一、以前用的数据集格式:
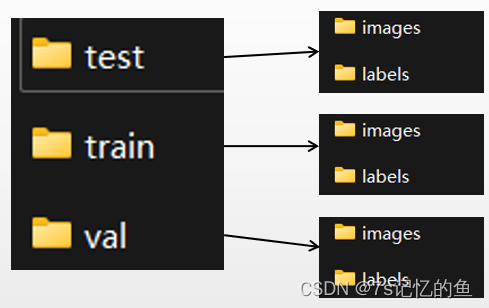
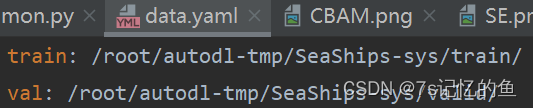
训练集、测试集的图片和标签分别放在对应的文件夹里,这就导致一个问题,如果相对数据集多次随机划分的话,就要多次从总的图片和标签中选择出需要的图片和标签,并且保存到相应的文件夹中。这样会很麻烦,而且浪费时间。
二、改进
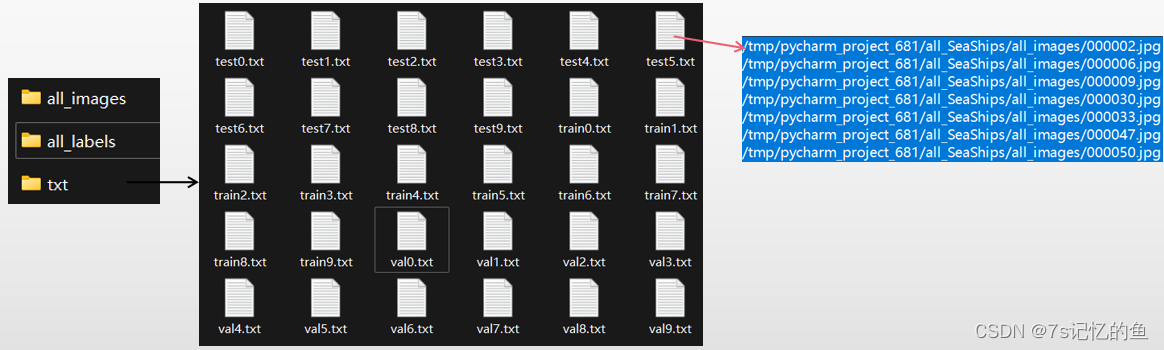

将划分为训练集、测试集和验证集的文件路径分别写入对应的txt文件,YOLOV5的代码不用修改。
**注:**这我上面的两个文件夹名称最好还是换成images和labels;或者改一下程序里面两个位置,如下红框:
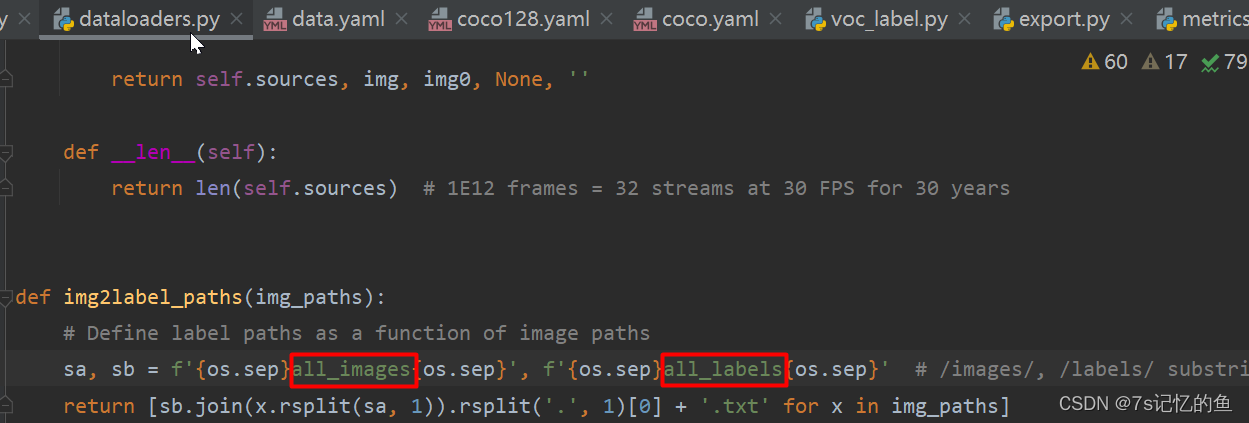
这里的脚本就是对数据集进行多少次随机划分。
脚本代码:
import os
import random
import argparse
parser = argparse.ArgumentParser()
# 1.xml/其他 文件的文件夹路径,根据自己的数据进行修改。 #1 改为自己的
parser.add_argument('--images_path', default='D:\\数据集\\dataset\\SeaShips(7000)\\SeaShip_data\\all_SeaShips\\images', type=str, help='input xml label path')
# 2.保存 数据集划分生成的txt文件 的文件夹路径。 #2 改为自己的
parser.add_argument('--txt_path', default='C:\\Users\\14667\\Desktop\\SeaShip_new\\txt', type=str, help='output txt label path')
opt = parser.parse_args()
trainval_percent = 1.0 # 3.训练+验证集一共所占的比例,剩下的就是测试集了。 #3 所占的比例
train_percent = 0.9 # 4.训练集在训练集和验证集总集合中占的比例 #4 所占的比例
xmlfilepath = opt.images_path
txtsavepath = opt.txt_path
total_xml = os.listdir(xmlfilepath)
if not os.path.exists(txtsavepath):
os.makedirs(txtsavepath)
num = len(total_xml)
list_index = range(num)
tv = int(num * trainval_percent)
tr = int(tv * train_percent)
# file_trainval = open(txtsavepath + '/trainval.txt', 'w')
def txt_num(x): #进行x次随机划分
for i1 in range(x):
trainval = random.sample(list_index, tv)
train = random.sample(trainval, tr)
file_test = open(txtsavepath + '/test{}.txt'.format(i1), 'w')
file_train = open(txtsavepath + '/train{}.txt'.format(i1), 'w')
file_val = open(txtsavepath + '/val{}.txt'.format(i1), 'w')
for i2 in list_index:
# 5.total_xml[i2][:-4]:-4可以用来去掉文件后缀名
name = "/tmp/pycharm_project_681/all_SeaShips/images/" + total_xml[i2][:] + '\n' #5 路径改为自己的
if i2 in train:
file_train.write(name)
else:
file_val.write(name)
file_test.write(name)
file_train.close()
file_val.close()
file_test.close()
if __name__ == "__main__":
txt_num(10) #进行10次随机划分 #6 次数改为自己的
一共改6处
查看每次划分后每个类别分布在训练集、测试集和验证集中是否与总的数据集分布相似,代码如下:
from utils.dataloaders import LoadImagesAndLabels
import numpy as np
if __name__ == '__main__':
for i in range(10):
class0, class1, class2, class3, class4, class5 = 0, 0, 0, 0, 0, 0 # 1
names = ['ore carrier', 'bulk cargo carrier', 'fishing boat', 'container ship', 'passenger ship', 'general cargo ship'] #2
# 存放txt文件的路径
dataset = LoadImagesAndLabels(path=["C:/Users/14667/Desktop/SeaShip_new/txt1/train{}.txt".format(i)]) #3
labels = np.concatenate(dataset.labels, 0) # 相当于把每张图片中的多个标签转化为了一个个的标签
# print(len(labels))
for label in labels:
if label[0] == 0:
class0 += 1
if label[0] == 1:
class1 += 1
if label[0] == 2:
class2 += 1
if label[0] == 3:
class3 += 1
if label[0] == 4:
class4 += 1
if label[0] == 5:
class5 += 1
print("{:.2f}".format(class0/class0), "{:.2f}".format(class1/class0), "{:.2f}".format(class2/class0), "{:.2f}".format(class3/class0), "{:.2f}".format(class4/class0), "{:.2f}".format(class5/class0), class0+class1+class2+class3+class4+class5)