cuda与cpu高斯列主消元求解线性方程组速度比较
最近看了看cuda上面用c语言进行的编程,踩了很多的坑,在这里记录一下。
完整程序已上传:https://download.csdn.net/download/qq_41910473/12917838
配置环境:VS2017 cuda10.0 Runtime,cpu:i5 8600K ,显卡:GTX 1060
求解公式是:A*x = b, A: N*N方阵,x:N维列向量,b: N维列向量,求解未知量x向量。
求解方法:分别在gpu与cpu上进行高斯列主消元,比较运行的时间。
求解的过程分为三步:
1、求最大值进行行交换。
2、消元。
3、回代。
程序分为两部分,第一部分用cuda实现,第二部分在cpu实现,并分别统计运行时间。最终得出结论当矩阵维度大于1000时GPU运行速度快于CPU,而当矩阵维度小于等于1000时GPU运行速度慢于CPU。程序中有很多地方可以进行优化例如使用共享内存、线程块的分配,由于题主只是证明CUDA在解线性方程可以进行加速所以就没有进行更细节的优化。
最终得出的结论:数据规模较小的话,例如:100*100线性方程组GPU并行求解速度远低于CPU迭代求解速度。数据规模较大,例如:2000*2000的线性方程组求解在GPU上可以得到显著的加速效果。
cuda程序:
__global__ void GaussKernelA(),单线程执行该函数来求解第k步时第k列的最大值并把该最大值所在的行交换到第k行。
__global__ void GaussKernelA(double *augmentedMatrixGPU, int k, int n) { //K :消元第k步,n:增广矩阵的行数
int i = blockIdx.x * blockDim.x + threadIdx.x;
int j = blockIdx.y * blockDim.y + threadIdx.y;
int s;
double temp, r;
if (i == 0 && j == 0) { //限定只有单线程执行该核函数
s = k;
r = fabs(augmentedMatrixGPU[k*(n + 1) + k]);
for (int i = k; i < n; i++) {
if (r < fabs(augmentedMatrixGPU[i*(n + 1) + k])) {
r = fabs(augmentedMatrixGPU[i*(n + 1) + k]);
s = i;
}
}
if (s != k) { //交换矩阵的两行
Change(augmentedMatrixGPU + k * (n + 1), augmentedMatrixGPU + s * (n + 1), n);
}
}
}
__global__ void augmented(),__global__ void GaussKernelB,高斯消元。
__global__ void augmented(double *augmentedMatrixGPU, int k, int n) {
int i = blockIdx.x * blockDim.x + threadIdx.x;
int j = blockIdx.y * blockDim.y + threadIdx.y;
if (i == j && j > k && j < n && augmentedMatrixGPU[k * (n + 1) + k] != 0) {
augmentedMatrixGPU[j * (n + 1) + k] = augmentedMatrixGPU[j * (n + 1) + k] / augmentedMatrixGPU[k * (n + 1) + k];
}
}
__global__ void GaussKernelB(double *augmentedMatrixGPU, int k, int n) {
int i = blockIdx.x * blockDim.x + threadIdx.x;
int j = blockIdx.y * blockDim.y + threadIdx.y;
if (i > k && i < n + 1 && j > k && j < n && augmentedMatrixGPU[k * (n + 1) + k] != 0) {
augmentedMatrixGPU[j * (n + 1) + i] = augmentedMatrixGPU[j * (n + 1) + i] -
augmentedMatrixGPU[j * (n + 1) + k] *
augmentedMatrixGPU[k * (n + 1) + i];
}
}
所有的核函数都用的是一维数组进行数据的存储,并把Ax = b,A与b进行合并以增广矩阵的形式进行存储。先用cudaMemcpy把数据从CPU 拷贝到GPU,再用cudaDeviceSynchronize()进行GPU线程同步然后在开始计时,在CPU for循环中进行逻辑控制,把矩阵的消元与计算放到GPU中执行。(坑1:在计时停止前一定要加cudaDeviceSynchronize(),因为CPU与GPU是异步执行的,在for循环结束时GPU的可能仍在执行,若不加同步函数,计时函数(QueryPerformanceCounter(&stop))就会在GPU没有运行完之前就停止计时,导致时间不准确我当时不加同步函数,计时为:0.02ms左右,加同步函数,计时为:1.5ms)。本次计算只进行消元的计时,回代是在CPU上完成的。
cudaMemcpy(augmentedMatrixGPU, augmentedMatrix, sizeof(double)* n * (n + 1), cudaMemcpyHostToDevice);
cudaDeviceSynchronize();
QueryPerformanceCounter(&start);
for (int k = 0; k < n - 1; k++) {
GaussKernelA << <1, 1 >> > (augmentedMatrixGPU, k, n);
augmented << <gridDim, blockDim >> > (augmentedMatrixGPU, k, n);
GaussKernelB << <gridDim, blockDim >> > (augmentedMatrixGPU, k, n);
}
cudaDeviceSynchronize();
QueryPerformanceCounter(&stop);
time = 1000 * (stop.QuadPart - start.QuadPart) / frequence;
printf("GPU time is : %fms", (time));
cudaMemcpy(augmentedMatrix, augmentedMatrixGPU, sizeof(double)* n * (n + 1), cudaMemcpyDeviceToHost);
CPU:高斯消元程序
QueryPerformanceCounter(&sta); //计时开始
for (int k = 0; k < n - 1; k++) {
max = fabs(d[k][k]);
cols = k;
for (int i = k; i < n; i++) { //求最值
if (max < fabs(d[i][k])) {
max = fabs(d[i][k]);
cols = i;
}
}
if (cols != k) { //交换行
for (int j = k; j <= n; j++) {
temp = d[cols][j];
d[cols][j] = d[k][j];
d[k][j] = temp;
}
}
if (!d[k][k]) {
printf("err------------------------------------\n");
return -1;
}
for (int p = k + 1; p < n; p++) { //消元
d[p][k] = d[p][k] / d[k][k];
for (int h = k + 1; h <= n; h++) {
d[p][h] = d[p][h] - d[k][h] * d[p][k];
}
}
}
x[n - 1] = d[n - 1][n] / d[n - 1][n - 1]; //回代
for (int i = n - 2; i >= 0; i--) {
s = d[i][n];
for (int j = i + 1; j <= n; j++) {
s = s - x[j] * d[i][j];
}
x[i] = s / d[i][i];
}
QueryPerformanceCounter(&sto); //计时结束
time2 = 1000 * (sto.QuadPart - sta.QuadPart) / frequence;
printf("CPU time is : %fms\n", time2);
运行时间比较:
矩阵:1000*1000
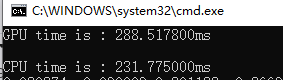
矩阵: 1500*1500
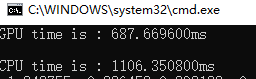
矩阵: 2000*2000
