诸神缄默不语-个人CSDN博文目录
论文名称:Generalization through Memorization: Nearest Neighbor Language Models
模型简称:kNN-LMs
本文是2020年ICLR论文,ArXiv网址是https://arxiv.org/abs/1911.00172
作者来自斯坦福和Facebook。
官方GitHub项目:urvashik/knnlm
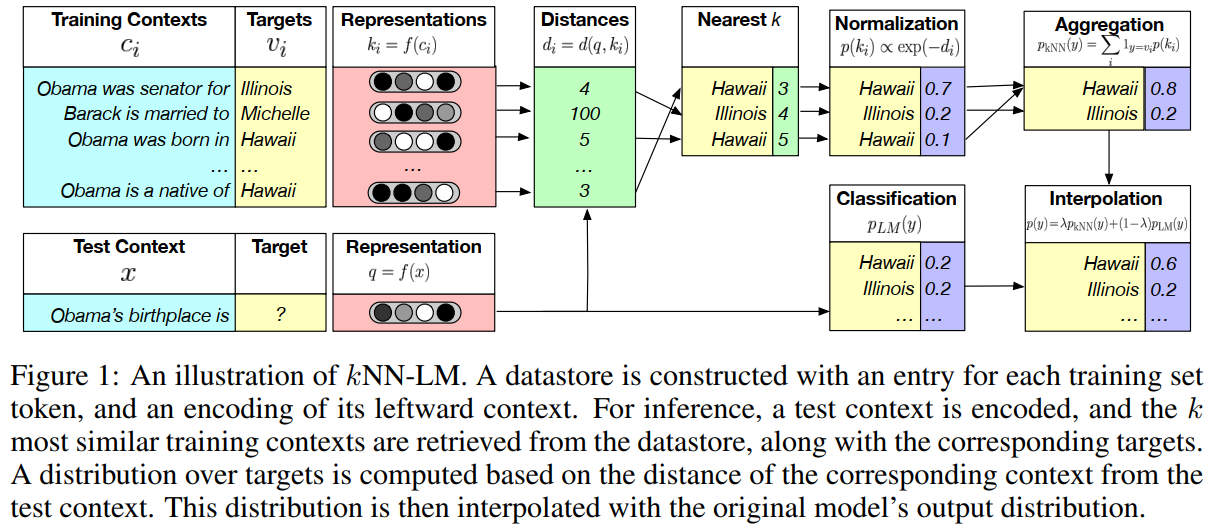
kNN-LMs通过检索数据集中相似句子,来辅助生成测试数据的下一个token。
假设是文本表征任务比预测下一个token的任务更容易。
做法:在LLM分类的概率上,加一个kNN概率(对测试样本检索k个邻居,其target token的概率与样本距离成反比)来预测下一个token。
这里最近邻的表征是通过LLM得到的,邻居本身可以来自任何文本数据(包括预训练数据)。
kNN-LMs可以不用训练,只要构建出datastore,就能实现。
这个直觉上就像你学英语的时候,有个词不知道用得对不对,就去网上找找别的句子怎么写,如果类似的句子也这么措辞,你就感觉你写对了。直觉。
哎想想我有个项目也差不多用的是这种“参考”的思路,结果它凉了……不说了都是泪。
1. 任务定义和模型介绍
任务定义:对上下文序列
c
t
=
(
w
1
,
…
,
w
t
−
1
)
c_t=(w_1,\dots,w_{t-1})
ct=(w1,…,wt−1),AR LM 估计下一个token(目标token
w
t
w_t
wt)的概率分布
p
(
w
t
∣
c
t
)
p(w_t|c_t)
p(wt∣ct)
context-target对以键值对的形式储存在datastore中
键:context的表征
值:target token
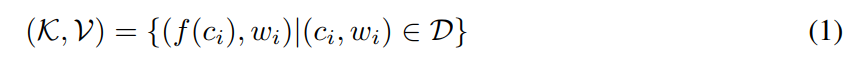
距离函数
d
d
d:L2距离,RBF核
检索最近邻:FAISS
kNN得到的LM概率:
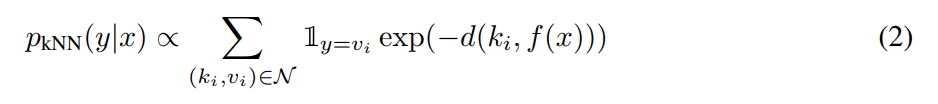
参考1,用可训练参数
λ
\lambda
λ(在实验中,通过验证集学习)将2个概率加起来:
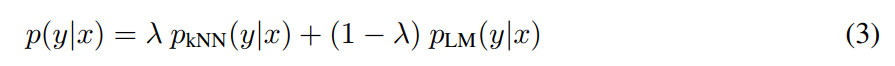
2. 实验
1. 数据集
都是英文LM语料:
Wikitext-103
Books
Wiki-3B
Wiki-100M
2. 实验设置
用2的结构和优化作为基础LM。
Transformer:
向量维度是1024。在datastore中每个target token有512+ tokens的上下文
其他具体细节略。
3. 评估指标
perplexity
具体细节略。
4. 主实验
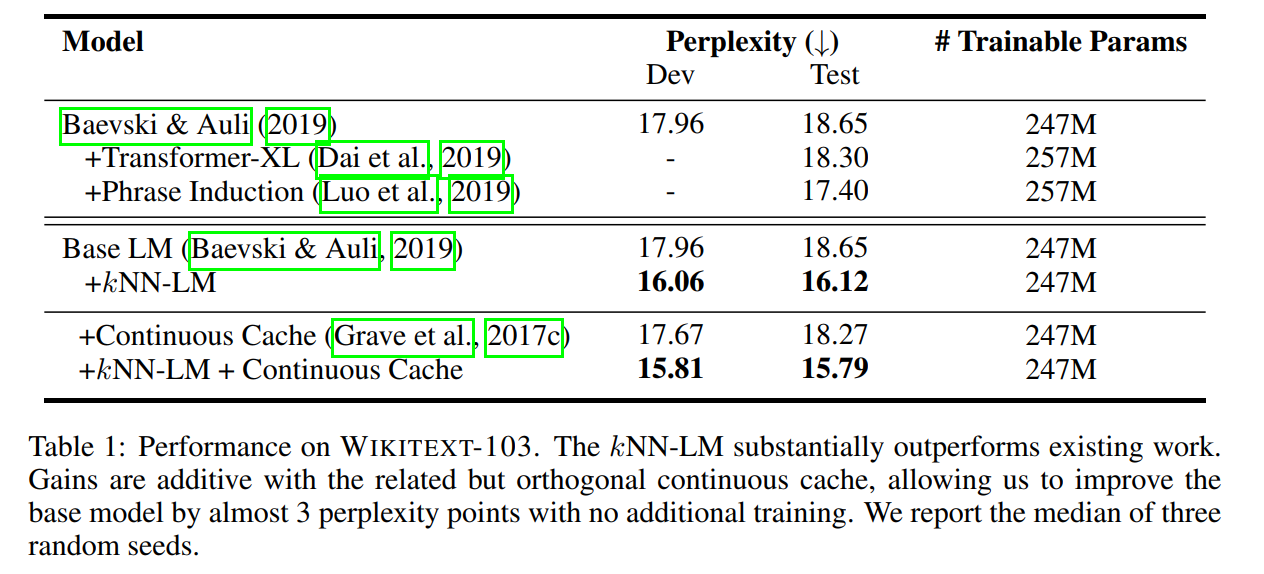
上图continuous cache是从测试文档中找邻居

5. 模型分析
-
在小数据上预训练,用大数据做datastore,就能获得比大数据预训练模型更好的效果:
证明检索比预训练效果更好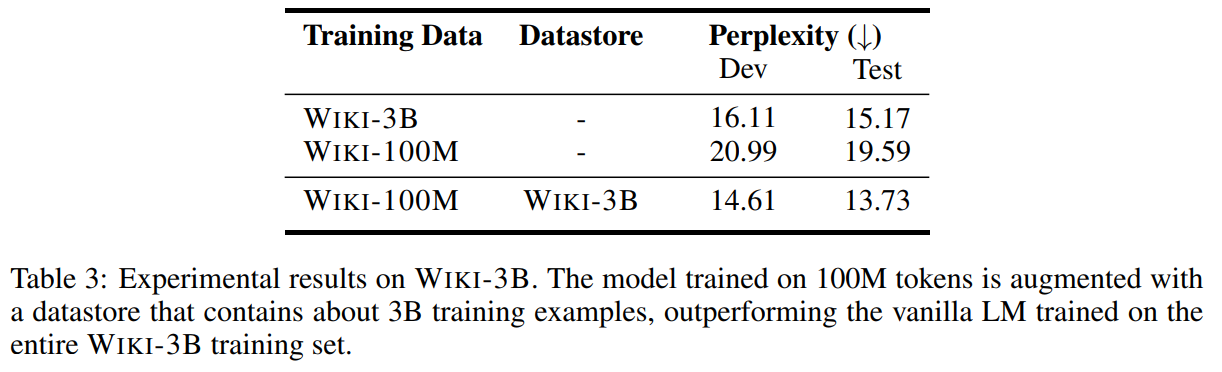
-
datastore越大,效果越好,
λ
\lambda
λ也越高
而且效果越来越好,一直没有饱和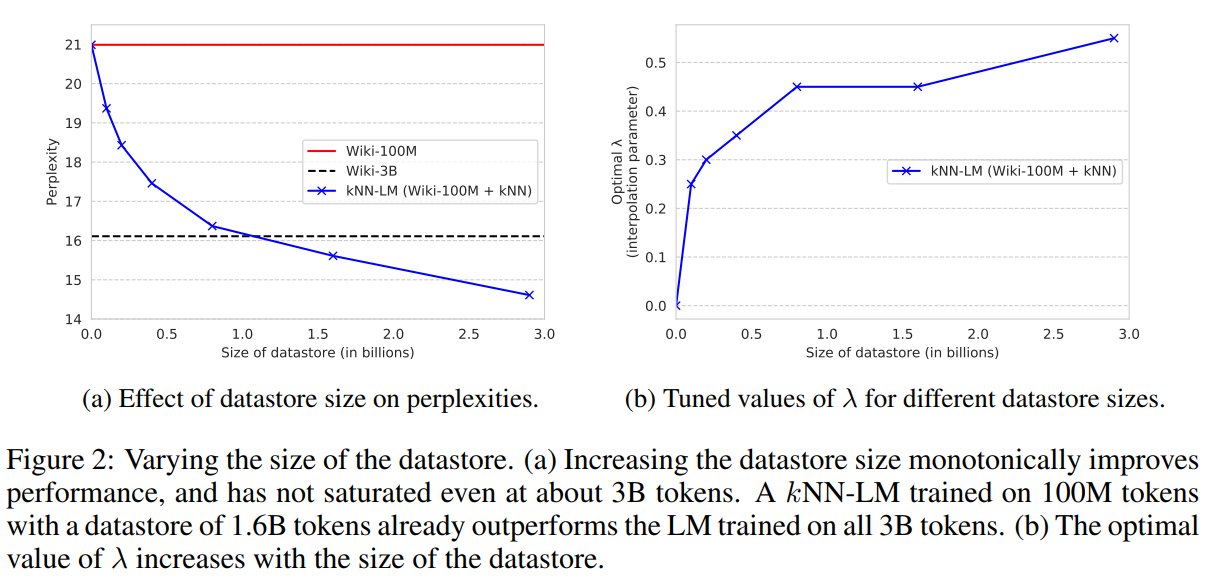
-
领域泛化能力:
-
这个实验是研究用模型的哪个表征效果最好:
这个假说蛮有意思的:

-
这个是衡量超参数k的影响(是绝对的越大越好):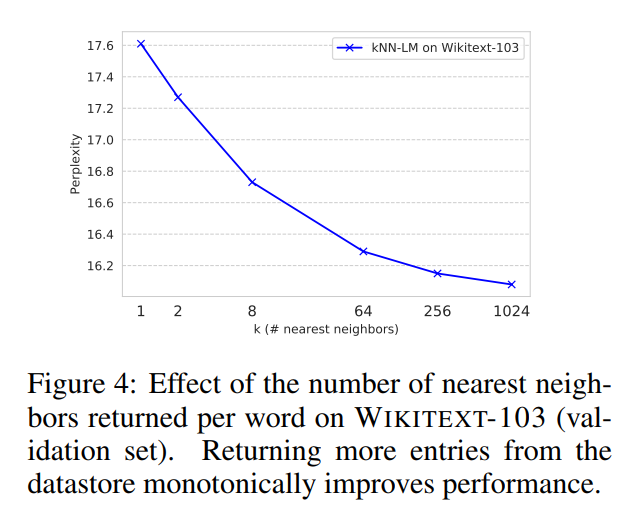
-
这个是衡量超参数
λ
\lambda
λ的影响: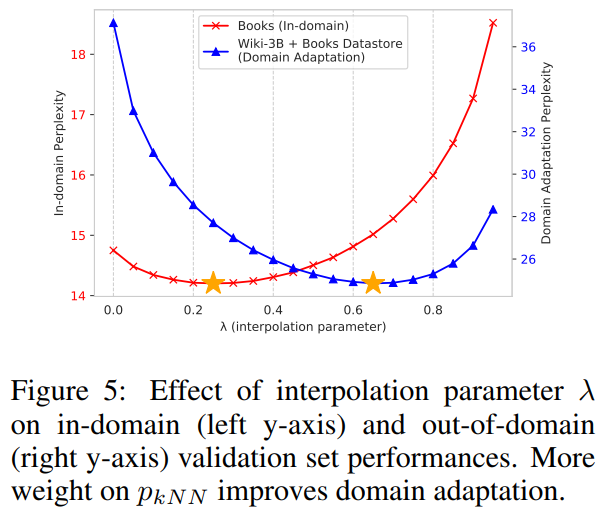
-
FAISS用量化键计算L
2
^2
2距离,如果改用全精度键,perplexity会继续提升(小编锐评:那么代价是什么呢)
-
案例分析:
通过检索可以学习到n-gram结构,因此效果超过了uni-gram LM:
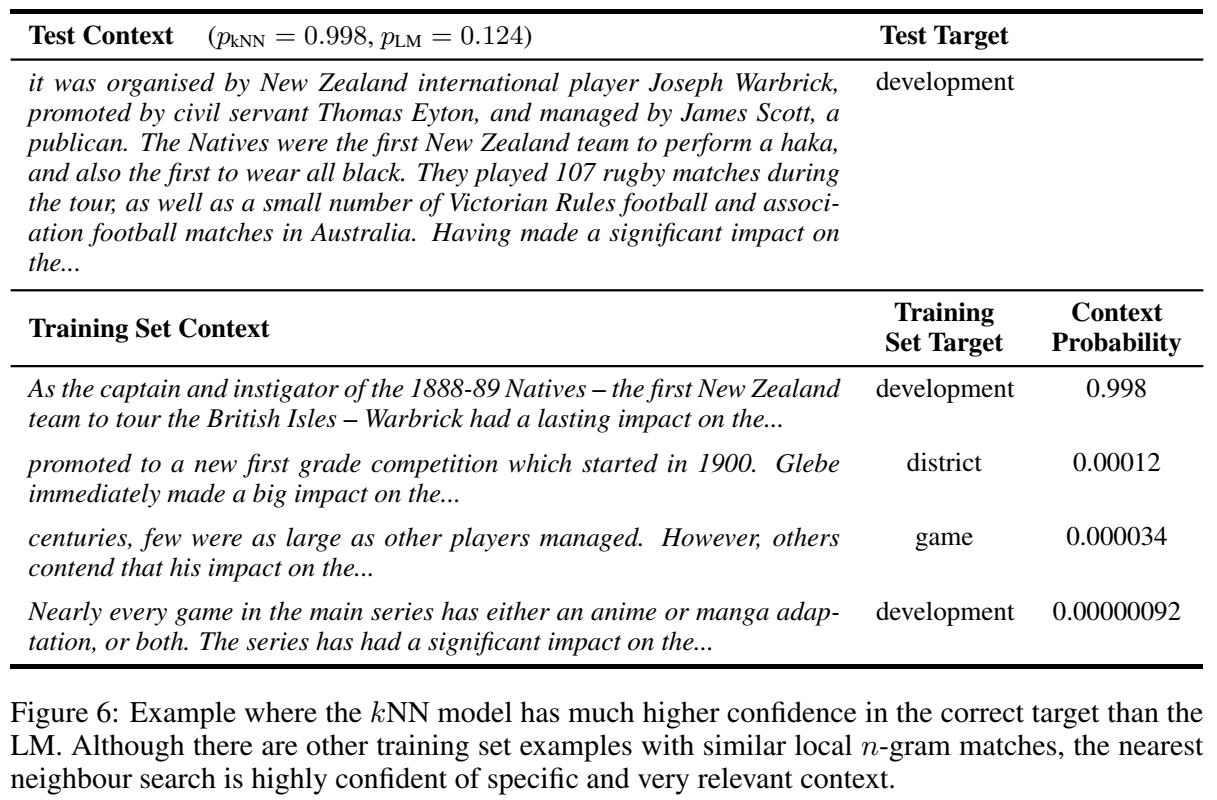
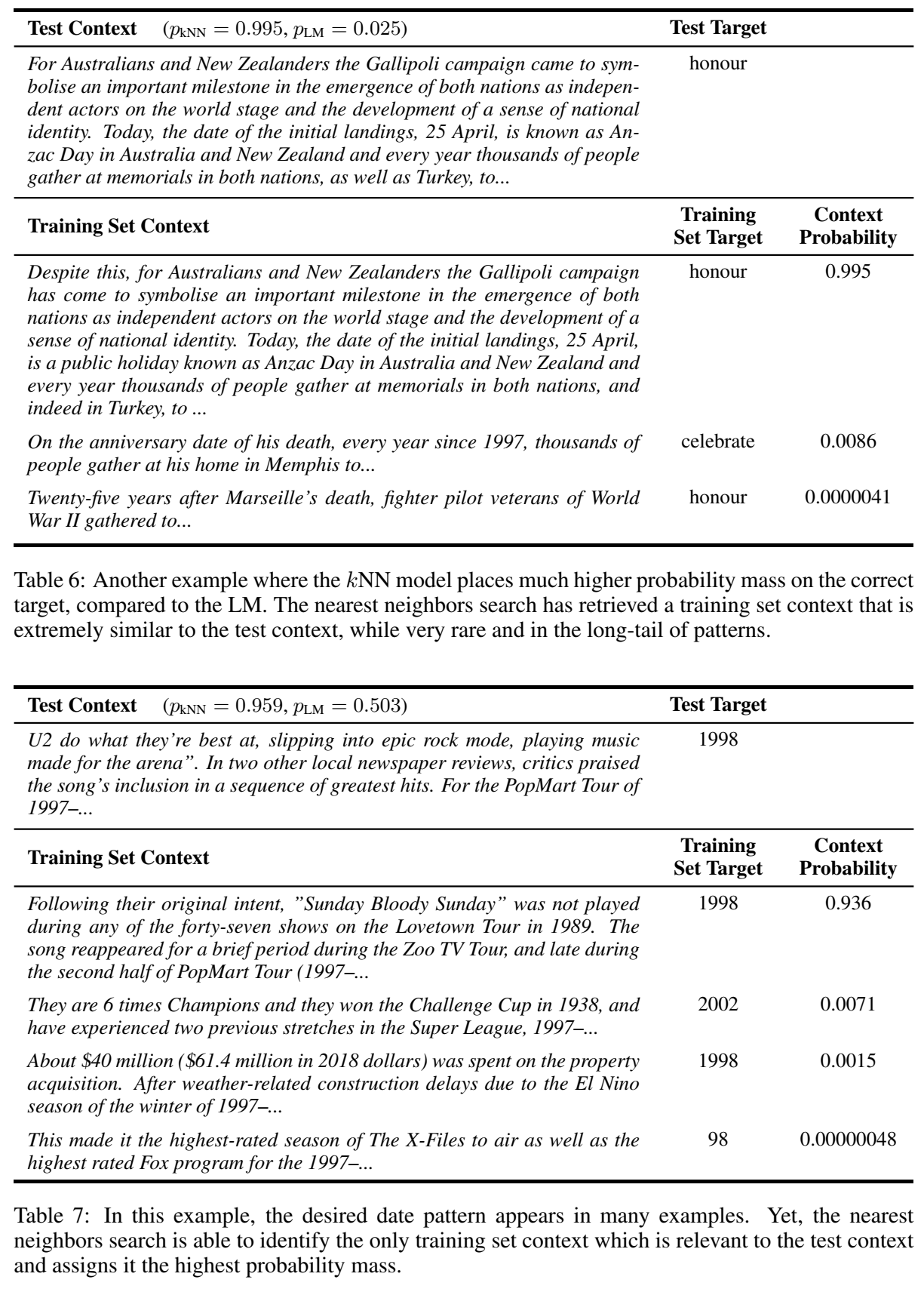
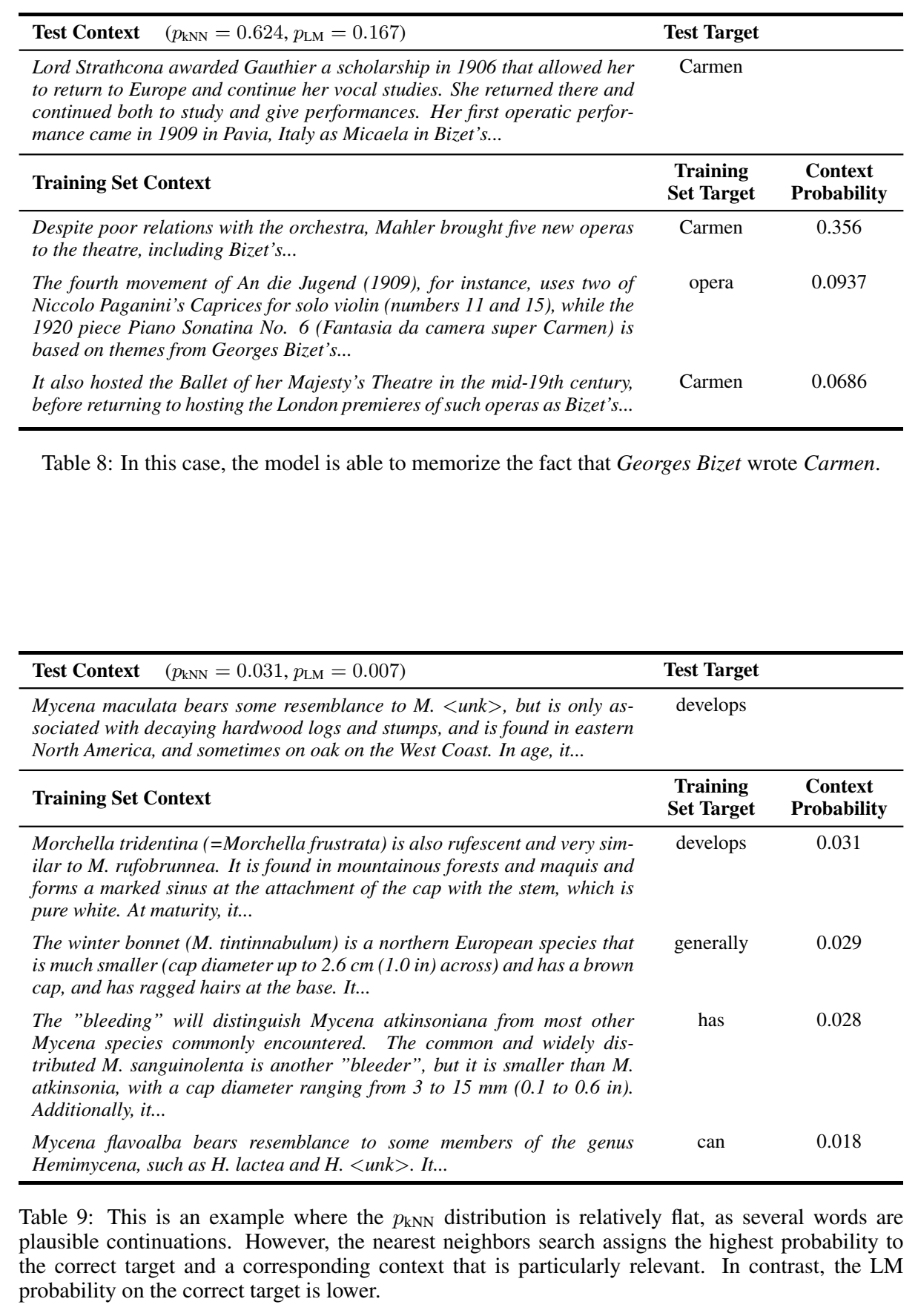
-
测试用n-gram LM代替kNN的效果:发现还是不如直接检索
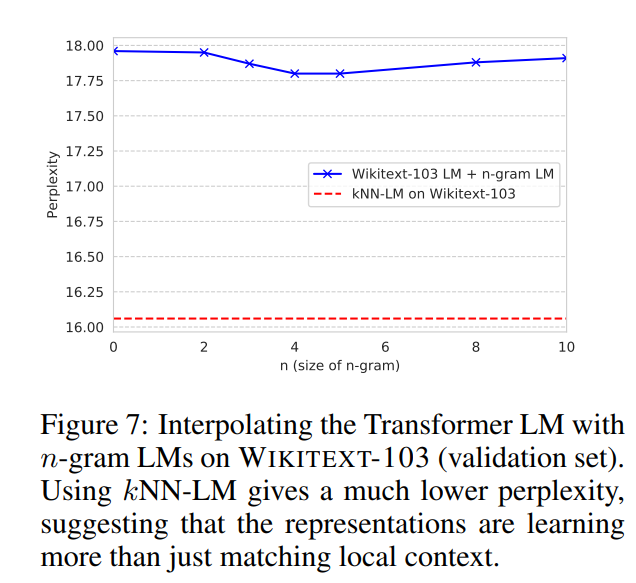
-
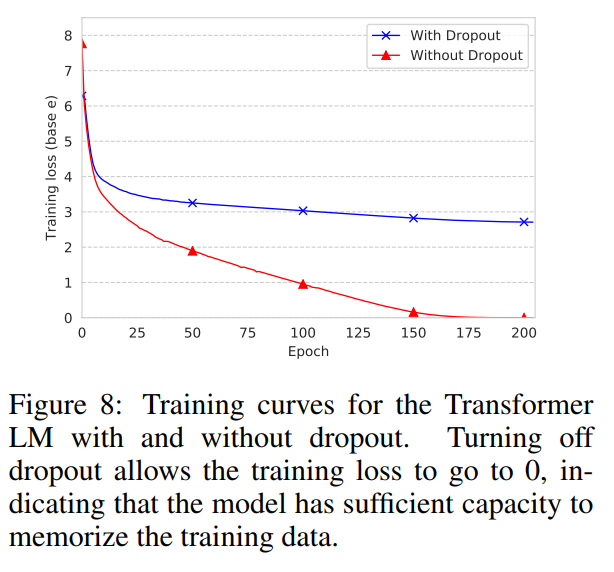
LM关闭dropout后损失函数能降到0,说明数据中的知识是都能隐式学到的
说明显式靠邻居知识的效果,不是指望LM隐式记忆就能实现的