1.项目背景
随着电商⾏业近⼏年的迅猛发展,电⼦商务从早些年的粗放式经营,逐步转化为精细化运营。随着平台数据量的不断积累,通过数据分析挖掘消费者的潜在需求,消费偏好成为平台运营过程中的重要环节。本项⽬基于某电商平台⽤户⾏为数据,在MySQL关系型数据库,探索⽤户⾏为规律,寻找⾼价值⽤户;分析商品特征,寻找⾼贡献商品;分析产品功能,优化产品路径。
2.使用“人货场”拆解方式建立指标体系
数据:收藏 --> 产生一条记录
加入购物车 -->产生一条记录
支付购买 --> 产生一条记录
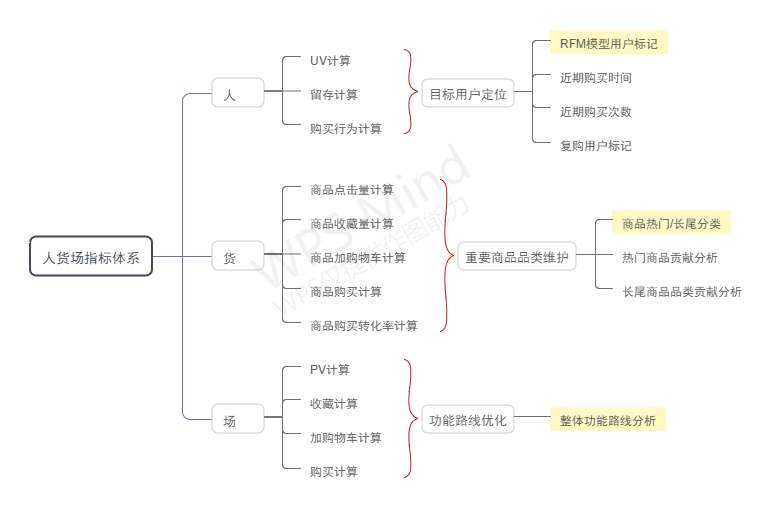
⼈(用户)
分析方向:⽬前平台上的主⼒消费⼈群有哪些特征
他们对货品有哪些需求
他们活跃在哪些场
还有哪些有消费⼒的⼈⽬前不在平台上
| 指标 |
细化指标 |
说明 |
| 浏览 |
PV |
(PageView)⻚⾯浏览量 |
| |
UV |
(Unique Visitor)⼀定时间内访问⽹⻚的⼈数,独⽴访客数(⼀个⽹站或者⼀个⻚⾯/一个终端) |
| 流量质量 |
PV/UV |
浏览深度 |
| |
ROI 投资回报率 |
(ROI)=年利润或年均利润/投资总额×100% |
| 成交⽤户 |
新客数 |
⼀般当天的算新⽤户,当⽇激活或者/新增 |
| |
⽼客数 |
|
| |
客单价 |
当⽇消费总价/顾客数(新+⽼)—客单价应该是稳的,突然多/少,购买⼒特别强影响客单价上升/疫情影响客单价下降 |
| |
DAU |
⽇活跃⽤户 |
| |
MAU |
⽉活跃⽤户 |
货
分析方向:供给,涉及到了货品分层,哪些是红海,哪些是蓝海,如何进⾏动态调整,要做⾃营还是平台
红海:销量高、利润少、竞争多
蓝海:销量少、利润高、竞争少
场(平台)
消费者在什么场景下,以什么样的⽅式接触到了这个商品。
平台:电商网站,往前延伸的引流,往后延伸的后期物流、售后【全域营销】
引流:内容营销,例如微信的 KOL ⽣态、小红书、微博,⽽不在电商⾃⼰的场。
3.确认问题
用户行为数据分析:
1)基于漏⽃模型的⽤户购买流程各环节分析指标,确定各个环节的转换率,便于找到需要改进的环节;
2)商品分析:找出热销商品,研究热销商品特点;
3)基于RFM模型找出核心付费⽤户群,对这部分⽤户进⾏精准营销。
4.准备工作
4.1 数据读取(用户行为数据)
表结构
| 列名 |
说明 |
| user_id |
用户ID |
| item_id |
商品ID |
| behavior_type |
用户行为类型(1-曝光;2-购买;3-加入购物车;4-加入收藏夹) |
| user_geohash |
地理位置 |
| item_category |
品类lD |
| time |
用户行为发生的时间 |
创建表代码
use lagou;
create table o_retailers_trade_user
(
user_id int (9),
item_id int (9),
behavior_type int (1),
user_geohash varchar (14),
item_category int (5),
time varchar (13)
);
注意:样例数据的时间格式如:2019-12-06 02 年-月-日 小时(24进制)
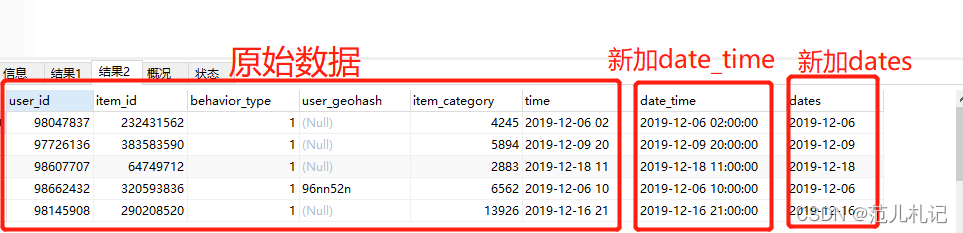
4.2 数据预处理
- 增加新列date_time(datetime),dates(char,年月日),便于后续时间维度分析
#增加新列date_time、dates
#date_time字段来自于基础数据中的time字段
alter table o_retailers_trade_user add column date_time datetime null;
update o_retailers_trade_user set date_time = str_to_date(time,'%Y-%m-%d %H');#%H可以表示0-23;⽽%h表示0-12
#dates字段来自于date_time字段
alter table o_retailers_trade_user add column dates char(10) null;
update o_retailers_trade_user set dates=date(date_time);
#查看处理完的数据
desc o_retailers_trade_user;
select * from o_retailers_trade_user limit 5;
结果展示
#创建新表emp_trade,字段定义参照o_retailers_trade_user,并从o_retailers_trade_user查询去重后的数据插入到新表emp_trade
create table temp_trade like o_retailers_trade_user;
insert into temp_trade select distinct * from o_retailers_trade_user;
#去重前后数据量对比
select t1.原始表记录数,t2.去重后表记录数
from (select count(*) '原始表记录数' from o_retailers_trade_user) t1,
(select count(*) '去重后表记录数' from temp_trade) t2;
结果展示
| 原始表记录数 |
去重后表记录数 |
| 50607 |
47986 |
5.指标体系建设
5.1 用户指标体系
人货场体系
基础指标体系(UV/PV/留存率)+ RFM模型分析
5.1.1 基础指标
需求:UV、PV、留存率(按日)统计
UV:统计distinct user_id 的数量,需要按日统计(分组)
PV:统计behavior_type=1的记录数,需要按日统计(分组)
浏览深度:PV/UV
# pv进⾏cout时候,如果behavior_type=1进⾏计算,否则不进⾏计算
select dates,
count( distinct user_id ) as 'uv',
count( if(behavior_type=1,user_id,null)) as 'pv',
count( if(behavior_type=1,user_id,null))/count( distinct user_id ) as 'pv/uv'
from temp_trade
group by dates;
结果展示
| dates |
uv |
pv |
pv/uv |
| 2019-11-18 |
226 |
1332 |
5.8938 |
| 2019-11-19 |
222 |
1286 |
5.7928 |
| 2019-11-20 |
231 |
1289 |
5.5801 |
| 2019-11-21 |
232 |
1247 |
5.3750 |
| 2019-11-22 |
226 |
1203 |
5.3230 |
with temp_table_trades as(
select a.dates,
count(distinct b.user_id) as user_count,
count(distinct if(datediff(b.dates,a.dates)=1,b.user_id,null)) as device_v_remain1,#1日留存数
count(distinct if(datediff(b.dates,a.dates)=2,b.user_id,null)) as device_v_remain2,#2日留存数
count(distinct if(datediff(b.dates,a.dates)=3,b.user_id,null)) as device_v_remain3,
count(distinct if(datediff(b.dates,a.dates)=4,b.user_id,null)) as device_v_remain4,
count(distinct if(datediff(b.dates,a.dates)=5,b.user_id,null)) as device_v_remain5,
count(distinct if(datediff(b.dates,a.dates)=6,b.user_id,null)) as device_v_remain6,
count(distinct if(datediff(b.dates,a.dates)=7,b.user_id,null)) as device_v_remain7,
count(distinct if(datediff(b.dates,a.dates)=15,b.user_id,null)) as device_v_remain15,
count(distinct if(datediff(b.dates,a.dates)=30,b.user_id,null)) as device_v_remain30
#自关联
from(#group by user_id,dates,某用户在某天只返回一条数据即可
select user_id,dates
from temp_trade
group by user_id,dates ) a
left join(
select user_id,dates
from temp_trade
group by user_id,dates) b
on a.user_id = b.user_id
where b.dates >= a.dates
group by a.dates
)
select dates,user_count,
concat(cast((device_v_remain1/user_count)*100 as decimal(18,2)),'%') as 'day_1%',
concat(cast((device_v_remain2/user_count)*100 as decimal(18,2)),'%') as 'day_2%',
concat(cast((device_v_remain3/user_count)*100 as decimal(18,2)),'%') as 'day_3%',
concat(cast((device_v_remain4/user_count)*100 as decimal(18,2)),'%') as 'day_4%',
concat(cast((device_v_remain5/user_count)*100 as decimal(18,2)),'%') as 'day_5%',
concat(cast((device_v_remain6/user_count)*100 as decimal(18,2)),'%') as 'day_6%',
concat(cast((device_v_remain7/user_count)*100 as decimal(18,2)),'%') as 'day_7%',
concat(cast((device_v_remain15/user_count)*100 as decimal(18,2)),'%') as 'day_15%',
concat(cast((device_v_remain30/user_count)*100 as decimal(18,2)),'%') as 'day_30%'
from temp_table_trades;
结果展示

方法二:用创建视图的方式
create view user_remain_view as(
select a.dates,
count(distinct b.user_id) as user_count,
count(distinct if(datediff(b.dates,a.dates)=1,b.user_id,null)) as device_v_remain1,#1日留存数
count(distinct if(datediff(b.dates,a.dates)=2,b.user_id,null)) as device_v_remain2,#2日留存数
count(distinct if(datediff(b.dates,a.dates)=3,b.user_id,null)) as device_v_remain3,
count(distinct if(datediff(b.dates,a.dates)=4,b.user_id,null)) as device_v_remain4,
count(distinct if(datediff(b.dates,a.dates)=5,b.user_id,null)) as device_v_remain5,
count(distinct if(datediff(b.dates,a.dates)=6,b.user_id,null)) as device_v_remain6,
count(distinct if(datediff(b.dates,a.dates)=7,b.user_id,null)) as device_v_remain7,
count(distinct if(datediff(b.dates,a.dates)=15,b.user_id,null)) as device_v_remain15,
count(distinct if(datediff(b.dates,a.dates)=30,b.user_id,null)) as device_v_remain30
#自关联
from(#group by user_id,dates,某用户在某天只返回一条数据即可
select user_id,dates
from temp_trade
group by user_id,dates ) a
left join(
select user_id,dates
from temp_trade
group by user_id,dates) b
on a.user_id = b.user_id
where b.dates >= a.dates
group by a.dates
)
select dates,user_count,
#1日留存率,cast转换函数,decimal函数长度为10,保留2位小数
concat(cast((device_v_remain1/user_count)*100 as decimal(10,2)),'%') as 'day_1%',
concat(cast((device_v_remain2/user_count)*100 as decimal(10,2)),'%') as 'day_2%',
concat(cast((device_v_remain3/user_count)*100 as decimal(10,2)),'%') as 'day_3%',
concat(cast((device_v_remain4/user_count)*100 as decimal(10,2)),'%') as 'day_4%',
concat(cast((device_v_remain5/user_count)*100 as decimal(10,2)),'%') as 'day_5%',
concat(cast((device_v_remain6/user_count)*100 as decimal(10,2)),'%') as 'day_6%',
concat(cast((device_v_remain7/user_count)*100 as decimal(10,2)),'%') as 'day_7%',
concat(cast((device_v_remain15/user_count)*100 as decimal(10,2)),'%') as 'day_15%',
concat(cast((device_v_remain30/user_count)*100 as decimal(10,2)),'%') as 'day_30%'
from user_remain_view;
思考:pv计算中为什么要求behavior_type=1?
5.1.2 RFM模型分析
#1.建立R视图,将近期购买时间提取到R临时表中
drop view if exists user_recency_view;
create view user_recency_view as
select user_id, max(dates) as recent_buy_time
from temp_trade
where behavior_type = 2 #购买行为
group by user_id;
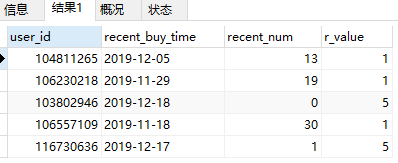
#2.计算每个用户最近购买时间距离2019-12-18相差几天,根据相差天数给予一定的分数
drop view if exists r_clevel;
create view r_clevel as
select user_id,recent_buy_time,datediff('2019-12-18',recent_buy_time) as recent_num,
(case when datediff('2019-12-18',recent_buy_time) <= 2 then 5
when datediff('2019-12-18',recent_buy_time) <= 4 then 4
when datediff('2019-12-18',recent_buy_time) <= 6 then 3
when datediff('2019-12-18',recent_buy_time) <= 8 then 2
else 1 end) as 'r_value'
from user_recency_view;
#查看前5条
select * from r_clevel limit 5;
结果展示
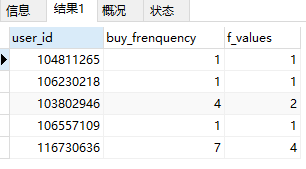
#1.建⽴F视图
create view frenq_value as
select user_id ,count(user_id) as buy_frenquency
from temp_trade
where behavior_type = 2
group by user_id;
#2.建⽴F等级划分
create view f_clevel as
select user_id,buy_frenquency,
(case when buy_frenquency <=2 then 1
when buy_frenquency <= 4 then 2
when buy_frenquency <= 6 then 3
when buy_frenquency <= 8 then 4
else 5 end) as 'f_values'
from frenq_value;
#查看视图结果的前五条
select * from f_clevel limit 5;
-
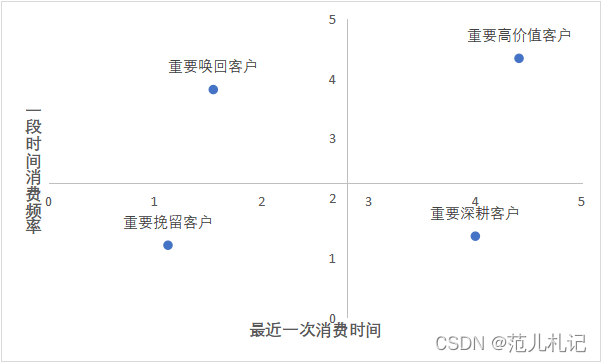
RFM模型:整合结果
本次数据中通过最近消费(R)和消费频率(F)建立RFM模型,按照最近⼀次消费的均值和消费频率的均值定高低界限。
R:最近购物的时间间隔
F:一定时间段内的购物频率
M:一定时间段内的购物消费金额
用户分类的说明
-
重要高价值客户:指最近⼀次消费较近且消费频率较⾼的客户;
-
重要唤回客户:指最近⼀次消费较远且消费频率较⾼的客户;
-
重要深耕客户:指最近⼀次消费较近且消费频率较低的客户;
-
重要挽留客户:指最近⼀次消费较远且消费频率较低的客户;
#1.R平均值
select avg(r_value) as 'r_avg' from r_clevel; -- 2.7939
#2.F平均值
select avg(f_values) as 'f_avg' from f_clevel; -- 2.2606
#3.查看R平均值和F平均值
select r.r_avg,f.f_avg
from (select avg(r_value) as 'r_avg' from r_clevel) r,
(select avg(f_values) as 'f_avg' from f_clevel) f;
结果展示
| r_avg |
f_avg |
| 2.7936 |
2.2606 |
#4.⽤户⼋⼤类等级划分,由于该数据没有M值,故只建⽴了4个分类
drop view if exists RFM_inall;
create view RFM_inall as
select r.user_id , r.r_value, f.f_values,
(case when r.r_value > 2.7939 and f.f_values > 2.2606 then '重要⾼价值客户'
when r.r_value < 2.7939 and f.f_values > 2.2606 then '重要唤回客户'
when r.r_value > 2.7939 and f.f_values < 2.2606 then '重要深耕客户'
when r.r_value < 2.7939 and f.f_values < 2.2606 then '重要挽留客户'
end) as 'user_class'
from r_clevel r, f_clevel f
where r.user_id = f.user_id;
select count(user_id) as user_v,user_class
from RFM_inall
group by user_class;
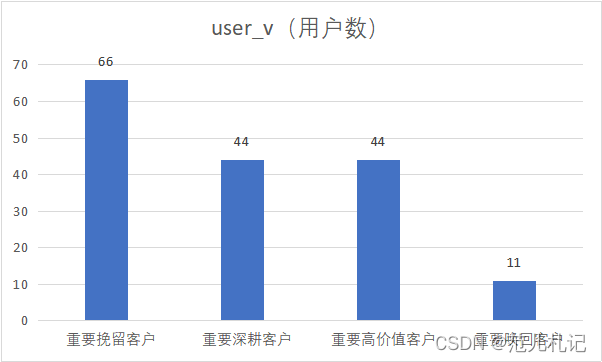
结果展示
| user_v (用户数) |
user_class |
平均值项:r_value |
平均值项:f_values |
| 66 |
重要挽留客户 |
1.545454545 |
3.818181818 |
| 44 |
重要深耕客户 |
4 |
1.363636364 |
| 44 |
重要高价值客户 |
1.121212121 |
1.212121212 |
| 11 |
重要唤回客户 |
4.409090909 |
4.340909091 |
5.2 商品指标体系
商品的点击量 收藏量 加购量 购买次数 购买转化(该商品的所有用户中有购买转化的用户比;)
按照商品进行分组统计
- 商品的点击量 收藏量 加购量 购买次数 购买转化
select * from temp_trade;
select item_id,
sum(case when behavior_type=1 then 1 else 0 end) as'pv',
sum(case when behavior_type=4 then 1 else 0 end) as'fav',
sum(case when behavior_type=3 then 1 else 0 end) as'cart',
sum(case when behavior_type=2 then 1 else 0 end) as'buy',
count(distinct case when behavior_type=2 then user_id else null end)/count(distinct user_id) as 'buy_rate'
from temp_trade
group by item_id
order by buy desc;
对应品类的点击量 收藏量 加购量 购买次数 购买转化(该商品品类的所有用户中有购买转化的用户
比;)
select item_category,
sum(case when behavior_type=1 then 1 else 0 end) as'pv',
sum(case when behavior_type=4 then 1 else 0 end) as'fav',
sum(case when behavior_type=3 then 1 else 0 end) as'cart',
sum(case when behavior_type=2 then 1 else 0 end) as'buy',
count(distinct case when behavior_type=2 then user_id else null end)/count(distinct user_id) as 'buy_rate'
from temp_trade
group by item_category
order by buy desc;
5.3 平台价值指标体系
1.⾏为指标:
点击次数 收藏次数 加购物⻋次数 购买次数 购买转化(该平台当日的所有⽤户中有购买转化的用户比)
-- 每⽇的分析(1-4,分别表示点击pv、购买buy、加购物⻋cart、喜欢fav)
select dates,count(1) as '每⽇的总数',
sum(case when behavior_type=1 then 1 else 0 end) as'pv',
sum(case when behavior_type=4 then 1 else 0 end) as'fav',
sum(case when behavior_type=3 then 1 else 0 end) as'cart',
sum(case when behavior_type=2 then 1 else 0 end) as'buy',
count(distinct case when behavior_type=2 then user_id else null end)/count(distinct user_id) as buy_rate
from temp_trade
group by dates;
2、行为路径分析
#⾏为路径组建基础视图
create view path_base_view as
select a.*
from(select user_id,item_id,
lag ( behavior_type, 4 ) over ( partition by user_id, item_id order by date_time ) lag_4,
lag ( behavior_type, 3 ) over ( partition by user_id, item_id order by date_time ) lag_3,
lag ( behavior_type, 2 ) over ( partition by user_id, item_id order by date_time ) lag_2,
lag ( behavior_type, 1 ) over ( partition by user_id, item_id order by date_time ) lag_1,
behavior_type,
rank() over(partition by user_id, item_id order by date_time desc) as rank_number
from temp_trade
)a where a.rank_number = 1 and a.behavior_type = 2;
#拼接行为路径
select concat(ifnull(lag_4,'空'),'-',
ifnull(lag_3,'空'),'-',
ifnull(lag_2,'空'),'-',
ifnull(lag_1,'空'),'-',
behavior_type)
from path_base_view;
#针对行为路径进行分组count统计
select concat(ifnull(lag_4,'空'),'-',
ifnull(lag_3,'空'),'-',
ifnull(lag_2,'空'),'-',
ifnull(lag_1,'空'),'-',
behavior_type) as user_way,
count(distinct user_id) as user_count
from path_base_view
group by concat(ifnull(lag_4,'空'),'-',
ifnull(lag_3,'空'),'-',
ifnull(lag_2,'空'),'-',
ifnull(lag_1,'空'),'-',
behavior_type);
6.结论
6.1 用户分析
UV异常分析:每日UV数据中,明显异常点为双十二活动造成,该影响为已知影响。


对于UV周环比的分析:日常周环比数据大多大于0,说明⽤户程⼀定上升趋势,其中如11月26日、12月2日、12月7日等的数据为下降数据,需要结合其他数据做进⼀步的下降原因分析。双十二活动后⽤户周环比会相应下降,为正常原因。
猜测可能的问题有:
内部问题:产品BUG(网站bug)、策略问题(周年庆活动结束了)、营销问题(代言人换了)等;
外部问题:竞品活动问题(其他平台大酬宾),政治环境问题(进口商品限制),舆情口碑问题(平台商品爆出质量问题)等
6.2 用户精细化运营X
通过RFM模型中的⽤户最近⼀次购买时间、⽤户消费频次分析,分拆得到以下重要⽤户。
可以在后续精细化运营场景中直接使⽤细分用户,做差异化运营:
对高价值客户做VIP服务设计,增加⽤户粘性同时通过设计优惠券提升客户消费;
对深耕客户做⼴告、推送刺激,提升消费频次;
对挽留客户做优惠券、签到送礼策略,增加挽留用户粘性;
对唤回客户做定向⼴告、短信召回策略,尝试召回用户。
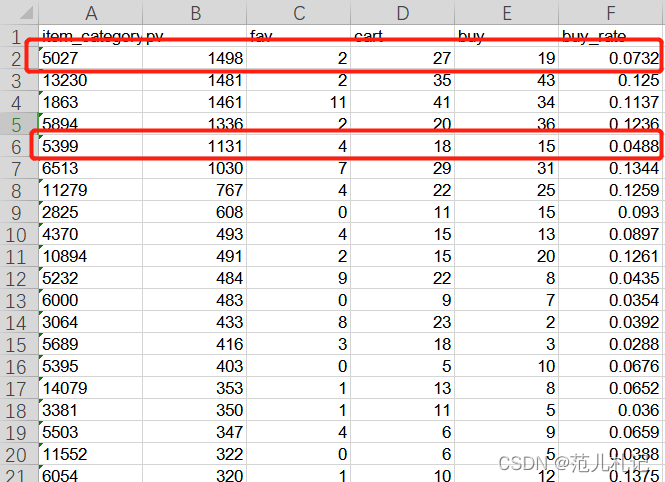
6.3 商品分析
热销商品品类如下所示。
其中“5027”、“5399”品类购买转化率较其余商品品类偏低,需要结合更多数据做进⼀步解读。(可能的原因:品类自有特性导致用户购买较低,比如非必需、奢侈品等等。)
6.4 产品功能路径分析
以下为主要购买路径。可以发现用户多以直接购买为主;添加购物车的购买在主要购买路径中数量较少。后续的产品加购功能和产品收藏功能还需要结合更多数据做改进方案。
| use_way |
user_count |
| 空-1-1-1-2 |
1 |
| 空-空-1-1-2 |
10 |
| 空-空-1-3-2 |
1 |
| 空-空-2-1-2 |
2 |
| 空-空-空-1-2 |
64 |
| 空-空-空-2-2 |
1 |
| 空-空-空-3-2 |
2 |
| 空-空-空-空-2 |
146 |