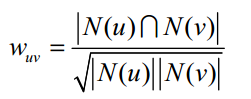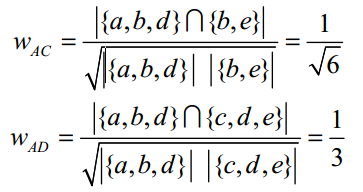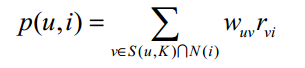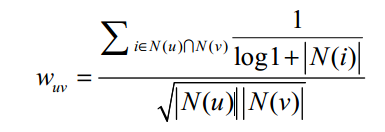利用行为的相似度计算兴趣的相似度。给定用户u和用户v,令N(u)表示用户u曾经有过正反馈的物品集合,令N(v)为用户v曾经有过正反馈的物品集合。那么,我们可以通过如下的Jaccard公式简单地计算u和v的兴趣相似度: 或者通过余弦相似度计算: 以下图用户行为记录为例,举例说明UserCF计算用户兴趣相似度的例子。在该例中,用户A对物品{a, b, d}有过行为,用户B对物品{a, c}有过行为,利用余弦相似度公式计算用户A和用户B的兴趣相似度为: 同理,我们可以计算出用户A和用户C、 D的相似度: 这种方式对两两用户都利用余弦相似度计算相似度。这种方法的时间复杂度是O(|U|*|U|),这在用户数很大时非常耗时。事实上,很多用户相互之间并没有对同样的物品产生过行为,即相似度为0。这种方式将很多时间浪费在了计算这种用户之间的相似度上,换一个思路,可以首先计算出
∣
N
(
u
)
⋂
N
(
v
)
∣
≠
0
|N(u)\bigcap N(v)|\neq0
∣N(u)⋂N(v)∣=0的用户对
(
u
,
v
)
(u,v)
(u,v),然后再对这种情况除以分母
∣
N
(
u
)
∣
∣
N
(
v
)
∣
\sqrt{|N(u)||N(v)|}
∣N(u)∣∣N(v)∣。为此,可以首先建立物品到用户的倒排表,对于每个物品都保存对该物品产生过行为的用户列表。 以下图的用户行为为例。首先,需要建立物品—用户的倒排表,然后,建立一个4×4的用户相似度矩阵W,对于物品a,将W[A][B]和W[B][A]加1,对于物品b,将W[A][C]和W[C][A]加1,以此类推。扫描完所有物品后,我们可以得到最终的W矩阵。这里的W是余弦相似度中的分子部分,然后将W除以分母可以得到最终的用户兴趣相似度。
3.第二步:找到这个集合中的用户喜欢的,且目标用户没有听说过的物品推荐给目标用户。
得到用户之间的兴趣相似度后, UserCF算法会给用户推荐和他兴趣最相似的K个用户喜欢的物品。如下的公式度量了UserCF算法中用户u对物品i的感兴趣程度: 其中, S(u, K)包含和用户u兴趣最接近的K个用户, N(i)是对物品i有过行为的用户集合,
w
u
v
w_{uv}
wuv是用户u和用户v的兴趣相似度,
r
v
i
r_{vi}
rvi 代表用户v对物品i的兴趣,因为使用的是单一行为的隐反馈数据,所以所有的
r
v
i
r_{vi}
rvi=1。 因此可以给倒排序图中的用户A进行推荐。选取K=3,用户A对物品c、 e没有过行为,因此可以把这两个物品推荐给用户A。根据UserCF算法,用户A对物品c、 e的兴趣是: 从而我们在实际的操作中,就可以根据最后得到的p,推荐给用户rank前N的物品。
4.用户相似度计算的改进
用户兴趣相似度的最简单的公式(余弦相似度公式)过于粗糙,以图书为例,如果两个用户都曾经买过《新华字典》,这丝毫不能说明他们兴趣相似,因为绝大多数中国人小时候都买过《新华字典》。但如果两个用户都买过《数据挖掘导论》,那可以认为他们的兴趣比较相似,因为只有研究数据挖掘的人才会买这本书。换句话说,两个用户对冷门物品采取过同样的行为更能说明他们兴趣的相似度。 根据用户行为计算用户的兴趣相似度: 该公式通过
1
log
1
+
∣
N
(
i
)
∣
\frac{1}{\log1+|N(i)|}
log1+∣N(i)∣1惩罚了用户u和用户v共同兴趣列表中热门物品对他们相似度的影响。