相加。
2.知识链接link
对自然语言文本信息与知识库中的条目进行链接,但不同数据源会存在冗余信息或歧义,词义消歧的例子如下:
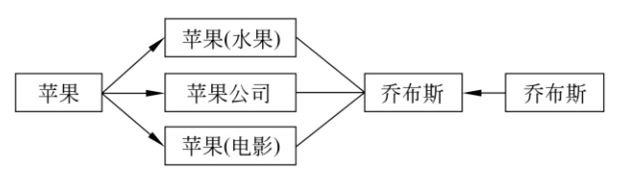
例如“苹果”和“乔布斯”通过命名实体消歧确定为“苹果(公司)”。实体链接可以利用上下文相似度、文本主题一致性实现,主要有两类方法:
1) 实体链接方法——统计方法
通过知识库和大规模语料+深度学习模型实现。
2) 实体链接方法——图方法
计算最大似然链接结果的算法
3.开放抽取
传统的抽取方法:人工标注语料+机器学习算法,但成本高、性能低、需要预定义。
所以提出了按需抽取、开放抽取等内容。
1) 按需抽取
算法Bootstrapping,主要步骤包括:模板生成=》实例抽取=》迭代直至收敛,但会存在语义漂移线性。
2) 开放抽取
通过识别表达语义关系的短语来抽取实体之间的关系,工具ReVerb。如抽取“华为总部深圳”,它的优点是无需预先指定,缺点是语义归一化。
知识监督开放抽取,基于噪音实例去除的DS方法。Open IE(知识抽取)
4.验证集成
知识集成需要保证其准确性和可靠性,同时知识图谱需要增加知识、更新知识,需要确保其一致性。
数据集成Google's Knowledge Vault,数据来源包括DOM、HTML表格、RDFa、文本等,方法最大熵模型融合数据/分类器。
例如我在做实体对齐时就会遇到这样的知识集成。维基百科中Infobox属性“总部位于、总部建于、总部设置于”都是映射统一概念“总部位置”,这就需要知识集成、实体属性对齐,常用的方法包括:聚类相似度、短语相似度等。
总结:本文讲述了从传统IE(知识抽取)到面向知识图谱IE,文本为核心到知识获取为核心,封闭信息类别到基于开放的知识抽取,更关注Retall、precision等概念和例子。
二.常识知识在结构化知识库构建中的应用——冯岩松
Common Sense Knowledge in Automatic Knowledge Base Population
下图是我总结的一张图,主要包含的一些知识,因为冯老师讲的是英文PPT,很多东西我也不太懂或还在学习中,所以只能讲述些简单的知识,还请见谅。
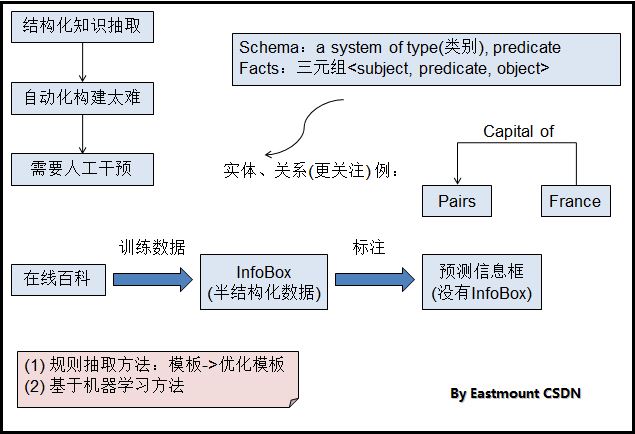
这里使用的三元组是<subject, predicate, object>,举例:维基百科中已经存在了“姚明”的InfoBox半结构化数据,同时对应有详细的介绍;现在给你“郭艾伦”一篇的详细信息,让你通过类似的方法进行标注抽取属性和值,并预测一个InfoBox信息框。
但同时在抽取信息过程中会存在噪声,例如一句话包含“安倍”和“日本”,但未必能确定他的国籍;再如“乔布斯回苹果了”这句话不能确定他是苹果的CEO。
知识不应仅是<s,p,o>,实际上知识是相互关联的,通过关联才能发挥它最大效应。
eg1:
Mao was born in China.
Mao was born in US.
eg2:
Mao was born in 1991.
Mao graduated from MIT in 1993.
很显然,Mao不可能即出生在中国又出生在美国;Mao也不可能只用2年的时间读完MIT所有课程。即使是一个小学生可能都知道这个道理。
但是你否定它是用你的常识,而不是<s,p,o>技术。Knowledge beyond <s,p,o>
解决方法是通过A tpye of Common Sense Knowledge(CSK)常识知识实现,包括因果解释、生活规律、知识推理等,把常识约束加入到模型之中去,通过实体Preference(偏好)、Constraint(约束)加入。
举个简单例子:
在知识问答中“Which is the biggest city in China?”,可以通过CSK定义最高级常识如longest映射到长度length,biggest映射城市面积最大。通过定义一些常识,其效果都有相应的提升。
三.浅谈逻辑规则在知识图谱表示学习中的应用——王泉
主要讲述了逻辑规则+表示学习应用到知识图谱中,主要内容如下:
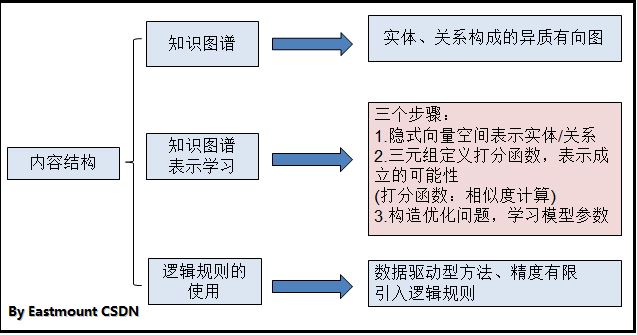
由于数据驱动方法和精度有限(广泛相关!=精确匹配),需要引入逻辑规则。其中知识图谱表示学习主要的三个步骤如上图所示,由于涉及到很多数学、算法方面知识,我也不是很理解。其中包括:RESCAL基于重构误差的方法、基于排序损失的方法TransE、流水线式方法(马尔科夫逻辑网络、0-1整数线性规划)、联合式方法。
举个例子:
问圣安东尼奥(NBA马刺队)位于美国哪个州State?
它给出的答案应该是排序序列,答案至少都是美国的州,但精确定位唯一答案比较难。其解决方法就可以加入文中讲到的“逻辑规则+表示学习”实现。
四.大规模知识图谱表示学习——刘知远(清华大学自然语言处理)
一个著名的公式:机器学习=数据表示+学习目标+优化方式
现在面临的挑战是缺乏统一的语义表示和分析手段,而表示学习的目的就是建立统一的语义表示空间。
知识图谱包括实体和关系,节点表示实体,连边表示关系,采用三元组<head,relation,tail>来实现。大规模知识获取从文本数据抽取关系发展到了从知识图谱抽取关系,其挑战是高维。
知识表示代表模型包括:Neural Tensor Network(NTN)、TransE(Translation-based Entity)
。
其中研究趋势主要包括以下几个方面:
1.知识表示研究趋势:一对多关系处理
例如:
美国总统是奥巴马
美国总统是克林顿
美国总统到底是谁?TransE假设无法较好处理一对多、多对多的关系,其趋势是不同类型的relation怎么表示学习?
2.知识表示研究趋势:文本+KG融合
TransE+Word2Vec就是文本方法和知识图谱方法相融合,KG对应TransE方法,文本Text对应Word2Vec模型。基于CNN的关系抽取模型,建立对词汇、实体、关系的统一表示空间。
3.知识表示研究确实:关系路径表示
知识图谱中存在复杂的推理关系,关系路径算法(实体预测、关系预测)。RNN(Recurslve Neural Network)、PTransE(ADD,3-step)。
中间对四位老师的提问:
1.中文文本聚类
文本自动生成摘要信息,词与词之间关系、句子主干主谓宾提取、句子压缩、获取任务相关的鲜艳信息。
2.不同语言的知识图谱
现趋势文本+KG(知识图谱)相结合,而对不同语言呢?知识不应该有语言的障碍,语言相当于只是添加了标签label,关系是客观存在的(唯一关系标识),如“情侣”、“恋人”只是表达不同。
3.淘宝商品种类多、更新快,海量数据类别大,需要知识图谱吗?
目前淘宝做得这么好,没有必要。KG适合复杂推理关系,但产品属性可以通过知识图谱存储。知识图谱是基础构建,抽取结构化、半结构化信息当成知识,应用于NLP、AI、问答系统、理解事件等。
五.知识图谱中推理技术及工具介绍——漆佳林
An Introduction of Reasoning in Knowledge Graph and Reasoning Tools
本体规则推理,Ontology(本体)起源于哲学,表示形式化词汇定义、抽象概念。数据异构性包括
结构化数据、半结构化数据和非结构化数据的集成。
本体语义三个标准:
1.RDF:Resource Description Frameword
2.RDFs:Classes例如MusicArtist音乐家
3.OWL:Web Ontology Language,W3C标准,hierarchy分层
包括Domain和Range
如:“独奏音乐家”属于“音乐艺术家”属于“艺术家”,具有传递性。
推理解决现实问题例如:
北京路发生追尾(BeijingRoad
⊆ ョoccur Rear-end
) 、王军在北京路...可以推理王军堵车。
工具:
Dbpedia知识库是基于Wikipedia,WebPIE工具-MapReduce(平台Platform)-OWL(语言),Marvin-PeertoPeer(平台)-RDF(语言),SAOR\GEL-基于图数据库的平台-OWLEL(语言)。
再如推荐流行歌例子:
小明喜欢周杰伦歌手 小明是年轻人 难
周杰伦歌手唱流行歌 =》 小明是周杰伦粉丝 正确
周杰伦唱《牛仔很忙》 《牛仔很忙》是流行歌 正确
六.多语言知识图谱中的知识链接——王志春
DBpedia知识图谱是Wikipedia(维基百科)的DBpedia extraction framework
维基百科一个页面如下所示,包括:Title、Description、InfoBox、Categories(实体类别)、Crosslingual Links(跨语言链接)。
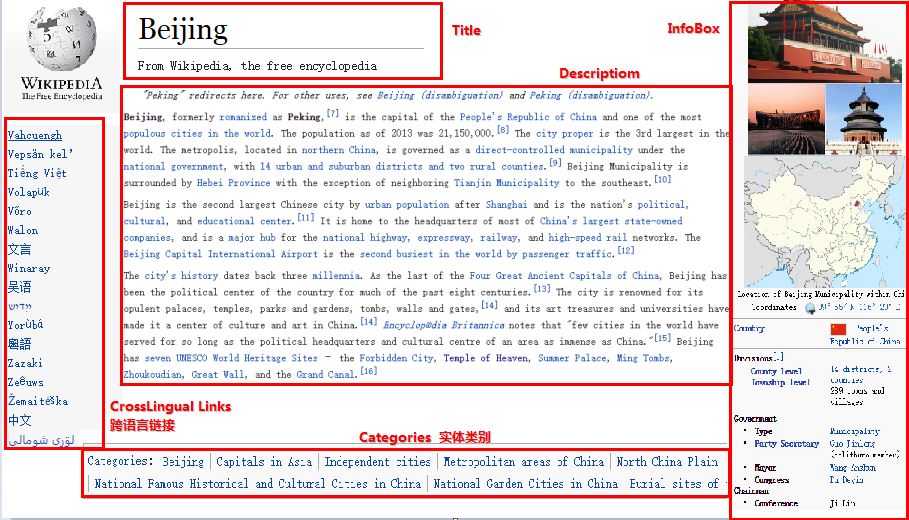
例如“清华大学”中文、发文和英文EN的“清华大学”实体是指称项一致的,通过实体链接实现不同语言链接。
规范化数据集:http://mappings.dbpedia.org/
http://dbpedia.org/
知识库:
BabelNet知识库、WordNet、机器翻译工具Google Translation
Freebase and Wikidata,Freebase关闭了,变成了Wikidata知识库。在Wikidata中传统的Entity、Relation变成了item,不同语言标记不同,EN label、CN label、FR label标记。
YAGO3,Wikipedia+WordNet+GeoNames,添加了地理位置信息、时间信息、多源版本。
王志春老师们做了个把维基百科、百度百科、互动百科联系在一起的中英文的LORE。我的毕设是基于三个百科和多源网站的旅游景点知识对齐融合技术,感触颇深。
总体来说,DBpedia、BabelNet、WikiData、YAGO3都来源于Wikipedia。通过Cross-lingual Knowledge Linking链接发现中英文,主要通过相似性和链接关系实现。
七.知识图谱关键技术和在企业中的应用——王昊奋
Publishing and Consuming Knowledge Graphs in Vertical Sectors
如何从数据中发现商业价值,主要看全面数据、可访问的、可移植(Action)三方面。知识图谱在企业中的应用简单包括:
IBM的Watson通过分析病人症状,来实现自动诊断、分析病情、推荐药物
自动诊断Automatic ICD Coding,通过EMR(电子病历)建立相应的SG(图谱)
在生物医药方面应用Open Phacts
Agriculture农业方面,各种形态的异构数据,生物论文Pubmed
Amdocs电信方面CRM(客户关系管理),如一位信用好的老客户该月的电话费比平时增加了30块,发现是自己的女儿下载了一个游戏业务,当该客户打电话过去,电信公司就已经取消了该游戏业务,这是怎么实现的呢?它就涉及到了相关的技术。
2012年伦敦奥运会新闻信息,很多都是自动生成的
Enterprise Knowledge Graph
由于会议要开到5点半,还有两个主题:
Natural Language Question Answering Over Knowledge Graph: A Data-driven Approach
知识库问答的问题与挑战
但我北邮有个同学要毕业了,我就提前离开了参加聚餐去了。最后希望文章对你有所帮助吧!因为不同主讲人讲述的内容不同,它们之间存在着一定联系,但又不是很密切,同时自己的深度和理解还不够,所以文章比较涣散,但作为总结分享出来,你也可以简单学习。后面如果我写毕业论文相关的博客,文章相关度和层次就一目了然了。
(By:Eastmount 2015-6-29 半夜4点半 http://blog.csdn.net/eastmount/)