架构实现
Mycat作为数据库高可用中间件具备很多的功能,如负载均衡,分库分表,读写分离,故障迁移等。结合项目的实际情况,分库分表功能对于关联查询有很高的要求,需要从业务角度考虑分库分表后的关联查询SQL的分析,业务代码动作较大,所以在此方案中我们不考虑分库分表。主要应用Mycat的负载均衡及故障迁移的功能即可。
整个架构改造包括两个部分,第一是单例Mysql改为多个Mysql,同时负载均衡,并且一主多备,一台宕机后,自动切换到其他备机,主备之间复制。第二个由于使用了Mycat作为代理,所以也要考虑到Mycat的高可用

两台Mysql,一主一备,通过原生的复制机制实现双向复制,加入Mycat中间件代理两台Mysql,实现读写的负载均衡,并且Mycat通过心跳机制检测到主库宕机后,自动切换到备机。业务测代码不需要修改,只需要修改数据库的连接由Mysql的地址切换到Mycat即可。
第二部分的改造也有两种方案,第一种:将一台Mycat扩展为两台,业务测访问VIP(虚拟IP),两台keepalive竞争VIP,并由HAproxy转发到其中一台Mycat,实现负载均衡高可用。

第二种:Mycat依旧为两台,但是负载均衡不在服务端,而是放在客户端(及业务代码端),使用java原生提供的LoadBalancing协议,将对数据库的读写请求负载在多个Mycat实例上实现Mycat的高可用。LoadBalancing原理:mysql connector/J驱动创建的LoadBalancedConnection是一个逻辑链接,其内部持有一个物理链接列表,即与每个host建立一个Connection。url中的每个host都是平等的主host,当客户端获取连接时会有两种random(默认随机)和bestResponseTime(最小响应时间)两种均衡策略

关于两种方案的选择,方案一自定义软负载是自己实现的,功能单一,负载策略只有轮询,而且健康检查在很长一段时间出现连接泄露的问题,稳定性不够好,还需要做一些优化和测试进行打磨;方案二是基于mysql的java连接驱动做的负载均衡,是官方提供的方案,稳定性和可用性更高,而且我们在经过很长一段时间的压测和容错性测试,发现其性能很优越,负载均衡策略也更丰富,使用过程更简单,所以决定使用方案二。
环境搭建
Mycat+Mysql搭建
首先在两台Linux主机上安装Mycat,然后再安装两台Mysql,端口号分别为3301和3302,安装方法这里不赘述。。接着对两台Mycat进行配置,分别代理两台Mysql数据库,注意以下配置文件:
server.xml
主要配置mycat的登陆用户名,密码和代理的数据库schemas
<user name="root">
<property name="password">mycat0001</property>
<property name="schemas">zmall</property>
<property name="readOnly">false</property>
这里配置了
其中一台mycat主机的用户名root,密码mycat0001,代理的数据库名zmall。
schemas.xml
因为不做分库分表,所以<schema标签不用配置<table子标签,但是需要配置datanode属性:
<schema name="zmall" dataNode="zmall" checkSQLschema="false" sqlMaxLimit="100">
然后配置一个datanode作为逻辑库:
<dataNode name="zmall" dataHost="host_zmall" database="zmall" />
然后配置<datahost标签,实现代理一主一从两个Mysql数据库,并且从库也为主库的备用库
<dataHost name="host_zmall" maxCon="1000" minCon="10" balance="2" writeType="0" dbType="mysql" dbDriver="native" switchType="1" slaveThreshold="100">
<heartbeat>show slave status</heartbeat>
<!-- 主库 -->
<writeHost host="zmall_m1" url="172.16.23.126:3301" user="root" password="zmall3301"></writeHost>
<!-- 从库 -->
<readHost host="zmall_s1" url="172.16.23.126:3302" user="root" password="zmall3302" />
<!-- 备份主库 -->
<writeHost host="zmall_m2" url="172.16.23.126:3302" user="root" password="zmall3302"></writeHost>
<!-- 从库 -->
<readHost host="zmall_s2" url="172.16.23.126:3301" user="root" password="zmall3301" />
</dataHost>
这里需要注意的是balance类型设置为2,所有的主库和从库都参与读操作的负载均衡。
功能验证
负载均衡
启动两台Mysql和两台Mycat,从任意一台Mysql主机访问Mycat,指令为:
mysql -h172.16.23.126 -P8066 -uroot -pmycat0001
端口指向其中一台Mycat,用户名密码,执行多次查询操作,可见下图中展示的结果,已实现了在主从库中负载读的操作:
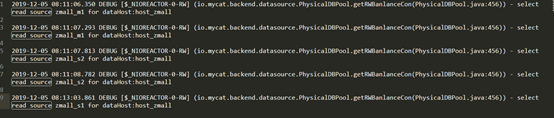
故障迁移
手动停掉主库模拟数据库宕机的情况,mycat自动将从库切换为主库,不影响读写操作,可见下图日志中展示的结果,实现了自动故障迁移功能:

当主库故障恢复后,再次测试多次查询操作,恢复到之前的负载均衡状态。
主从复制
关于主从复制功能,因为目前一主一从的架构下写操作都在主库,读操作在主库与从库间负载,所以需要主从保持复制同步数据。这里使用Mysql原生的复制机制,通过bin log实现数据的同步。验证过程:同样登陆mycat,执行插入,修改或删除操作,首先数据会入主库,查询主库表能够查询到写操作的结果,这时再查询从库,发现数据和主库一致,说明复制操作完成。当停掉其中一个数据库后,再次执行插入,修改或删除操作,然后手动恢复停掉的数据库,再次查询该数据库的表数据,发现两库数据保持一致,说明在故障恢复后,主从复制的机制仍然有效。
性能测试
新的架构环境搭建成功后,最重要的就是要做性能测试了,分别对老架构下的单例Mysql和新架构下的数据库访问做压力测试,分别得出两者在高请求压力下的性能表现,并作出分析和对比,得出改造后的性能提升率。
测试前提准备
模拟现网项目的真实场景,将两台Mysql数据库的最大连接数设置和现网项目保持一致,这里我们设置为2000。
采集样本准备
准备两组采集样本,第一组采集对单例mysql读操作的性能数据,初始并发请求为0,每过10秒钟增加100并发请求,一直增加到并发5000,然后保持60秒,然后每秒减少100并发,直到并发为0。通过对上述场景下的mysql单例吞吐量,请求书,失败率三个方面表现做观察和分析。第二组则对Mycat架构下一主一从的mysql做读操作的性能数据,同样采用以上的递增并发测试场景。
压测工具准备
采用开源压力测试工具JMeter作为本次的性能压力测试工具,并创建压测模板。新建两个stepping thread group,一个是连接单例mysql,一个连接mycat,采用同样的读查询SQL。

压测结果分析
首先在对单例mysql的测试中我们可以看到结果如下:

看到刚开始时请求成功的TPS达到1700左右,然后随着并发量的提升,TPS逐渐降低,到4分钟时差不多降到1600左右,这个时候的并发请求快到了2000,后面继续降低,并且开始出现请求错误的响应,继续到9分钟左右,并发到达峰值5000,成功请求TPS降到1500左右。

钟总共处理请求数155万,平均响应时长1014ms,响应错误率13.46%,也就是成功响应的请求数为134万。
然后看mycat代理2台mysql负载均衡的测试结果:

到刚开始时请求成功的TPS达到3500左右,然后随着并发量的提升,TPS逐渐降低,到4分钟时差不多降到3300左右,这个时候的并发请求快到了2000,后面继续降低,并且开始出现请求错误的响应,继续到9分钟左右,并发到达峰值5000,成功请求TPS降到3100左右。

共处理请求数337万,平均响应时长529ms,响应错误率17.73%,也就是成功响应的请求数为277万。
综合对比分析,可见在mycat的代理分布式mysql的环境下,不论从吞吐量,处理请求书,响应延时以及成功请求数等各方面,几乎提升了一倍的性能,效果比较理想。
稳定性测试
为了保证在升级到新的架构后数据库访问的稳定性,所以要做稳定性测试,在新的mycat代理2台mysql环境下,继续使用JMeter工具压测,测试样本调整为保持2000并发请求,并持续15小时,观察新架构下的数据访问稳定性,从测试结果可以看得出15个小时保持高并发下mycat+mysql表现稳定,总共请求量1亿8千300多万,吞吐量保持在平均3400左右,平均请求延时586ms,总共的请求错误率0.86%,可以说结果比较理想。


扩展性
目前为止已经完成了将单例mysql扩展为2台mysql负载均衡的架构,这里称为扩容阶段1。并且通过压力测试结果可以得出性能确实提升的结论,所以再升级为新的架构后,理论上可以有效缓解现网App客户在使用时的卡顿,响应慢,崩溃等问题。当然考虑到用户量的不断增加,新的架构也必须要考虑到良好的扩展性,对于后期的扩容本文也给出了响应的架构演进,首先看扩容阶段2:

加两台mysql,一共4台,做双主单从,两主互为主备,相互复制,主从之前相互复制,读操作在4台中负载均衡,效率应为阶段1的两倍左右。随着用户量继续增加,再到扩容阶段3:

两台mysql,一共6台,在双主的情况下做双主双从,这时可以将负载均衡策略改为再除了当前主机之外的其他5台mysql做读负载,主机只做写,读写分离,让主机写效率更高。如果用户量还在持续上升,那么架构将演进到最终阶段:

架构升级为N主N从,可以考虑将写负载到N台主库上,所有从库做读负载均衡。
双主一从性能测试
架构

Mycat中间件代理三台mysql做分布式,mysql1和mysql2为主库,并且互为主备,相互复制,mysql3为从库,同时复制mysql1和mysql2。初始情况下mysql1负责写,mysql1,mysql2和mysql3三台负载读,当mysql1宕机时,自动切换到mysql2写,mysql2和mysql3两台负载读。
压力测试结果分析
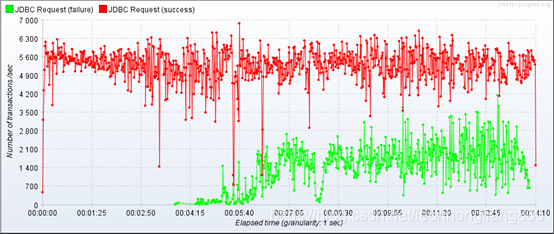
可以看到刚开始时请求成功的TPS达到5600左右,然后随着并发量的提升,TPS逐渐降低,并发到达峰值5000后,成功请求TPS稳定在5200左右。

14分钟总共处理请求数532万,平均响应时长317ms,响应错误率15.77%,也就是成功响应的请求数为448万。
对比单mysql,TPS提升240%,平均响应延时提升220%,请求成功数提升235%
对比mycat代理2台负载,TPS提升64%,平均响应延时提升67%,请求成功数提升62%。