#车辆路径问题
提示:这里可以添加系列文章的所有文章的目录,目录需要自己手动添加
利用Python和Gurobi求解VRPSPDTW
考虑需求动态变化的共享单车调度问题研究
提示:写完文章后,目录可以自动生成,如何生成可参考右边的帮助文档
提示:以下是本篇文章正文内容,下面案例可供参考
一、模型的建立

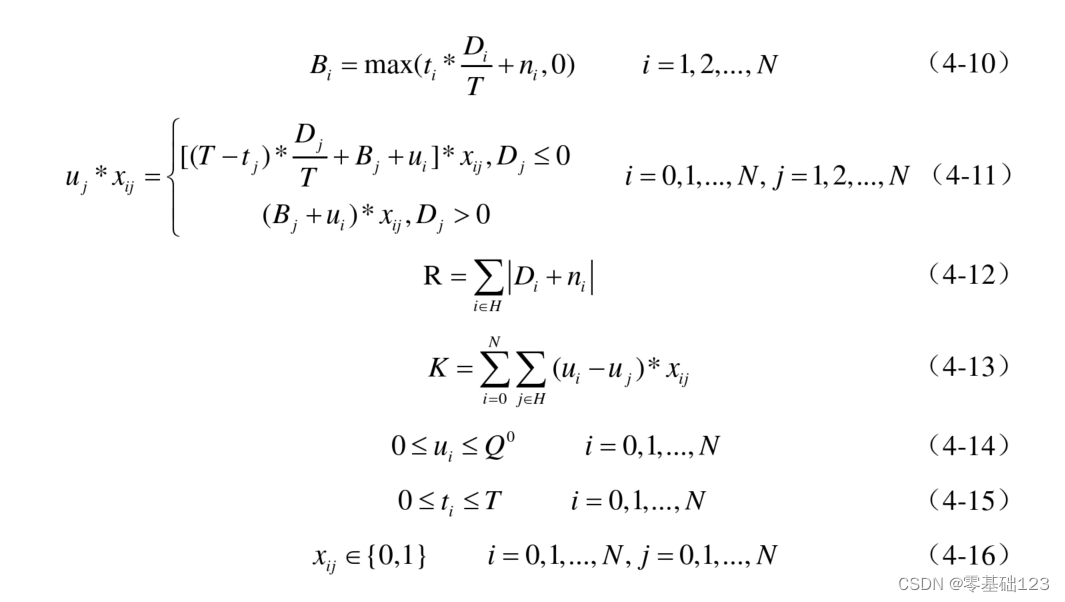


二、使用步骤
1.Gurobi代码
代码如下(示例):
import sys
import math
import os
import json
import random
from itertools import permutations
import gurobipy as gp
from gurobipy import GRB
import itertools
import pandas as pd
# 定义基本数据
data = {}
data['distance_matrix'] = [[0, 548, 776, 696, 582, 274, 502, 194, 308, 194],
[548, 0, 684, 308, 194, 502, 730, 354, 696, 742],
[776, 684, 0, 992, 878, 502, 274, 810, 468, 742],
[696, 308, 992, 0, 114, 650, 878, 502, 844, 890],
[582, 194, 878, 114, 0, 536, 764, 388, 730, 776],
[274, 502, 502, 650, 536, 0, 228, 308, 194, 240],
[502, 730, 274, 878, 764, 228, 0, 536, 194, 468],
[194, 354, 810, 502, 388, 308, 536, 0, 342, 388],
[308, 696, 468, 844, 730, 194, 194, 342, 0, 274],
[194, 742, 742, 890, 776, 240, 468, 388, 274, 0],]
data['depot'] = 0
data['demands'] = [0, 5, -5, 10, -20, -10, -20, 40, -40, 5]
data['vehicle_capacities'] = [15,]
T = 3
distList = data['distance_matrix']
Q = data['demands']
capacities = data['vehicle_capacities']
capacity = capacities[0]
n = len(distList)
dist = {(i, j): distList[i][j] for i in range(n) for j in range(n)}
# 建立模型和添加变量
m = gp.Model()
x = m.addVars(dist.keys(), obj=dist, vtype=GRB.BINARY, name='e') u = m.addVars(n, ub=capacity, name='u')
t = m.addVars(n, ub=T, name='t')
# 添加约束条件
# 装载量
pairs = [(i, j) for i in range(n) for j in range(1, n) if i != j]
for (i,j) in pairs:
if Q[j]>0:
m.addConstr(u[j]*x[i,j] == x[i,j]*((Q[j]/T)*t[j] + u[i]))
else:
m.addConstr(u[j]*x[i,j] == x[i,j]*(Q[j]-(Q[j]/T)*t[j] + u[i]))
u[0].LB = 0
u[0].UB = 0
# 时间窗
for (i,j) in pairs:
m.addConstr(t[j] >= (dist[i,j]/750)+t[i]-(1-x[i, j])*T)
t[0].LB = 0
t[0].UB = 0
# 进出平衡
m.addConstrs(x.sum(i, '*') == x.sum('*',i) for i in range(n))
# 不出现自己到自己的情况
m.addConstrs(x[i,i] == 0 for i in range(n))
# 所有点最多被访问一次
m.addConstrs(x.sum(i, '*') <= 1 for i in range(1, n))
m.addConstrs(x.sum('*', i) <= 1 for i in range(1, n))
AllNodesVisited={i: gp.quicksum(x[j,i] for j in range(n) if i!=j) for i in range(1,n)} # (2.2)
m.addConstrs(AllNodesVisited[i]<=1 for i in range(1,n))
# 至少有1辆调度车进行调度
m.addConstr(x.sum(0, '*') >= 1)
m.addConstr(x.sum('*', 0) >= 1)
# 设置目标函数
total_satisfied = gp.quicksum((u[i]-u[j])*x[i,j] for j in [2,4,5,6,8] for i in range(n))
total_unzero = gp.quicksum(Q[i] for i in [2,4,5,6,8])
total_distri = gp.quicksum(u[i] for i in range(n))
total_time = gp.quicksum(t[i] for i in range(n))
totaldist = gp.quicksum(x[i,j]*dist[i,j] for i in range(n) for j in range(n))
m.setObjective(totaldist*0.01+(x.sum(0,'*')*40)+(-total_satisfied-total_unzero)*15,GRB.MINIMIZ
E)
# 结果计算
m.optimize()
2.遗传算法代码
代码如下(示例):
附录 C
89
distance.append(calDist(dataDict['NodeCoor'][eachRoute[j-1]],dataDict['NodeCoor'][eachRoute[j]]))
#distance_of_all_point.append(distance(y[len(y)-1],start_point_0))
all_route_distance.append(distance)
for z in range(len(distance)):
route_time.append(distance[z]/dataDict['Velocity'])
arrive_time = list(np.cumsum(route_time))
for m in range(len(arrive_time)):
if arrive_time[m] > dataDict['TimeWindow']:
arrive_time[m] = np.nan
all_arrive_time.append(arrive_time)
for p in range(len(arrive_time)-1):
if np.isnan(arrive_time[p]):
scheduling_requirements.append(np.nan)
else:
if
dataDict['InitialValue'][eachRoute[p+1]]+dataDict['DemandRate'][eachRoute[p+1]]*arrive_time[p]>
0:
if dataDict['DemandRate'][eachRoute[p+1]]>0:
scheduling_requirements.append(dataDict['InitialValue'][eachRoute[p+1]]+dataDict['DemandRate'][
eachRoute[p+1]]*arrive_time[p])
else:
scheduling_requirements.append(dataDict['InitialValue'][eachRoute[p+1]]+dataDict['DemandRate'][
eachRoute[p+1]]*arrive_time[p]+(1-arrive_time[p])*dataDict['DemandRate'][eachRoute[p+1]])
else:
scheduling_requirements.append((1-arrive_time[p])*dataDict['DemandRate'][eachRoute[p+1]])
for t in range(len(scheduling_requirements)):
if not np.isnan(scheduling_requirements[t]):
scheduling_requirements[t] = round(scheduling_requirements[t])
#scheduling_requirements = [round(u) for u in scheduling_requirements]
all_route_scheduling_quantity.append(scheduling_requirements)
return all_route_distance,all_arrive_time,all_route_scheduling_quantity
# 调度车离开各区域时的装载量
def all_truck_loading_leave(routes,dataDict=dataDict):
all_truck_loading_leave = []
arriveTime = quantityDistanceArriveTime(routes)[2]
for t in range(len(arriveTime)):
truck_loading = []
if np.isnan(arriveTime[t][0]): 87
import numpy as np
import matplotlib.pyplot as plt
from deap import base, tools, creator, algorithms
import random
import pandas as pd
params = {
'font.family': 'serif',
'figure.dpi': 300,
'savefig.dpi': 300,
'font.size': 12,
'legend.fontsize': 'small'
}
plt.rcParams.update(params)
from copy import deepcopy
# 问题定义
creator.create('FitnessMin', base.Fitness, weights=(-1.0,)) # 最小化问题
# 给个体一个routes属性用来记录其表示的路线
creator.create('Individual', list, fitness=creator.FitnessMin)
# 用字典存储参数
dataDict = {}
# 节点坐标,节点0是配送中心的坐标
dataDict['NodeCoor']=pd.read_excel('cluster_center_2hour.xlsx',sheet_name='Sheet1')['number'].toli
st()
# 将配送中心的需求设置为0
dataDict['Demand'] = pd.read_excel('cluster_center_2hour.xlsx',sheet_name='Sheet1')['需求'].tolist()
dataDict['MaxLoad'] = 20
#dataDict['ServiceTime'] = 1/150
dataDict['DemandRate']=[x/2 for x in
pd.read_excel('cluster_center_2hour.xlsx',sheet_name='Sheet1')['需求'].tolist()]
dataDict['Velocity'] = 20
dataDict['InitialValue'] = pd.read_excel('cluster_center_2hour.xlsx',sheet_name='Sheet1')['初始车辆
(round)'].tolist()
dataDict['TimeWindow'] = 2
dataDict['SetUpCost'] = 80
dataDict['RunningCost'] = 2
for m in range(len(begin)):
real_number_of_dispatch = list(map(lambda x: x[0]-x[1], zip(leave[m], begin[m])))
all_real_number_of_dispatch.append(real_number_of_dispatch)
return all_real_number_of_dispatch
# 实际调入量的总数
def all_real_number_of_dispatch_sum(routes):
a = all_real_number_of_dispatch(routes)
for i in a:
for z in range(len(i)):
if np.isnan(i[z]):
i[z] = 0
else:
if i[z] > 0:
i[z] = 0
all_real_number_of_dispatch_sum = [sum(i) for i in a]
return all_real_number_of_dispatch_sum
# 未满足的单车需求量
def all_unsatisfied(routes):
allUnsatisfied = []
a = all_real_number_of_dispatch(routes)
routesNum = []
for _ in routes:
x = []
for b in _:
if b != 0:
x.append(b)
routesNum.append(x)
routesDemand = []
for c in routesNum:
y = []
for d in c:
y.append(total_demand[d])
routesDemand.append(y)
for i in range(len(a)):
for k in range(len(a[i])):
if np.isnan(a[i][k]):
a[i][k] = 0
truck_loading.append(np.nan)
else:
if arriveTime[t][0]<0:
truck_loading.append(0)
else:
if arriveTime[t][0]>dataDict['MaxLoad']:
truck_loading.append(dataDict['MaxLoad'])
else:
truck_loading.append(arriveTime[t][0])
if len(arriveTime[t]) == 1:
all_truck_loading_leave.append(truck_loading)
else:
for i in range(len(arriveTime[t])-1):
if np.isnan(arriveTime[t][i+1]):
truck_loading.append(np.nan)
else:
if truck_loading[i]+arriveTime[t][i+1]<0:
truck_loading.append(0)
else:
if truck_loading[i]+arriveTime[t][i+1]<dataDict['MaxLoad']:
truck_loading.append(truck_loading[i]+arriveTime[t][i+1])
else:
truck_loading.append(dataDict['MaxLoad'])
all_truck_loading_leave.append(truck_loading)
return all_truck_loading_leave
# 调度车到达各区域时的装载量
def all_truck_loading_begin(routes):
all_truck_loading_begin = []
leave = all_truck_loading_leave(routes)
for r in leave:
v = r[:]
v.insert(0,0)
f = v[0:-1]
all_truck_loading_begin.append(f)
return all_truck_loading_begin
# 实际各区域的调度量
def all_real_number_of_dispatch(routes):
all_real_number_of_dispatch = []
leave = all_truck_loading_leave(routes)
begin = all_truck_loading_begin(routes)
dataDict['PenaltyCost'] = 4
line = pd.read_csv('distance.csv')['line'].tolist()
distance_km = pd.read_csv('distance.csv')['distance(km)'].tolist()
distance_value = dict(zip(line,distance_km))
#生成个体
def genInd(dataDict = dataDict):
n Customer = len(dataDict['NodeCoor']) - 1 # 顾客数量
perm = np.random.permutation(nCustomer) + 1 # 生成顾客的随机排列,注意顾客编号为1--n
permSlice = []
a = random.sample([i+1 for i in range(len(perm)-1)],np.random.randint(1,len(perm)))
a.sort()
routePoint = [0]+a+[len(perm)]
for i,j in zip(routePoint[0::], routePoint[1::]):
permSlice.append(perm[i:j].tolist())
# 将路线片段合并为染色体
ind = [0]
for eachRoute in permSlice:
ind = ind + eachRoute + [0]
return ind
# 染色体解码
def decodeInd(ind):
indCopy = np.array(deepcopy(ind))
idxList = list(range(len(indCopy)))
zeroIdx = np.asarray(idxList)[indCopy == 0]
routes = []
for i,j in zip(zeroIdx[0::], zeroIdx[1::]):
routes.append(ind[i:j]+[0])
return routes
# 求得路径长度,到达区域时间和到达每个区域的调度需求
def quantityDistanceArriveTime(routes,dataDict=dataDict):
all_route_scheduling_quantity = []
all_route_distance = []
all_arrive_time = []
for eachRoute in routes:
distance = []
route_time = []
scheduling_requirements = []
for j in range(1,len(eachRoute)):
totalDistance = 0
if np.nan in quantityDistanceArriveTime([eachRoute])[1][0]:
eachRoute =
eachRoute[0:quantityDistanceArriveTime([eachRoute])[1][0].index(np.nan)+1]+[0]
else:
eachRoute = eachRoute
for i,j in zip(eachRoute[0::], eachRoute[1::]):
totalDistance += calDist(dataDict['NodeCoor'][i], dataDict['NodeCoor'][j])
AllDistance.append(totalDistance)
return sum(AllDistance),np.var(AllDistance)
# 评价函数
def evaluate(ind):
routes = decodeInd(ind)
totalDistanceCost = calRouteLen(routes)[0]*dataDict['RunningCost']
totalSetUpCost = len(routes)*dataDict['SetUpCost']
return (totalDistanceCost +
loadPenalty(routes)*dataDict['PenaltyCost']+totalSetUpCost),#+calRouteLen(routes)[1]*5),
# 交叉
def genChild(ind1, ind2, nTrail=5,dataDict=dataDict):
routes1 = decodeInd(ind1)
numSubroute1 = len(routes1)
subroute1 = routes1[np.random.randint(0, numSubroute1)]
unvisited = set(ind1) - set(subroute1)
unvisitedPerm = [digit for digit in ind2 if digit in unvisited]
bestRoute = None
bestFit = np.inf
if numSubroute1 < 3:
breakSubroute = []
breakSubroute.append([0]+unvisitedPerm+[0])
breakSubroute.append(subroute1)
routesFit =
cal RouteLen(breakSubroute)[0]*dataDict['RunningCost']+loadPenalty(breakSubroute)*dataDict['Pe
naltyCost']+len(breakSubroute)*dataDict['SetUpCost']#+calRouteLen(breakSubroute)[1]*5
if routesFit < bestFit:
bestRoute = breakSubroute
bestFit = routesFit
else:
for _ in range(nTrail):
breakPos = [0]+random.sample(range(1,len(unvisitedPerm)),numSubroute1-2)
breakPos.sort()
not_satisfied = list(map(lambda x: x[0]-x[1], zip(routesDemand[i], a[i])))
for j in range(len(not_satisfied)):
if not_satisfied[j] > 0:
not_satisfied[j] = 0
cost = sum(not_satisfied)
allUnsatisfied.append(cost)
return allUnsatisfied
# 各区域的总调度需求
def total_demand(dataDict=dataDict):
totalDemand = []
for i in range(len(dataDict['Demand'])):
totalDemand.append(dataDict['InitialValue'][i]+dataDict['Demand'][i])
return totalDemand
# 各需求点之间的距离
def calDist(pos1, pos2):
num1 = dataDict['NodeCoor'].index(pos1)
num2 = dataDict['NodeCoor'].index(pos2)
distance = distance_value.get("({}, {})".format(num1,num2))
return distance
# 各区域未满足量
def loadPenalty(routes):
penalty = 0
penalty = abs(sum(all_unsatisfied(routes)))
return penalty
# 到达各区域的时间
def calArriveTime(route, dataDict = dataDict):
arrivalTime = 0
arrivalTimeList = []
for i in range(0, len(route)-2):
arrivalTime += calDist(dataDict['NodeCoor'][route[i]],
dataDict['NodeCoor'][route[i+1]])/dataDict['Velocity']
arrivalTimeList.append(arrivalTime)
return arrivalTime,arrivalTimeList
# 路径总距离计算
def calRouteLen(routes,dataDict=dataDict):
AllDistance = []
for eachRoute in routes:
breakSubroute = []
for u,v in zip(breakPos[0::], breakPos[1::]):
breakSubroute.append([0]+unvisitedPerm[u:v]+[0])
breakSubroute.append([0]+unvisitedPerm[v:]+[0])
breakSubroute.append(subroute1)
routesFit =
calRouteLen(breakSubroute)[0]*dataDict['RunningCost']+loadPenalty(breakSubroute)*dataDict['Pe
naltyCost']+len(breakSubroute)*dataDict['SetUpCost']#+calRouteLen(breakSubroute)[1]*5
if routesFit < bestFit:
bestRoute = breakSubroute
bestFit = routesFit
child = []
for eachRoute in bestRoute:
child += eachRoute[:-1]
return child+[0]
def crossover(ind1, ind2):
''交叉操作'''
ind1[:], ind2[:] = genChild(ind1, ind2), genChild(ind2, ind1)
return ind1, ind2
# 变异
def opt(route,dataDict=dataDict, k=2):
n Cities = len(route)
optimizedRoute = route
min Distance =
calRouteLen([route])[0]*dataDict['RunningCost']+loadPenalty([route])*dataDict['PenaltyCost']
for i in range(1,nCities-2):
for j in range(i+k, nCities):
if j-i == 1:
continue
reversedRoute = route[:i]+route[i:j][::-1]+route[j:]
reversedRouteDist =
calRouteLen([reversedRoute])[0]*dataDict['RunningCost']+loadPenalty([reversedRoute])*dataDict['
PenaltyCost']
if reversedRouteDist < minDistance:
min Distance = reversedRouteDist
optimizedRoute = reversedRoute
return optimizedRoute
def mutate(ind):
routes = decodeInd(ind)
optimizedAssembly = []
for eachRoute in routes: 附录 C
95
optimizedRoute = opt(eachRoute)
optimizedAssembly.append(optimizedRoute)
child = []
for eachRoute in optimizedAssembly:
child += eachRoute[:-1]
ind[:] = child+[0]
return ind,
total_demand = total_demand()
# 注册遗传算法操作
toolbox = base.Toolbox()
toolbox.register('individual', tools.initIterate, creator.Individual, genInd)
toolbox.register('population', tools.initRepeat, list, toolbox.individual)
toolbox.register('evaluate', evaluate)
toolbox.register('select', tools.selTournament, tournsize=2)
toolbox.register('mate', crossover)
toolbox.register('mutate', mutate)
# 生成初始族群
toolbox.popSize = 200
pop = toolbox.population(toolbox.popSize)
# 记录迭代数据
stats=tools.Statistics(key=lambda ind: ind.fitness.values)
stats.register('min', np.min)
stats.register('avg', np.mean)
stats.register('std', np.std)
hallOfFame = tools.HallOfFame(maxsize=1)
# 遗传算法参数
toolbox.ngen = 200
toolbox.cxpb = 0.8
toolbox.mutpb = 0.1
# 算法主程序
pop,logbook=algorithms.eaMuPlusLambda(pop, toolbox, mu=toolbox.popSize,
lambda_=toolbox.popSize,cxpb=toolbox.cxpb,
mutpb=toolbox.mutpb, ngen=toolbox.ngen ,stats=stats, halloffame=hallOfFame, verbose=True)