ArrayList
默认长度为10

indexOf lastIndexOf
通过equals方法判断索引
public int indexOf(Object o) {
if (o == null) {
for (int i = 0; i < size; i++)
if (elementData[i]==null)
return i;
} else {
for (int i = 0; i < size; i++)
if (o.equals(elementData[i]))
return i;
}
return -1;
}
clone
Arrays.CopyOf
public Object clone() {
try {
ArrayList<?> v = (ArrayList<?>) super.clone();
v.elementData = Arrays.copyOf(elementData, size);
v.modCount = 0;
return v;
} catch (CloneNotSupportedException e) {
throw new InternalError(e);
}
}
toArray
public Object[] toArray() {
return Arrays.copyOf(e`在这里插入代码片`lementData, size);
}
扩容 grow方法
private void grow(int minCapacity) {
int oldCapacity = elementData.length;
int newCapacity = oldCapacity + (oldCapacity >> 1);
if (newCapacity - minCapacity < 0)
newCapacity = minCapacity;
if (newCapacity - MAX_ARRAY_SIZE > 0)
newCapacity = hugeCapacity(minCapacity);
elementData = Arrays.copyOf(elementData, newCapacity);
}
add
System.arraycopy
public void add(int index, E element) {
rangeCheckForAdd(index);
ensureCapacityInternal(size + 1);
System.arraycopy(elementData, index, elementData, index + 1,
size - index);
elementData[index] = element;
size++;
}
LinkedList
Node 节点
Node 节点 创建构造方法时是前中后创建
private static class Node<E> {
E item;
Node<E> next;
Node<E> prev;
Node(Node<E> prev, E element, Node<E> next) {
this.item = element;
this.next = next;
this.prev = prev;
}
}
add
尾插法
public boolean add(E e) {
linkLast(e);
return true;
}
HashMap
HashMap的继承关系:
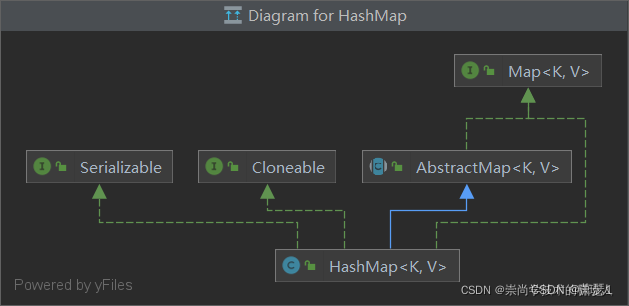
Map->AbstractMap->HashMap
HashMap 是以key-value形式存在,它是线程不安全的,它的key、value都可以为null。
static final int DEFAULT_INITIAL_CAPACITY = 1 << 4;
static final int MAXIMUM_CAPACITY = 1 << 30;
static final float DEFAULT_LOAD_FACTOR = 0.75f;
static final int TREEIFY_THRESHOLD = 8;
static final int UNTREEIFY_THRESHOLD = 6;
static final int MIN_TREEIFY_CAPACITY = 64;
int threshold;
TREEIFY_THRESHOLD 选择8的理由
hashCode 算法下所有桶中链表结点的分布概率会遵循泊松分布,这时一个桶中链表长度超过8个约束的概率非常小,权衡空间和时间复杂度,所以选择8这个数字。
loadFactor 太大导致查找元素效率低,太小导致数组的利用率低,存放的数据会很分散。loadFactor的默认值为0.75f是官网给出的一个比较好的临界值。
为什么负载因子设置为0.75,初始化临界值是12?
loadFactor 越趋近于1,那么 数组中存放的数据(entry)也就越多,也就越密,也就是会让链表的长度增加,导致链表长度可能超过阈值,从而使得查找效率降低;loadFactor 越小,也就是趋近于0,数组中存放的数据(entry)也就越少,也就越稀疏,可能导致数组空间大量空闲而使得数组空间浪费。
所以既兼顾数组利用率又考虑链表不要太多,经过大量测试 0.75 是最佳方案。
当链表长度大于8,且hash数组长度大于等于64,才会将此索引链表变为红黑树,否则进行数组扩容(将数组长度扩大为2倍,并进行rehash),这样做的目的是因为数组比较小,这种情况下变为红黑树结构,反而会降低效率。
hash 方法:hash&(length-1)
hash函数方法:
hashCode是根据地址值随机转化成一个数值得到的。
static final int hash(Object key) {
int h;
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}
判断键是否相同
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
putVal方法
1.判断是否为空,为空则先resize。
2.判断hash后所在索引是否为空,为空则创建一个新节点。
否则进行处理hash冲突
3.如果hash后的key与第一个节点相等,则找到要put的位置。
4.如果第一个节点是TreeNode节点,则进入红黑树查找。
4.如果是一个链表,则进入链表查找。如果大于8则进入是否转化为红黑树环节。
5.如果size大于临界值,则扩容。
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
boolean evict) {}
getNode方法
final Node<K,V> getNode(int hash, Object key) {}
1.判断HashMap是否为空,为空返回null。
2.根据hash值找到所在索引,如果索引为空返回null,如果不为空且key值比较相等,则返回元素。
3.判断节点是为链表还是红黑树,分别用各自的方法进行查找。
本文内容由网友自发贡献,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系:hwhale#tublm.com(使用前将#替换为@)