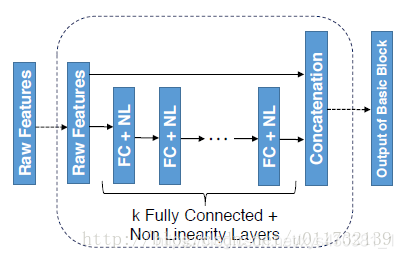
一、如何理解concat和add的方式融合特征
在各个网络模型中,ResNet,FPN等采用的element-wise add来融合特征,而DenseNet等则采用concat来融合特征。那add与concat形式有什么不同呢?事实上两者都可以理解为整合特征图信息。只不过concat比较直观,而add理解起来比较生涩。
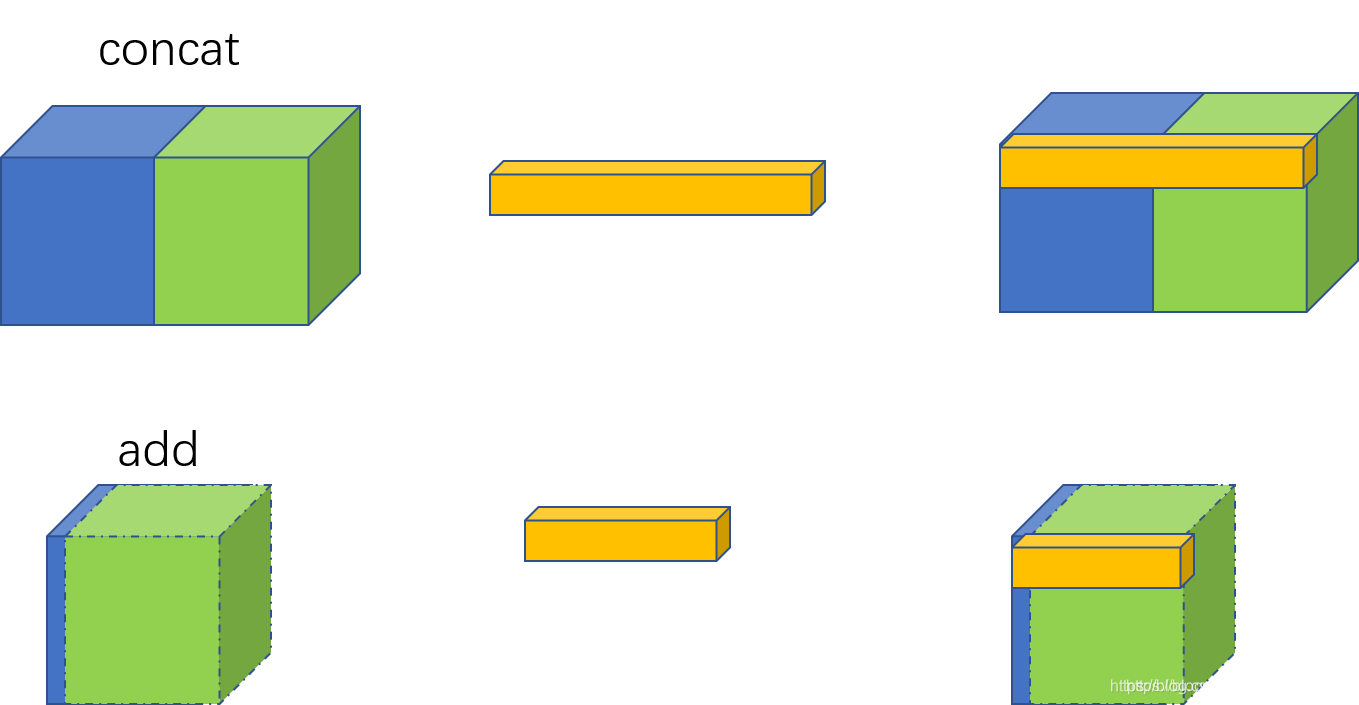
从图中可以发现,
-
concat是通道数的增加;
- add是特征图相加,通道数不变
你可以这么理解,add是描述图像的特征下的信息量增多了,但是描述图像的维度本身并没有增加,只是每一维下的信息量在增加,这显然是对最终的图像的分类是有益的。而concatenate是通道数的合并,也就是说描述图像本身的特征数(通道数)增加了,而每一特征下的信息是没有增加。
concat每个通道对应着对应的卷积核。 而add形式则将对应的特征图相加,再进行下一步卷积操作,相当于加了一个先验:对应通道的特征图语义类似,从而对应的特征图共享一个卷积核(对于两路输入来说,如果是通道数相同且后面带卷积的话,add等价于concat之后对应通道共享同一个卷积核)。
因此add可以认为是特殊的concat形式。但是add的计算量要比concat的计算量小得多。
另解释:
对于两路输入来说,如果是通道数相同且后面带卷积的话,add等价于concat之后对应通道共享同一个卷积核。下面具体用式子解释一下。由于每个输出通道的卷积核是独立的,我们可以只看单个通道的输出。假设两路输入的通道分别为X1, X2, …, Xc和Y1, Y2, …, Yc。那么concat的单个输出通道为(*表示卷积):
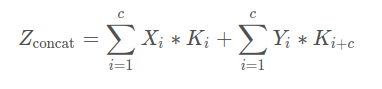
而add的单个输出通道为:
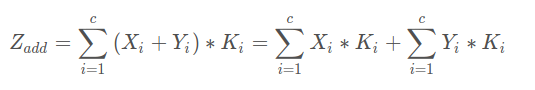
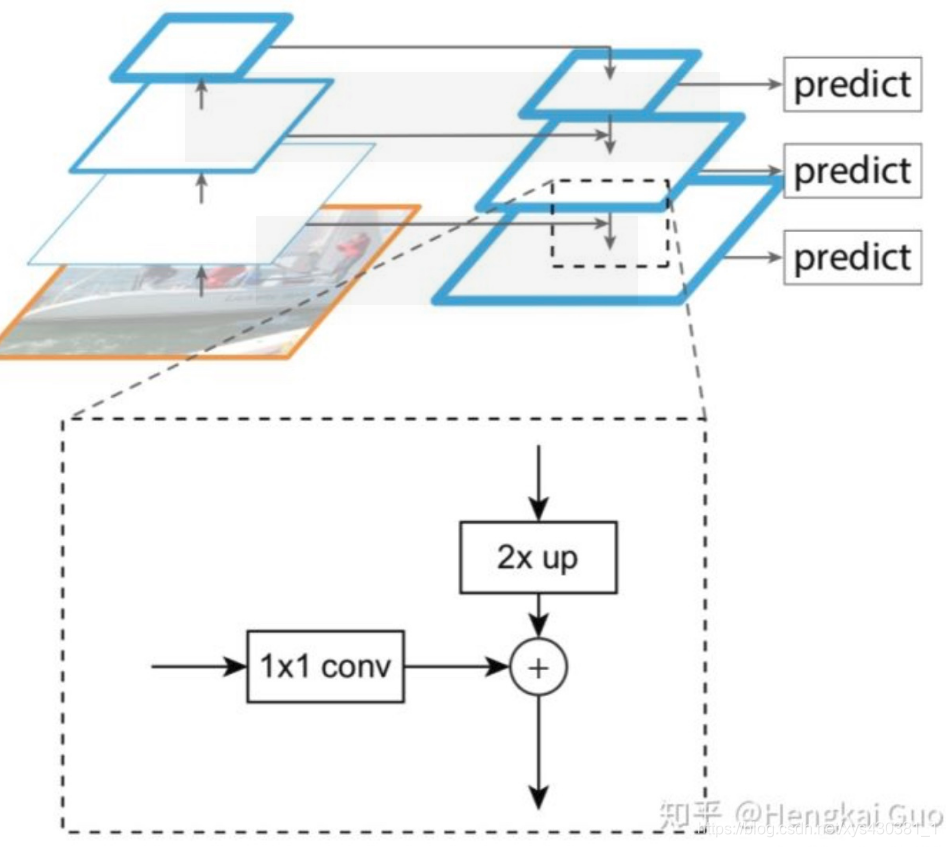
因此add相当于加了一种prior,当两路输入可以具有“对应通道的特征图语义类似”(可能不太严谨)的性质的时候,可以用add来替代concat,这样更节省参数和计算量(concat是add的2倍)。FPN[1]里的金字塔,是希望把分辨率最小但语义最强的特征图增加分辨率,从性质上是可以用add的。如果用concat,因为分辨率小的特征通道数更多,计算量是一笔不少的开销
Resnet是做值的叠加,通道数是不变的,DenseNet是做通道的合并。你可以这么理解,add是描述图像的特征下的信息量增多了,但是描述图像的维度本身并没有增加,只是每一维下的信息量在增加,这显然是对最终的图像的分类是有益的。而concatenate是通道数的合并,也就是说描述图像本身的特征增加了,而每一特征下的信息是没有增加。
参考文章:https://blog.csdn.net/u012193416/article/details/79479935
通过keras代码,观察了add对参数的影响,以及concat操作数组的结果。
二、concat实操
Concat层解析
https://blog.csdn.net/weixin_36608043/article/details/82859673
在channel维度上进行拼接,在channel维度上的拼接分成无BN层和有BN层。
(1)无BN层:直接将deconvolution layer 和convolution layer concat。实验结果表明,该方式取得的结果精度较低,低于原有的VGG模型,分析主要的原因是漏检非常严重,原因应该是concat连接的两层参数不在同一个层级,类似BN层用在eltwise层上。
(2)有BN层:在deconvolution layer 和convolution layer 后面加batchnorm和scale层(BN)后再concat。实验结果表明,该方式取得了比原有VGG模型更好的检测效果(表中的迭代次数还没有完哦),增加了2%的精度,但是速度上慢了一些。
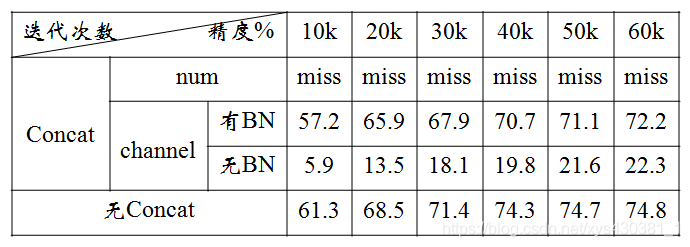
总结:concat层多用于利用不同尺度特征图的语义信息,将其以增加channel的方式实现较好的性能,但往往应该在BN之后再concat才会发挥它的作用,而在num维度的拼接较多使用在多任务问题上,将在后续的博客中介绍,总之concat层被广泛运用在工程研究中。
三、concat与add实例
3.1 Densenet
https://blog.csdn.net/Gentleman_Qin/article/details/84638700
与inception 的加宽网络结构以及ResNet的加深网络结构不同,DenseNet着重于对每一层feature maps的重复利用。在一个Dense block中,每一个卷积层的输入都是前几个卷积层输出的concatenation(拼接),这样即每一次都结合了前面所得到的特征,来得到后续的特征。
但是,其显存占用率高的缺点也比较明显(因为concatenation,不过好在后续有了解决方法:(论文)Memory-Efficient Implementation of DenseNets)。
DenseNet优势:
(1)解决了深层网络的梯度消失问题
(2)加强了特征的传播
(3)鼓励特征重用
(4)减少了模型参数
(5)能够减少小样本的过拟合问题
DensNet缺点:
(1)非常消耗显存
Densnet基本结构
DenseNet的网络基本结构如上图所示,主要包含DenseBlock和transition layer两个组成模块。其中Dense Block为稠密连接的highway的模块,transition layer为相邻2个Dense Block中的那部分。

DenseBlock结构
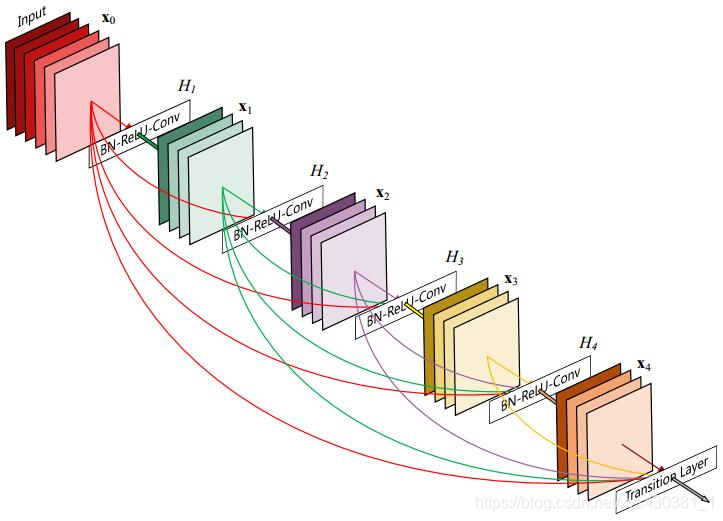
上图是一个详细的Dense Block模块,其中
- 层数为5,即具有5个BN+Relu+Conv(3*3)这样的layer,
- 网络增长率为4,简单的说就是每一个layer输出的feature map的维度为4。
- 由于DenseNet的每一个Dense Block模块都利用到了该模块中前面所有层的信息,即每一个layer都和前面的layer有highway的稠密连接。假设一个具有L层的网络,那么highway稠密连接数目为L*(L+1)/2。
和Resnet不同的是,这里的连接方式得到的feature map做的是concat操作,而resnet中做的是elementwise操作。
DenseNet降维
highway的稠密连接方式具有诸多的优势,增加了梯度的传递,特征得到了重用,甚至减少了在小样本数据上的过拟合。但是随之产生2个缺点:
(1)DenseBlock靠后面的层的输入channel过大—每层开始的时候引入Bottleneck:
这里假设第L层输出K个feature map,即网络增长率为K,那么第L层的输入为K0+K*(L-1),其中K0为输入层的维度。也就是说,对于Dense Block模块中每一层layer的输入feature map时随着层数递增的,每次递增为K,即网络增长率。那么这样随着Dense Block模块深度的加深,后面的层的输入feature map的维度是很大的。
为了解决这个问题,在DenseNet-B网络中,在Dense Block每一层开始的时候加入了Bottleneck 单元,即1x1卷积进行降维,被降到4K维(K为增长率)。
(2) DenseBlock模块的输出维度很大—transition layer模块中加入1*1卷积降维
每一个DenseBlock模块的输出维度是很大的,假设一个L层的Dense Block模块,假设其中已经加入了Bottleneck 单元,那么输出的维度为,第1层的维度+第2层的维度+第3层的维度+****第L层的维度,加了Bottleneck单元后每层的输出维度为4K,那么最终Dense Block模块的输出维度为4KL。随着层数L的增加,最终输出的feature map的维度也是一个很大的数。
为了解决这个问题,在transition layer模块中加入了11卷积做降维。 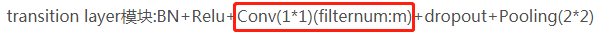

其中,DenseNet-B在原始DenseNet的基础上,在Dense Block模块的每一层都加入了1*1卷积,使得将每一个layer输入的feature map都降为到4k的维度,大大的减少了计算量。
DenseNet-BC在DenseNet-B的基础上,在transitionlayer模块中加入了压缩率θ参数,论文中将θ设置为0.5,这样通过1*1卷积,将上一个Dense Block模块的输出feature map维度减少一半。
附:tensorflow下实现DenseNet对数据集cifar-10的图像分类
https://blog.csdn.net/k87974/article/details/80352315
3.2 Feature-Fused SSD: Fast Detection for Small Objects
https://blog.csdn.net/zhangjunhit/article/details/78031452
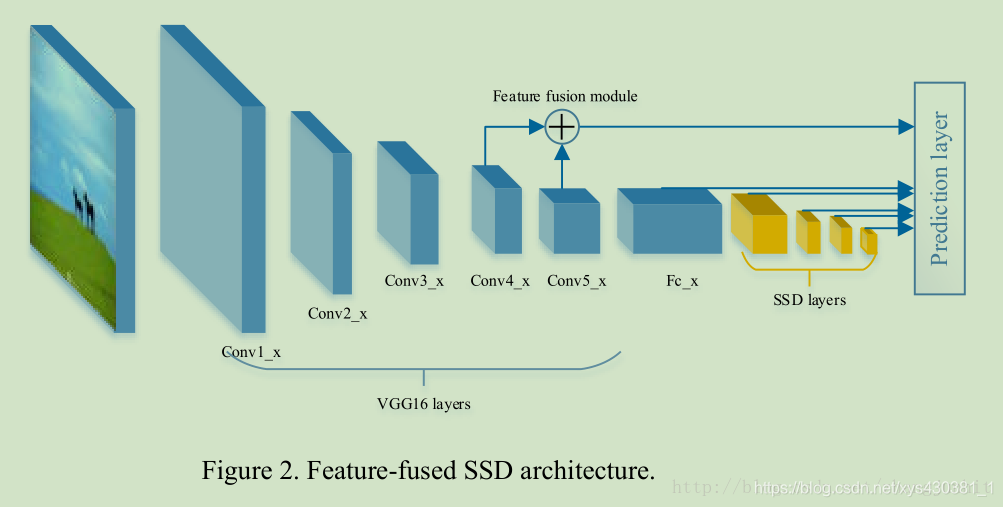
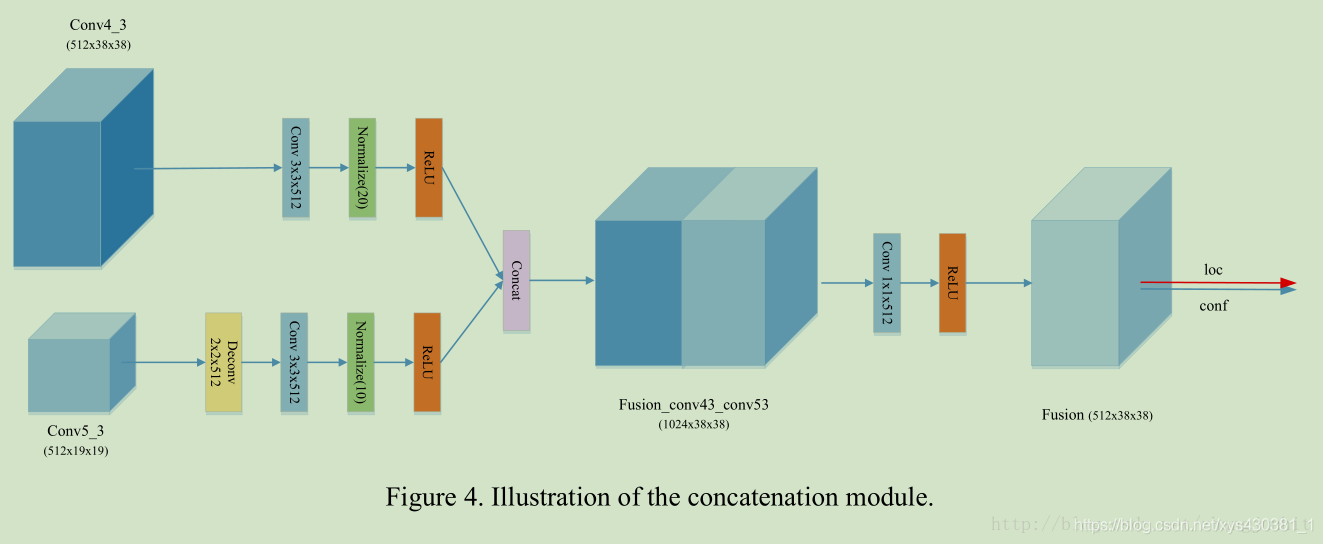
这里我们尝试了两种融合策略:concat和add
Concatenation Module
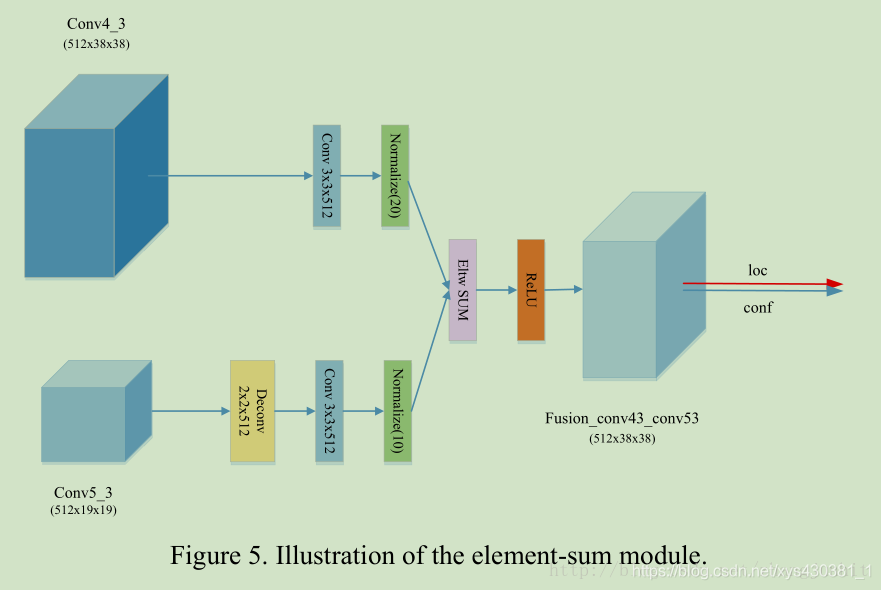
Element-Sum Module
3.3 Scene Classification Based on Two-Stage Deep Feature Fusion
https://www.cnblogs.com/blog4ljy/p/8697313.html
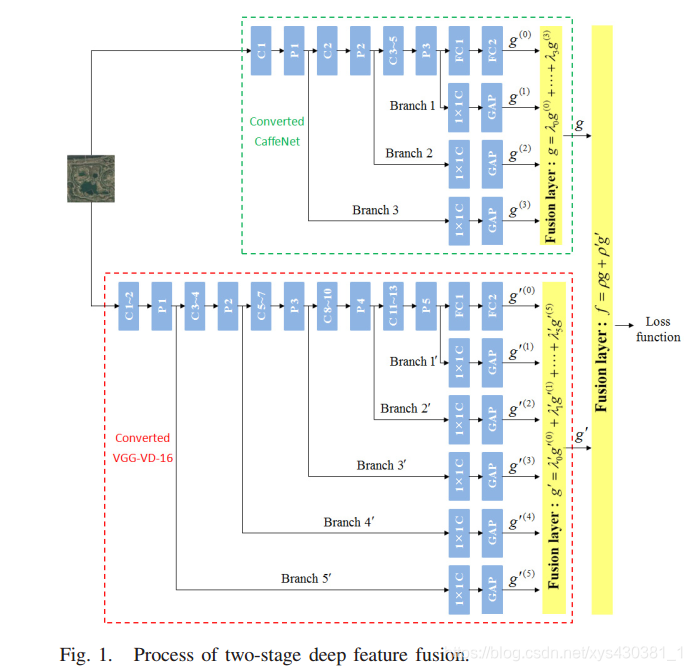
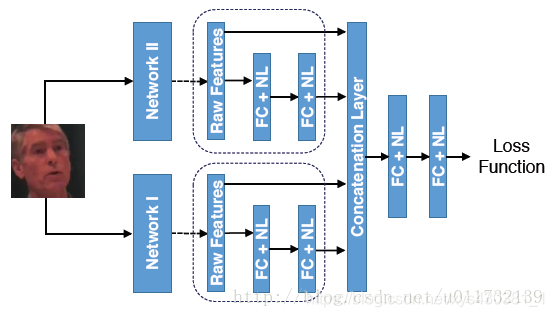
3.4 Deep Heterogeneous Feature Fusion for Template-Based Face Recognition
https://blog.csdn.net/u011732139/article/details/69943954