分析一个术语,要先从名称入手
倒排索引,英文原名Inverted index,大概因为 Invert 有颠倒的意思,就被翻译成了倒排。但是倒排这个名称很容易让人理解为从A-Z颠倒成Z-A。个人觉得翻译成反向索引更好。。。
倒排索引是区别于正排索引(forward index)来说的。
理论基础:首先文档是有许多的单词组成的,其中每个单词也可以在同一个文档中重复出现很多次,当然,同一个单词也可以出现在不同的文档中。
正排索引(forward index):
正排索引是从文档角度来找其中的单词,表示每个文档(用文档ID标识)都含有哪些单词,以及每个单词出现了多少次(词频)及其出现位置(相对于文档首部的偏移量)。所以每次搜索都是遍历所有文章。
倒排索引(inverted index):
倒排索引是从单词角度找文档,标识每个单词分别在那些文档中出现(文档ID),以及在各自的文档中每个单词分别出现了多少次(词频)及其出现位置(相对于该文档首部的偏移量)。
简单记为:
- 正排索引:文档 ---> 单词
- 倒排索引:单词 ---> 文档
倒排索引有着广泛的应用场景,比如搜索引擎、大规模数据库索引、文档检索、多媒体检索/信息检索领域等等。总之,倒排索引在检索领域是很重要的一种索引机制。
倒排索引由两个部分组成
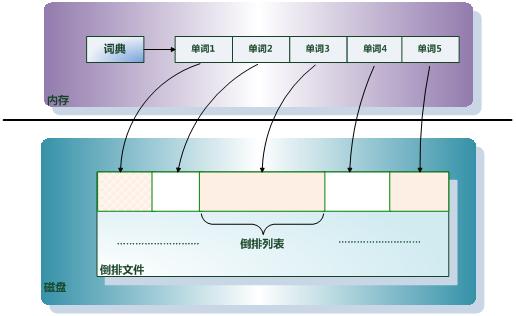
倒排文件
所有单词的倒排列表顺序的存储在磁盘的某个文件里,这个文件即被称为倒排文件,倒排文件是存储倒排索引的物理文件。
单词词典
单词词典是由文档集合中出现过的所有单词构成的字符串集合,单词词典内每条索引项记载单词本身的一些信息以及指向“倒排列表”的指针。
单词词典是倒排索引中非常重要的组成部分,它是用来维护文档集合中所有单词的相关信息,同时用来记载某个单词对应的倒排列表在倒排文件中的位置信息。在支持搜索时,根据用户的查询词,去单词词典里查询,就能够获得相应的倒排列表。
对于一个规模很大的文档集合来说,可能包含了几十万甚至上百万的不同单词,
快速定位某个单词直接决定搜索的响应速度,所以我们需要很高效的数据结构对单词词典进行构建和查找。
常用的数据结构包含哈希加链表和树形词典结构。
------------------
搜索的过程:
当用户输入任意的词条时,
- 首先对用户输入的数据进行分词,得到用户要搜索的所有词条。
- 然后拿着这些词条去倒排索引列表中进行匹配。找到这些词条就能找到包含这些词条的所有文档的编号。
- 最后根据这些编号去文档列表中找到文档
创建倒排索引,分为以下几步:
- 创建文档列表:lucene首先对原始文档数据进行编号(DocID),形成列表,就是一个文档列表
- 创建倒排索引列表:然后对文档中数据进行分词,得到词条。对词条进行编号,以词条创建索引。然后记录下包含该词条的所有文档编号(及其它信息)。
下面举个例子
Elasticsearch 使用一种称为 倒排索引 的结构,它适用于快速的全文搜索。一个倒排索引由文档中所有不重复词的列表构成,对于其中每个词,有一个包含它的文档列表。
例如,假设我们有两个文档,每个文档的 content 域包含如下内容:
- Doc_1:我爱北京天安门
- Doc_2:我爱代码,代码爱我。
为了创建倒排索引,我们首先将每个文档的 content 域拆分成单独的 词(我们称它为 词条 或 tokens),创建一个包含所有不重复词条的排序列表,然后列出每个词条出现在哪个文档。结果如下所示:
1:分词
Doc_1:[我][爱][北京][天安门]
Doc_2:[我][爱][代码],[代码][爱][我]。
| 分词 |
我 |
爱 |
代码 |
代码 |
爱 |
我 |
| 下标 |
1 |
2 |
3 |
4 |
5 |
6 |
2:创建文档列表
| 文档编号 |
文档内容 |
| 1 |
我爱北京天安门 |
| 2 |
我爱代码,代码爱我 |
3:创建倒排索引列表
| 关键词 |
文档号 |
| 我 |
1,2 |
| 爱 |
1,2 |
| 北京 |
1 |
| 天安门 |
1 |
代码 |
2 |
通常仅知道关键词在哪些文章中出现还不够,我们还需要知道关键词在文章中出现次数和出现的位置,通常有两种位置:
- 字符位置,即记录该词是文章中第几个字符(优点是关键词亮显时定位快);
- 关键词位置,先把文章进行分词,然后记录该词是文章中第几个关键词(优点是节约索引空间、词组(phase)查询快),lucene中记录的就是这种方法。
lucene的实现
(ElasticSearch底层使用的lucenne)
实现时,lucene将上面三列分别作为词典文件(Term Dictionary)、频率文件(frequencies)、位置文件 (positions)保存。其中词典文件不仅保存有每个关键词,还保留了指向频率文件和位置文件的指针,通过指针可以找到该关键字的频率信息和位置信息。
Lucene中使用了field的概念,用于表达信息所在位置(如标题中,文章中,url中),在建索引中,该field信息也记录在词典文件中,每个关键词都有一个field信息(因为每个关键字一定属于一个或多个field)。
加上“出现频率”和“出现位置”信息后,我们的索引结构变为:
现在,如果我们想搜索 “代码“,我们只需要查找包含每个词条的文档:
| 关键词 |
文章号 |
出现频率 |
出现位置 |
| 我 |
1,2 |
1,2 |
1,[1,6] |
| 爱 |
1,2 |
1,2 |
2,[2,5] |
| 北京 |
1 |
1 |
3 |
| 天安门 |
1 |
1 |
4 |
| 代码 |
2 |
2 |
[3,4] |
以“爱”这个词为例:“爱”在文章一中出现了1次,文章二中出现了2次,它的出现位置为 1和[1,6]
这表示什么呢?
在文章一中出现了1次,那么 下标2 就表示“爱”在文章1中出现的位置。
在文章二中出现了2次,那么排除文章一中出现的一次,剩下的两个位置[2,5]就表示“爱”是在文章二下标为[2,5]处。
以上就是lucene索引结构中最核心的部分。我们注意到关键字是按字符顺序排列的(lucene没有使用B树结构),因此lucene可以用二分搜索算法快速定位关键词。
为什么要建立索引?
下面我们可以通过对该索引的查询来解释一下为什么要建立索引。
假设要查询单词 “爱”,普通的顺序匹配算法,不建索引,对所有文章的内容进行字符串匹配,这个过程将会相当缓慢,当文章数目很大时,时间往往是无法忍受的。
lucene先对词典二元查找、找到该词,通过指向频率文件的指针读出所有文章号,然后返回结果。词典通常非常小,因而,整个过程的时间是毫秒级的。
参考:
https://www.zhihu.com/question/23202010
https://www.elastic.co/guide/cn/elasticsearch/guide/current/inverted-index.html
https://blog.csdn.net/u011239443/article/details/60604017
http://www.cnblogs.com/zlslch/p/6440114.html