提取的权重的整理
在上一篇文章中,介绍了从神经网络中提取权重的步骤。本节主要介绍对于从神经网络中提取出的权重的整理方法,以适应将权重输入到嵌入式程序中的要求。
一、 使用Excel进行整理
在得到权重数据后,需要对权重进行整理,之后输入到文本文件中。例如,在项目工程中,可能要求将得到的权重矩阵按列排列,排列在文本文件中。对于重复性不多,只需要进行单次或者次数较少的权重整理时,可以考虑使用该方法。
步骤为:
1. 将在pycharm中打印出的数据拷贝到Excel
如图是从pycharm中打印出的权重的数据,粘贴到文本文件的截图:
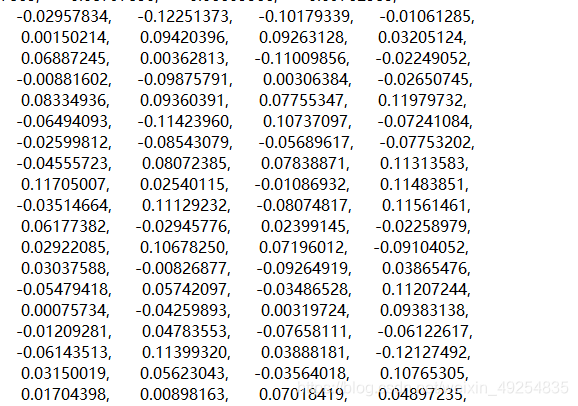
选中数据,粘贴到Excel中可得:
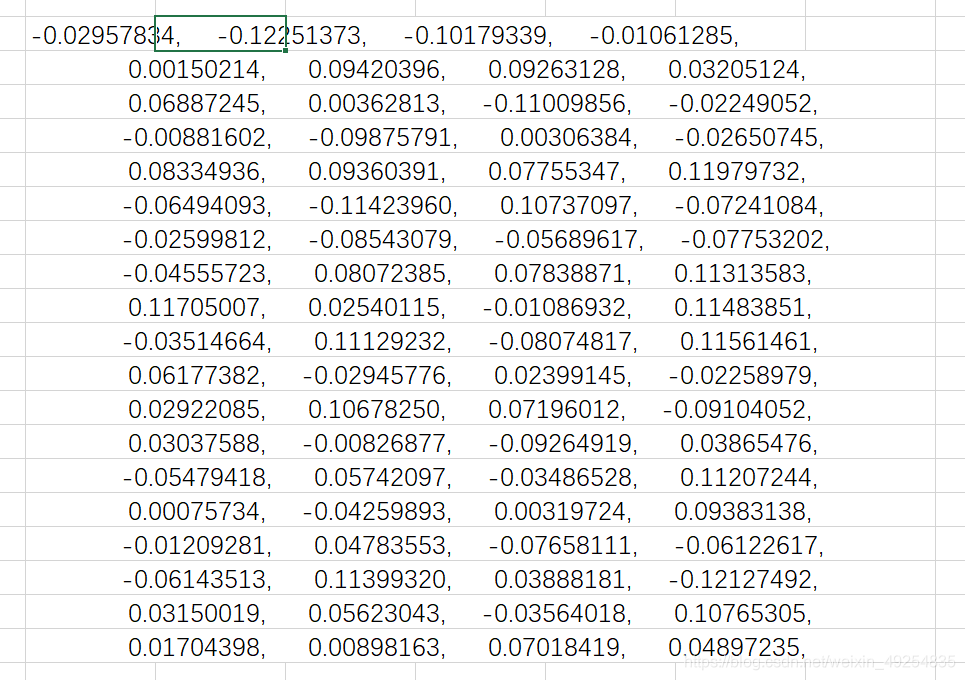
可以发现数据都在第一列对应的单元格中,并不是满足一个单元格一个数据
2. 将数据分列分行,展成表格的形式
使用EXCEL自带的分列功能,实现数据的表格分布。
(1)选中第一列,点击菜单栏-数据-分列
如图所示:

(2)分列具体参数为:
① 选择分隔符号
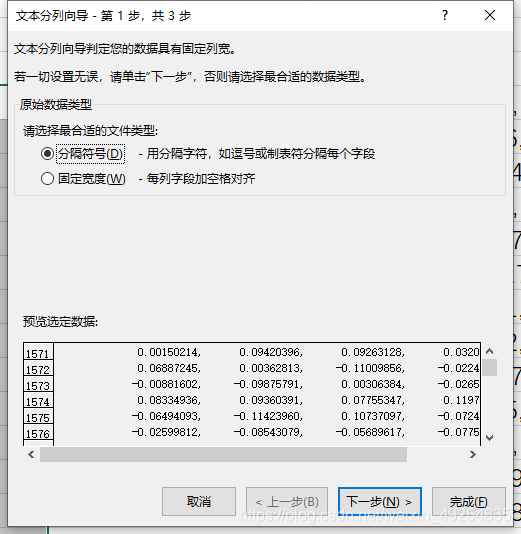
② 在分隔符号中建议全选,因为对于文本中的数据,分隔符号是逗号,因此,在点击分号,下方的数据预览显示为:
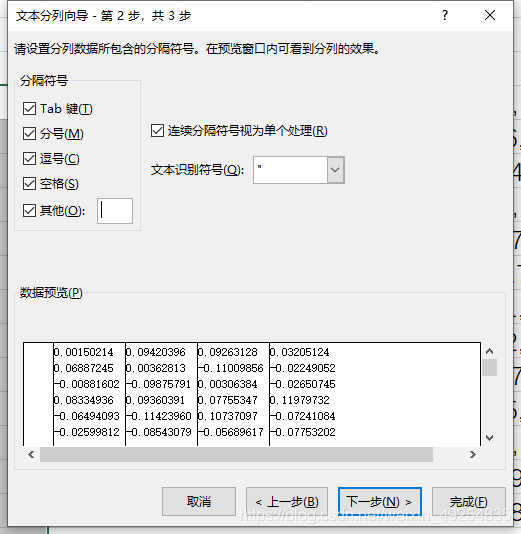
③ 点击完成
之后分列完成的数据如图所示:
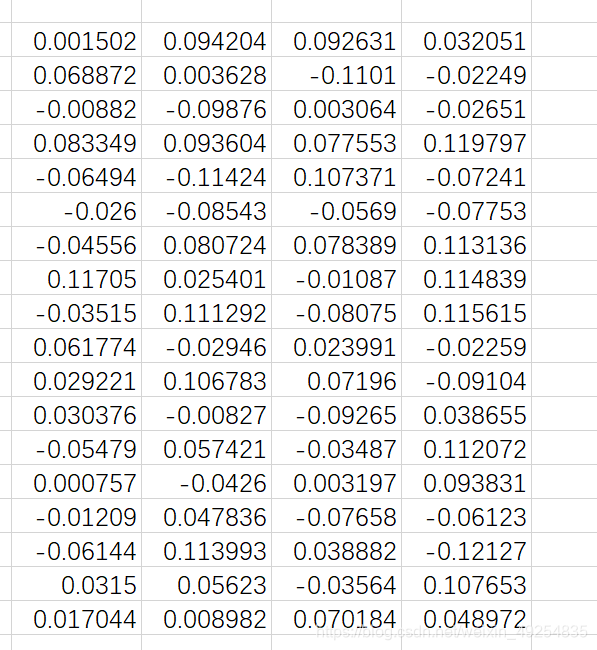
3. 去除存在的[]等符号
r若数据中存在复制过来的张量中带有的[]等符号,如图所示:
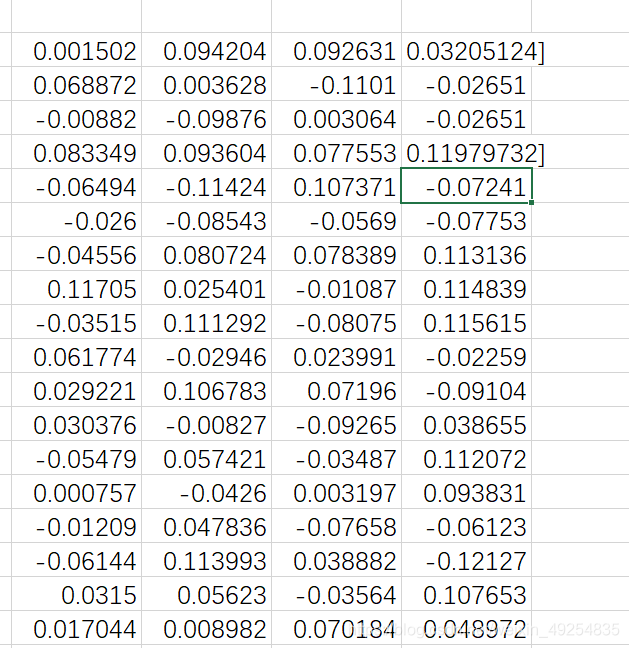
使用EXCEL自带的替换功能(快捷键Ctrl+H)
如图所示:
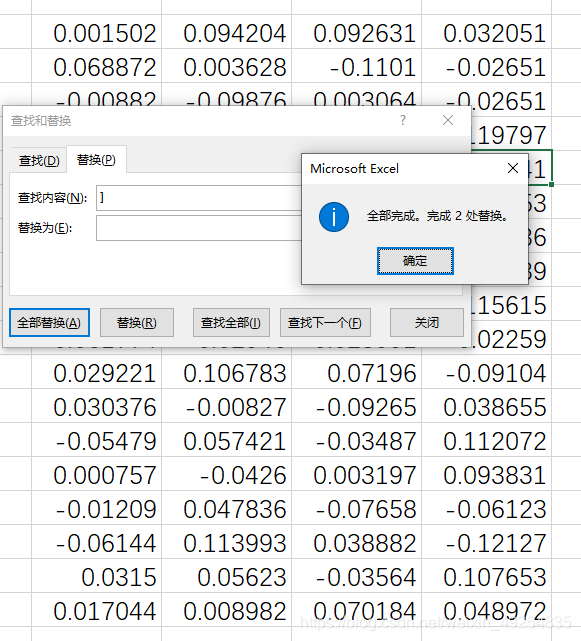
在替换为选项栏中不输入就意味着去除查到的符号,可以看到表格中的]被去掉了
4. 按列的格式排成一列
对于按列排列,就是将第k+1列放到第k列之下,可以使用EXCEL自带的OFFSET()函数完成。
有一种简便的方法是:
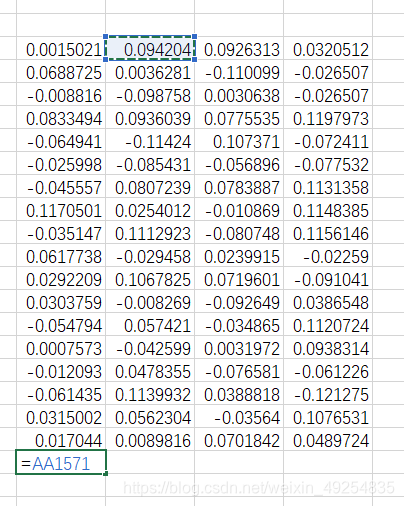
① 在第一列的最后一行的下一行输入=,之后点击第二列第一行对应的行首
如图所示:
② 之后将最后一行的单元格其右拖动,实现铺满所有列
如图所示:
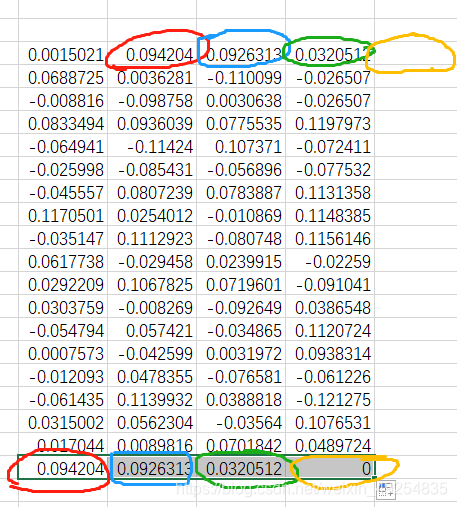
此时每列的最后一行显示的下一列的第一行的数据
③ 之后将最后一行往下拖动,直至所有列的同一行都是0为止
如图所示:
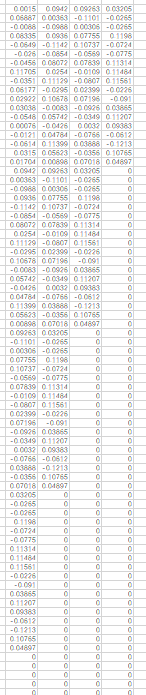
之后将第一列的数据选中复制即可。
二、 利用python脚本进行整理
对于需要反复修改的代码,如要修改学习率等,以及扩充训练集等,会影响权重的数值,每次都进行权重数据排列并不现实,因此考虑使用脚本实现数据的排列以及导入到文本文件中。
1. 将矩阵转置
对矩阵进行转置是因为我们要实现的是将数据的按列排列,而reshape实现的是是将数据排成一列,但是是按照先行后列的顺序进行排列数据的。
例如:
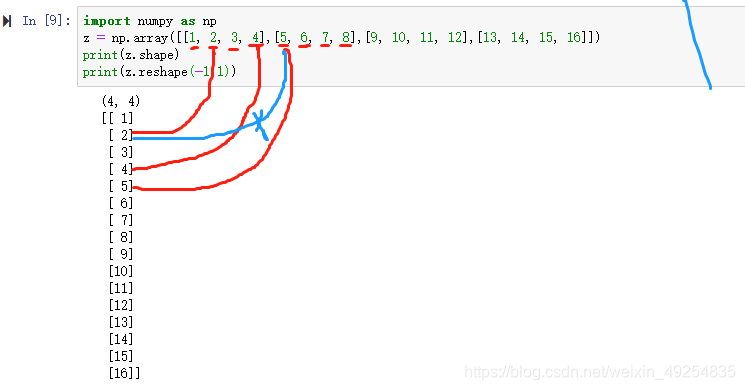
因此,若是先对数据进行转置,之后再进行reshape,就可以实现真正的按列排列。
但要注意:对于全连接层,不需要进行转置,直接进行reshape就可以实现按列排列
原因: 因为权重矩阵本来就是经过转置的:
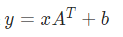
例如,代码中

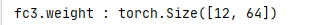
可以看出,对应权重尺寸是经过转置的,因此不需要再进行转置,直接进行reshape即可
2. 使用.reshape()方法
按照1.的解释,在实现了转置后,就可以进行使用reshape()方法将数组变成一维的形式。
reshape的具体用法见:
链接: https://blog.csdn.net/qq_29831163/article/details/90112000.
3. 数组拼接
对于少量数组的拼接可以考虑使用.append()方法;
对于大量数组的拼接可以考虑使用.concatenate()方法
相应的使用说明及对比见:
链接: https://blog.csdn.net/zyl1042635242/article/details/43162031.
4. 使用np.savetxt()方法将数据导入到文本文件中
将数组拼接好后,就是用numpy包中带有的np.savetxt()将数据导入到文本文件中。
np.savetxt()的使用说明:
numpy.savetxt(fname, X, fmt='%.18e', delimiter=' ', newline='\n', header='', footer='', comments='# ', encoding=None)[source]¶
具体的参数解释可见:
链接: https://numpy.org/doc/stable/reference/generated/numpy.savetxt.html#r672d4d5b6143-1.
这里说明np.savetxt()的使用注意事项:
- 必须保证相应的路径中必须有对应的文本文件,它不能创建文本文件,只能使用现有的文本文件
- 每次重新运行np.savetxt()会覆盖掉相应保存路径中的文本文件
最初想要实现的是将数组不断导入文本文件中,但由于np.savetxt()方法的重新覆盖的特性,无法进行追加数据。
我是看了博客:https://blog.csdn.net/qq_37974048/article/details/102686103.受到了启发,直接将数组拼接好,再进行导入是一种很好的方法。
三、 数据文本文件整理的特殊要求(sed,awk)
对于特定要求的嵌入式设备输入权重等数据,单纯每行一个数据的形式可能无法满足要求,可能要求的格式类似weight[k]=0.08765656;这时可以使用sed或awk进行处理文本文件,可以很方便地满足相应的要求。
例如:
awk '{printf "weight[%d]=%10.8f;\n",NR-1,$1;}' <data.txt >data2.txt
总结
本文主要介绍了对获得的权重文件的整理方法。对于次数较少的整理,可以靠考虑使用Excel进行处理;对于需要进行多次修改的代码,其权重的整理需要进行多次,通过脚本的实现是一种更为方便的方式。在文章的最后,介绍了sed,awk处理文本文件的强大能力,可以为数据处理提供极大的方便
参考材料:
- 链接: https://blog.csdn.net/qq_29831163/article/details/90112000..
- 链接: https://blog.csdn.net/zyl1042635242/article/details/43162031.
- 链接: https://numpy.org/doc/stable/reference/generated/numpy.savetxt.html#r672d4d5b6143-1.
- 链接: https://blog.csdn.net/qq_37974048/article/details/102686103.