论文:A Simple Framework for Contrastive Learning of Visual Representations
代码: https://github.com/google-research/simclr
出处:ICML 2020 | Hinton 大佬 | Google
贡献:
- 证明不同数据增强的结合很重要
- 在特征表达和 contrastive loss 之间引入了可学习的非线性 transformer 结构,取得了很大的效果提升
- 在大的 batch size 和大的 epoch 的加持下对比学习能获得比有监督学习更好的效果
效果:
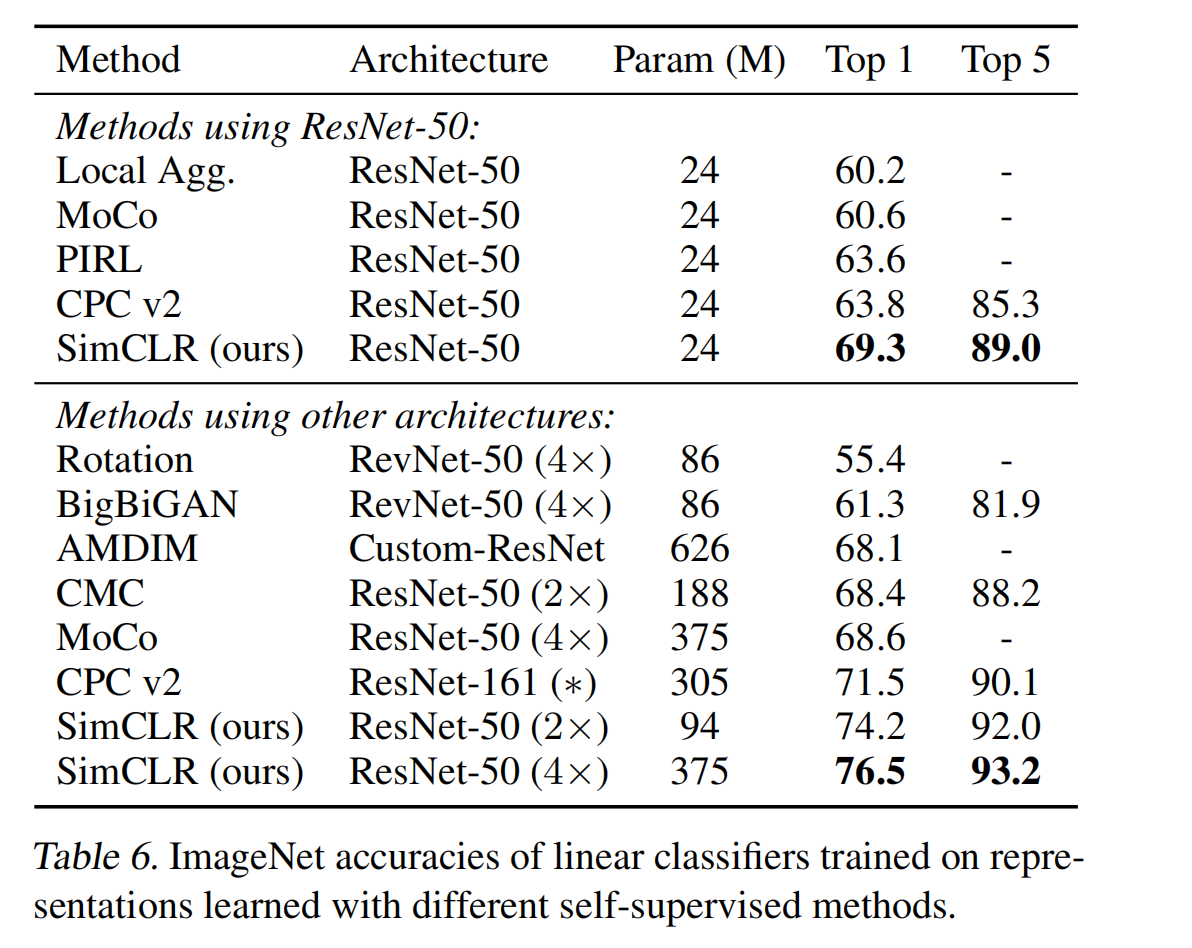
- 使用自监督对比学习的方式训练 ImageNet 提取特征后,训练了一个线性分类器,就获得了 76.5% top-1 acc,比当时的 SOTA 高 7%,和有监督基线网络 ResNet50 获得了同样的效果
一、背景
目前来说,大致有两个不同的路线来做无标签的视觉特征提取,分别是 generative 和 discriminative,也就是生成式和判别式
- 生成式的方法是学习如何生成和输入空间相同的像素 ,但是 pixel-level 的生成计算量很大而且没有很强的特征表达意义
- 判别式的方法是使用目标函数来判断两个输入是否来源于同一个数据,一般都是需要使用代理任务来对同一输入生成不同的样本,所以代理任务如果用的不好,有可能会限制模型的泛化性。
基于判别式的方法在目前取得了 SOTA 的效果(如 MOCO),所以本文作者为了探究其原因,就做了一些探索和实验,并且证明了下面这几个结论:
- 在代理任务中,结合使用多种不同的数据增强方式能得到更好的特征表达,而且数据增强为无监督对比学习带来的效果提升大于有监督学习
- 作者在特征表达的计算 contrastive loss 之间引入了一个可学习的非线性 transformer,能很大程度的提高模型效果
- 对特征进行归一化更有利于使用 contrastive cross entropy 学习的方法
- 自监督学习需要更大的 batch size 和更长的训练时间(相比有监督学习而言)
作者正式结合了上面的几种发现,所以才构建了一个简单的网络框架 SimCLR
二、方法
2.1 对比学习框架

SimCLR 是通过最大化同一样本的不同视角在特征空间中的一致性来学习的,网络结构如图 2 所示
-
首先,给定一个输入样本 x,作者使用数据增强来生成两个图片,这两个图片就是一对 positive pairs。
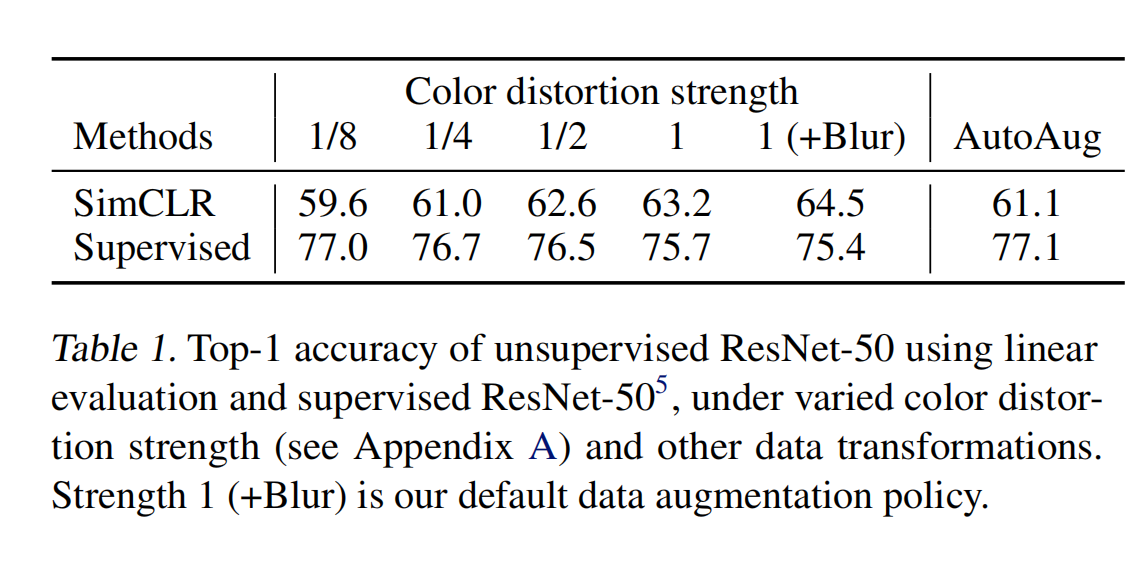
本文中会顺序的使用 3 种数据增强:random cropping → resize 回原来的尺寸 → random color distortion →随机高斯噪声。因为作者通过实验发现 random crop 和 color distortion 的结合能取得最好的效果。
-
然后,使用基础 encoder
f
(
.
)
f(.)
f(.) 来抽取数据的特征,这里的 encoder 选择的是 ResNet
-
接着,对得到的特征使用 projection head
g
(
.
)
g(.)
g(.) 来将特征映射到 contrastive loss space。这里的
g
(
.
)
g(.)
g(.) 是有一层隐藏层的 MLP。这里的
g
(
.
)
g(.)
g(.) 是非线性的,因为使用了 ReLU 激活函数。
-
最后,在最终的特征上进行对比预测任务,使用的是对比学习 loss,也就是在给定一堆经过变换后的样本,模型要能通过给定的
x
i
x_i
xi 识别出其对应的正样本
x
j
x_j
xj
对比学习具体是怎么学习的呢:
-
首先,假设一个 batch 输入了 N 个 samples,经过代理任务后,就能得到 2N 个 augumented samples
-
然后,使用
f
(
.
)
f(.)
f(.) 和
g
(
.
)
g(.)
g(.) 进行对应的特征提取,得到
z
i
z_i
zi 和
z
j
z_j
zj
-
接着,计算对比学习 loss,对于一个样本
z
i
z_i
zi,只有一个正样本
z
j
z_j
zj,其余所有的 2(N-1) 个 augumented samples 都是负样本,所以样本 i 对应的 loss 函数如下,分母是剔除了 i 自己,sim 表示点乘,
τ
\tau
τ 表示温度参数

SimCLR 的整体过程:
这里为什么是 2k-1 次呢,因为一个 sample 得到的两个 aug samples 都是当前 batch 内的样本,所以每个样本都会和其他所有的样本计算 loss,i 和 j 计算一次,j 和 i 也会计算一次,所以每个样本都会计算 2k-1 次 loss。然后最后的 L 也除以 2 了,因为每个样本都计算了 2 次。

2.2 训练所使用的 batch size
我们已知对比学习比较依赖于负样本的数量,只有在负样本数量较大的时候才能学习到更有区分力的特征
所以作者使用了从 256~8192 大小的 batch size,当 batch size 为 8192 时,每个样本对应的负样本的数量就是 16382 (16382=2x(8192-1))
如果使用这么大的 batch size 同时使用 SGD/Momentum 优化器结合线性学习率变化的话,就会不稳定,所以作者使用了 LARS 优化器。
Global BN:所有机器上的数据共同计算 BN 的 mean 和 variance
在分布式训练中,BN 的 mean 和 variance 是计算单个卡上的所有样本得到的。在对比学习中,positive pairs 是同一机器上得到的,会导致信息泄露,泄露给模型说所有的正样本对都在对角线上,模型能使用泄露的局部信息来提高准确率,而不用提高学习效果。
为了避免这个问题,作者使用一次迭代的所有机器上的全部数据来计算 mean 和 variance,MOCO 中使用 shuffling data 的方式解决。
2.3 数据增强方式

图 4 中展示了不同的数据增强方式,作者也对不同的数据增强方式进行了凉凉组合,最后发现结合 random crop 和 color 的方式能够得到最好的效果
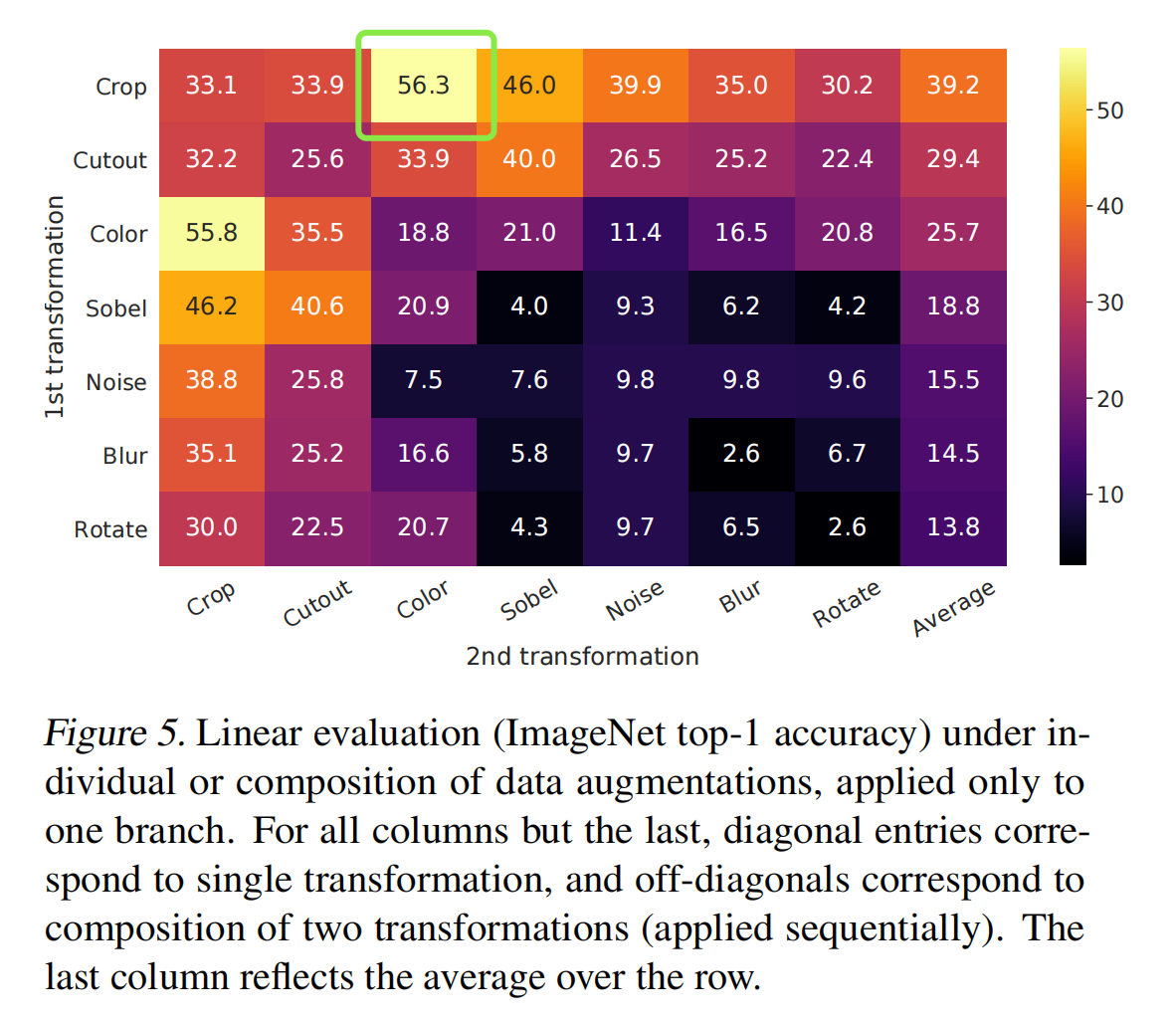
且作者证明了 strong augmentation 在无监督学习中更重要
2.4 更大的模型更有利于无监督对比学习

2.5 非线性映射头能带来更好的效果

2.6 更大的 batch size 和更长的训练时间更有利于对比学习

2.7 测评方式
之前和很多无监督与村里方法的测评都是在 ImageNet 上,还有一些在 cifar-10 上。
作者在本文中也会使用迁移学习的方式来测评预训练模型的效果
作者测评使用的方式是 linear protocal(就是冻结预训练 backbone,只训练最后添加的分类头)
设置:
- base encoder:R50
- projection head(从输出映射到 128-d 特征):2 层 MLP
- loss: NT-Xent,使用 LARS ,学习率为 4.8,weight decay 为 10^-6
- batch size:4096
- epoch:100
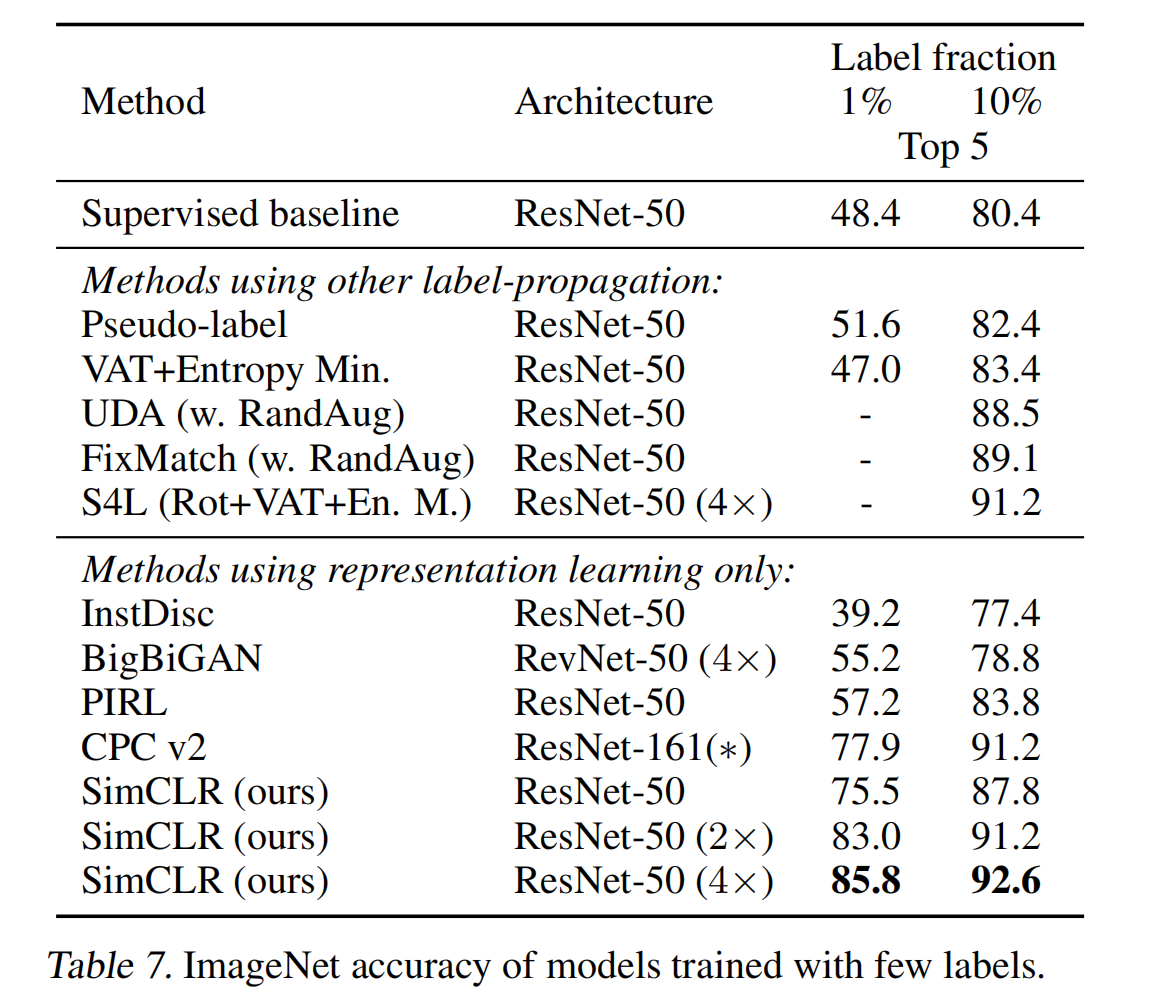
三、效果