Figure 3:提出的方法的抽象逻辑。实线表示存在大规模训练集对生成模型进行预训练,虚线表示只有很少的训练样例可用,“×” 表示生成质量差。其中
U
U
U 为对话文本,
r
e
r^e
re 为文本回复,
c
c
c 为图片描述,
r
v
r^v
rv 为图片回复,
D
C
,
D
P
,
D
~
S
{\mathcal D}_C,{\mathcal D}_P,\widetilde{\mathcal D}_S
DC,DP,DS 分别为相应的数据集 (后文有详细说明)。
Figure 2:本文多模态对话回复生成模型的整体结构。Textual Dialogue Response Generator 将文本对话上下文
U
U
U 作为输入,生成包含文本回复和图像描述的序列(例如,“a parrot with red belly and green back is standing on the railing.”(一只红腹绿背的鹦鹉正站在栏杆上))。以描述为条件,Text-to-Image Translator 生成图像表示
z
^
\hat{z}
z^。 Image Decoder
V
D
V_D
VD 将
z
^
\hat{z}
z^ 重建为逼真连续的高分辨率图像。
方法:
虽然文本对话+图片的相关数据集较少,但图片描述+图片的数据集很多
对于文本回复生成,采用常规的开放域 对话回复 生成方法
对于图片的生成,采用间接生成的策略,先依据对话文本生成 图片描述,再根据图片描述文本生成图片
采用基于 Transformer 的端到端模型 (Divter),分别单独预训练两个子模型
Text-to-Text 模型,依据对话文本生成文本回复和图片描述
Text-to-Image 模型,依据图片描述生成图片
实验结果及结论:
机器评价
文本生成任务采用 PPL、BLEU 和 Rouge 作为评价指标,图片生成任务采用 FID 和 IS 评价图片质量
Figure 2:本文多模态对话回复生成模型的整体结构。Textual Dialogue Response Generator 将文本对话上下文
U
U
U 作为输入,生成包含文本回复和图像描述的序列(例如,“a parrot with red belly and green back is standing on the railing.”(一只红腹绿背的鹦鹉正站在栏杆上))。以描述为条件,Text-to-Image Translator 生成图像表示
z
^
\hat{z}
z^。 Image Decoder
V
D
V_D
VD 将
z
^
\hat{z}
z^ 重建为逼真连续的高分辨率图像。
假设有数据集
D
S
=
{
(
U
i
,
R
i
)
}
i
=
1
n
\mathcal D_S=\{(U_i,R_i)\}_{i=1}^n
DS={(Ui,Ri)}i=1n,其中
∀
i
∈
{
1
,
…
,
n
}
\forall i \in \{1,\ldots, n\}
∀i∈{1,…,n},
U
i
=
{
u
i
,
1
,
…
,
u
i
,
n
i
}
U_i=\{u_{i,1}, \ldots, u_{i,n_i}\}
Ui={ui,1,…,ui,ni} 是对话上下文,
u
i
,
j
u_{i,j}
ui,j 是第
j
j
j 个 utterance,
R
i
R_i
Ri 是关于
U
i
U_i
Ui 的回复。
u
i
,
j
u_{i,j}
ui,j 和
R
i
R_i
Ri 可以包含两种模态:文本 和 图像。目标是使用
D
S
\mathcal D_S
DS 来学习一个生成模型
P
(
R
∣
U
;
θ
)
P(R\mid U;\theta)
P(R∣U;θ),其中
θ
\theta
θ 为模型参数。因此,给定一个新的对话上下文
U
U
U,可以通过
P
(
R
∣
U
;
θ
)
P(R\mid U;\theta)
P(R∣U;θ) 生成一个多模态回复
R
R
R。
图像的 tokenization 是一个离散 Auto-Encoder (VQGAN, https://github.com/CompVis/taming-transformers)
V
\mathcal V
V,如图2所示。
V
\mathcal V
V 利用编码器
V
E
{\mathcal V}_E
VE 将形状为
H
×
W
×
3
H\times W \times 3
H×W×3 的每个图像
r
v
r^v
rv 压缩成形状为
h
×
w
×
d
z
h \times w \times d_z
h×w×dz 的
z
^
\hat z
z^,然后在 element-wise 量化 q(·) 的作用下,将每个维数为
d
z
d_z
dz 的向量在学习的离散 codebook
Z
=
{
z
k
}
k
=
1
K
∈
R
d
z
\mathcal Z=\{z_k\}_{k=1}^K \in {\mathbb R}^{d_z}
Z={zk}k=1K∈Rdz 中量化到其最接近 embedding
z
k
z_k
zk。
z
q
=
q
(
z
^
)
:
=
(
a
r
g
m
i
n
z
k
∈
Z
∥
z
^
i
j
−
z
k
∥
)
∈
R
h
×
w
×
d
z
(1)
\tag{1} z_{\bf q}={\bf q}(\hat z):= \left( \underset{z_k \in \mathcal Z}{\rm arg\ min}\lVert \hat z_{ij}-z_k \rVert \right) \in \mathbb R^{h \times w \times d_z}
zq=q(z^):=(zk∈Zargmin∥z^ij−zk∥)∈Rh×w×dz(1) 因此
r
v
r^v
rv 可以用 codebook
z
q
∈
R
h
×
w
×
d
z
z_{\bf q}\in \mathbb R^{h\times w\times d_z}
zq∈Rh×w×dz 的空间集合来表示。解码器
V
D
{\mathcal V}_D
VD 将
z
q
z_{\bf q}
zq 映射回图像
r
v
^
\hat{r^v}
rv^ 用来重建输入。在本工作中,
H
=
W
=
256
H=W=256
H=W=256,
h
=
w
=
16
h=w=16
h=w=16,
K
=
16384
K=16384
K=16384,
d
z
=
256
d_z=256
dz=256。
V
\mathcal V
V 和
Z
\mathcal Z
Z 的实现细节可以在 Zero-Shot Text-to-Image Generation 中找到。
Figure 3:提出的方法的抽象逻辑。实线表示存在大规模训练集对生成模型进行预训练,虚线表示只有很少的训练样例可用,“×” 表示生成质量差。其中
U
U
U 为对话文本,
r
e
r^e
re 为文本回复,
c
c
c 为图片描述,
r
v
r^v
rv 为图片回复,
D
C
,
D
P
,
D
~
S
{\mathcal D}_C,{\mathcal D}_P,\widetilde{\mathcal D}_S
DC,DP,DS 均为数据集,下文有详细说明。
纯文本对话:例如,Reddit comments,表示为
D
C
=
{
(
U
i
,
r
i
e
)
}
i
=
1
N
{\mathcal D}_C=\{(U_i,r_i^e)\}_{i=1}^N
DC={(Ui,rie)}i=1N,其中
(
U
i
,
r
i
e
)
(U_i,r_i^e)
(Ui,rie) 是一个 <text dialogue context, text response> pair)
<image description, image> pairs:例如,YFCC100M,表示为
D
P
=
{
(
c
j
,
r
j
v
)
}
j
=
1
M
{\mathcal D}_P=\{(c_j,r_j^v)\}_{j=1}^M
DP={(cj,rjv)}j=1M,其中
(
c
j
,
r
j
v
)
(c_j,r_j^v)
(cj,rjv) 是一个 <textual image-description, image> pair。
(i) 如果多模态对话上下文包含一个图像,我们就用它的描述来代替原本的图像,形成一个纯文本的语境,并将这个上下文作为纯文本对话生成模型
G
\mathcal G
G 的输入,其中
G
\mathcal G
G 使用
D
C
\mathcal D_C
DC 预训练。
(ii) 如果需要生成图像作为回复的一部分,我们可以先用
G
\mathcal G
G 来生成文本形式的描述,然后用 text-to-image 转换模块
F
\mathcal F
F (用
D
P
\mathcal D_P
DP 预训练) 将描述转换成同义图像。为了桥接
G
\mathcal G
G 和
F
\mathcal F
F,我们进一步将
D
S
\mathcal D_S
DS 的形式扩展为一个新的
D
~
S
\widetilde{\mathcal D}_S
DS,其中每个图像
r
v
r^v
rv 与其文本描述
c
c
c 配对。
(i) 和 (ii) 都可以独立学习,这成为用大的
D
C
\mathcal D_C
DC 和
D
P
\mathcal D_P
DP 辅助小的
D
~
S
\widetilde{\mathcal D}_S
DS 的关键。
通过这种方法,当前的目标是学习一个具有
D
=
{
D
~
S
,
D
C
,
D
P
}
\mathcal D=\{\widetilde{\mathcal D}_S, \mathcal D_C, \mathcal D_P\}
D={DS,DC,DP} 的生成模型
P
(
R
∣
U
;
θ
)
P(R\mid U;\theta)
P(R∣U;θ)。利用预训练好的
G
\mathcal G
G 和
F
\mathcal F
F,最终使用
D
~
S
\widetilde{\mathcal D}_S
DS 对
G
\mathcal G
G 和
F
\mathcal F
F 联合地 finetune,以获得生成多模态回复的能力。
Figure 2 阐述了 Divter 的结构。该模型又两个部分组成:一个文本对话回复生成器
G
\mathcal G
G 和 一个 text-to-image 转换器
F
\mathcal F
F。
文本对话回复生成器
G
\mathcal G
G 是一个基于 Transformer 的sequence-to-sequence 模型,它由一个 24 层的 Transformer (其中隐藏大小为 1024 且有 16 个头) 组成。具体地说,给定一个来源于
D
~
S
\widetilde D_S
DS 的文本对话上下文
U
=
{
u
1
,
…
,
u
l
}
U=\{u_1,\ldots,u_l\}
U={u1,…,ul},目标是一个文本
R
~
=
{
w
1
,
⋯
,
[
S
E
P
]
,
[
D
S
T
]
,
⋯
,
[
S
E
P
]
,
⋯
,
w
T
}
\widetilde R=\{w_1,\cdots,{\rm [SEP],[DST],\cdots,[SEP],\cdots},w_T\}
R={w1,⋯,[SEP],[DST],⋯,[SEP],⋯,wT},其中
w
t
w_t
wt 是第
t
t
t 个单词,
[
D
S
T
]
\rm [DST]
[DST] token 表示接下来的子序列是一个文本形式的图像描述
c
c
c。生成器的 loss 被定义为:
L
G
=
E
(
U
,
R
~
)
∼
D
~
S
[
−
log
p
(
R
~
)
]
(2)
\tag{2} \mathcal{L_G}=\mathbb E_{(U,\widetilde R)\sim\widetilde D_S} [-\log p(\widetilde R)]
LG=E(U,R)∼DS[−logp(R)](2)
p
(
R
~
)
=
∏
t
p
(
w
t
∣
U
,
w
1
:
t
−
1
)
(3)
\tag{3} p(\widetilde R)=\prod_t p(w_t|U,w_{1:t-1})
p(R)=t∏p(wt∣U,w1:t−1)(3)
推理: 给定一个新的文本对话上下文
U
U
U,当一个生成的图像描述
c
c
c 出现时,它将被送入后面的 text-to-image 转换器,然后构造其同义图像的 codebook embeddings。
text-to-image 转换器
F
\mathcal F
F 也是一个基于 Transformer 的 sequence-to-sequence 生成模型,它由一个 24 层的 Transformer (其中隐藏大小为 1024 且有 16 个注意力头) 组成。给定一个图像
r
v
∈
R
H
×
W
×
3
r^v\in \mathbb R^{H\times W\times 3}
rv∈RH×W×3 及其来源于
D
~
S
\widetilde D_S
DS 的文本描述
c
=
{
w
1
,
⋯
,
w
T
}
c=\{w_1,\cdots,w_T\}
c={w1,⋯,wT},在
V
E
\mathcal V_E
VE 和
Z
\mathcal Z
Z 可用的情况下,我们可以用编码的 codebook 索引来表示
r
v
r^v
rv。更准确地说,图像
r
v
r^v
rv 的量化编码由
z
q
=
q
(
V
E
(
r
v
)
)
∈
R
h
×
w
×
d
z
z_{\bf q}={\bf q}(\mathcal V_E(r^v)) \in \mathbb R^{h\times w\times d_z}
zq=q(VE(rv))∈Rh×w×dz 给出,并且可以转换为 codebook
Z
\mathcal Z
Z 中的索引序列
s
∈
{
0
,
⋯
,
∣
Z
∣
−
1
}
h
×
w
s\in \{0,\cdots,|\mathcal Z|-1\}^{h\times w}
s∈{0,⋯,∣Z∣−1}h×w,该序列通过 codebook
Z
\mathcal Z
Z 中的索引替换每一个 code 而获得。
s
i
,
j
=
k
s
u
c
h
t
h
a
t
(
z
q
)
i
,
j
=
z
k
(4)
\tag{4} s_{i,j}=k\quad {\rm such\ that}\quad (z_{\bf q})_{i,j}=z_k
si,j=ksuchthat(zq)i,j=zk(4) 然后将 tokenize 后的
c
c
c 和
s
s
s concat 到一个单个的 token 流中:
x
=
{
w
1
,
⋯
,
w
T
,
[
S
E
P
]
,
s
1
,
⋯
,
s
h
×
w
}
(5)
\tag{5} x=\{w_1,\cdots,w_T,{\rm [SEP]},s_1,\cdots,s_{h\times w}\}
x={w1,⋯,wT,[SEP],s1,⋯,sh×w}(5) 训练一个自回归 Transformer 来模拟文本和图像 token 的联合分布,生成器的 loss 被定义为:
L
F
=
E
(
c
,
r
v
)
∼
D
~
S
[
−
log
p
(
x
)
]
(6)
\tag{6} \mathcal{L_F}=\mathbb E_{(c,r^v)\sim\widetilde D_S} [-\log p(x)]
LF=E(c,rv)∼DS[−logp(x)](6)
p
(
x
)
=
∏
t
p
(
w
t
∣
w
1
:
t
−
1
)
∏
i
p
(
s
i
∣
c
,
s
1
:
i
−
1
)
(7)
\tag{7} p(x)=\prod_t p(w_t|w_{1:t-1})\prod_i p(s_i|c,s_{1:i-1})
p(x)=t∏p(wt∣w1:t−1)i∏p(si∣c,s1:i−1)(7)
推理: 给定一个描述
c
c
c,利用 text-to-image 转换器生成其同义图像的表征
z
^
=
F
(
c
)
∈
R
h
×
w
×
d
z
\hat z=\mathcal F(c)\in \mathbb R^{h\times w\times d_z}
z^=F(c)∈Rh×w×dz。
4.2.3 学习细节
定义
{
θ
g
,
θ
π
,
θ
ϕ
}
\{\theta_g,\theta_{\pi},\theta_{\phi}\}
{θg,θπ,θϕ} 分别为 文本对话回复生成器
G
\mathcal G
G,图像 tokenizer
V
\mathcal V
V 和 text-to-image 转换器
F
\mathcal F
F 的参数。在预训练阶段,使用文本对话
D
C
\mathcal D_C
DC 来评估
θ
g
\theta_g
θg,用 ImageNet 来评估
θ
π
\theta_{\pi}
θπ,用 <image description, image> pairs
D
P
\mathcal D_P
DP 来评估
θ
ϕ
\theta_{\phi}
θϕ。然后拟合
θ
π
\theta_{\pi}
θπ,并用
D
~
S
\widetilde D_S
DS 将
θ
g
\theta_g
θg 和
θ
ϕ
\theta_{\phi}
θϕ 联合 finetune,因此最终目标是最小化整体 loss:
L
=
L
G
+
λ
L
F
(8)
\tag{8} \mathcal L=\mathcal L_{\mathcal G}+\lambda \mathcal L_{\mathcal F}
L=LG+λLF(8) 其中
λ
\lambda
λ 是一个超参数。
作者还将纯文本 Divter 和多模态 Divter 分别与 DialoGPT 进行比较。纯文本 Divter 意味着我们在解码阶段屏蔽词汇表中的
[
D
S
T
]
\rm[DST]
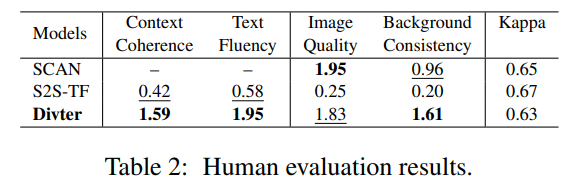
[DST] token,使回复中只包含文本。我们还随机抽取了 200 个对话。对于每一个注释者,来自不同模型的两个回复被提出,这两个回复被随机打乱以隐藏他们的来源。然后,注释者判断哪种回复更能有效地提高对话的体验和吸引力。注释者之间的一致性是通过 Fleiss’s Kappa 来衡量的。
5.3 实现细节
对于文本对话回复生成器
G
\mathcal G
G,使用 DialoGPT 作为预训练模型初始化,在 2005 年到 2017 年的 Reddit 评论链中提取的 147M 对话式交流中训练。在 fine-tune 阶段,用
[
S
E
P
]
\rm[SEP]
[SEP] concat 上下文的单个序列,采用 Adam 优化器且初始学习率为 1e-5,batch size 设为 256。使用 beam search (size=5) 来解码文本序列。
对于图像 tokenizer
V
\mathcal V
V,直接使用 VQGAN。
对于 text-to-image 转换器
F
\mathcal F
F,作者随机选取了 5M 个来源于 ImageNet 中的 <categorical image description, image> pairs 和来源于 YFCC100M 中的 <image description, image> pairs 作为训练数据。将最大图像描述长度设置为 32,batch size 设为 256,预训练
F
\mathcal F
F 3.5million 个 step。在 fine-tune 阶段,训练 PhotoChat 50000 个 step。 在推理阶段,使用 CLIP 对生成的 256 个样本进行重新排序。
在联合学习中,先训练
F
\mathcal F
F 48000 个 step,然后联合训练
G
\mathcal G
G 和
F
\mathcal F
F 2000 个 step。公式 KaTeX parse error: Undefined control sequence: \eqref at position 1: \̲e̲q̲r̲e̲f̲{eq:8} 中的
λ
\lambda
λ 为 0.2。验证时 early stopping 是一种规范的策略,所有的超参数都是通过 grid search 来确定。更多细节参考附件 A.3。
A.3 More Implementation Details
CLIP 模型根据图像与描述的匹配程度给出评分,并利用 CLIP 对生成的256个样本进行重新排序,选择最佳的图像作为最终的回复。为了获得高质量的训练集,丢弃了描述中以 “The photo has your * #” 为前缀的样例,其中 “*” 包括 “mom”,“dad”,“daughter”,“sister”,“uncle”等,“#” 是一个人的名字。 为了从ImageNet 中构建 text-to-image 转换器
F
\mathcal F
F 的训练集,我们结合文本 ““Objects in the photo:” 和每个图像的文本分类名称来构建 <categorical image description, image> pair。为了训练 baseline S2S-TF 模型,我们还使用图像 tokenizer
V
\mathcal V
V 对每个图像进行 tokenize,并将图像 tokens 与文本 tokens 结合形成单一流作为生成的来源或目标。
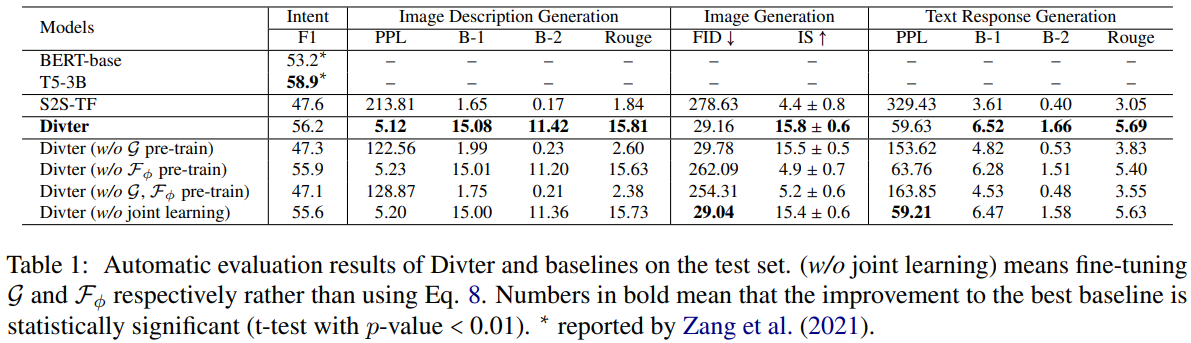
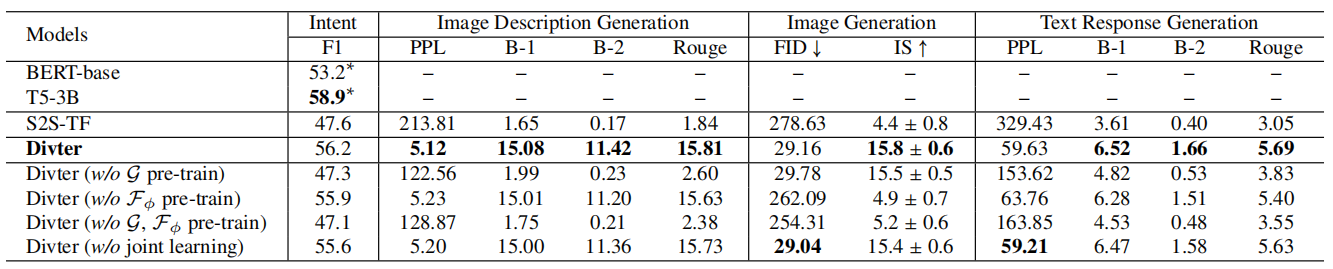
Table 1:测试集上 Divter 和 baseline 的自动评价结果。(
w
/
o
w/o
w/o joint learning) 表示分别 fine-tune
G
\mathcal G
G 和
F
\mathcal F
F,而不是使用公式 (8)。
如 Table 1 所示,所有变体都在大多数评价指标中的性能更差。
Figure 4:在 PhotoChat 测试集中,输入相同的上下文对图像生成的各种变体进行定性评估。第1列:Divter。 第2列:Divter
w
/
o
G
w/o\ \mathcal G
w/oG pre-train。 第3列:Divter
w
/
o
F
w/o\ \mathcal F
w/oF pre-train。