标签: java spring
文章目录
1.什么是循环依赖
所所谓的循环依赖是指,A 依赖 B,B 又依赖 A,它们之间形成了循环依赖。或者是 A 依赖 B,B 依赖 C,C 又依 赖 A。它们之间的依赖关系如下:
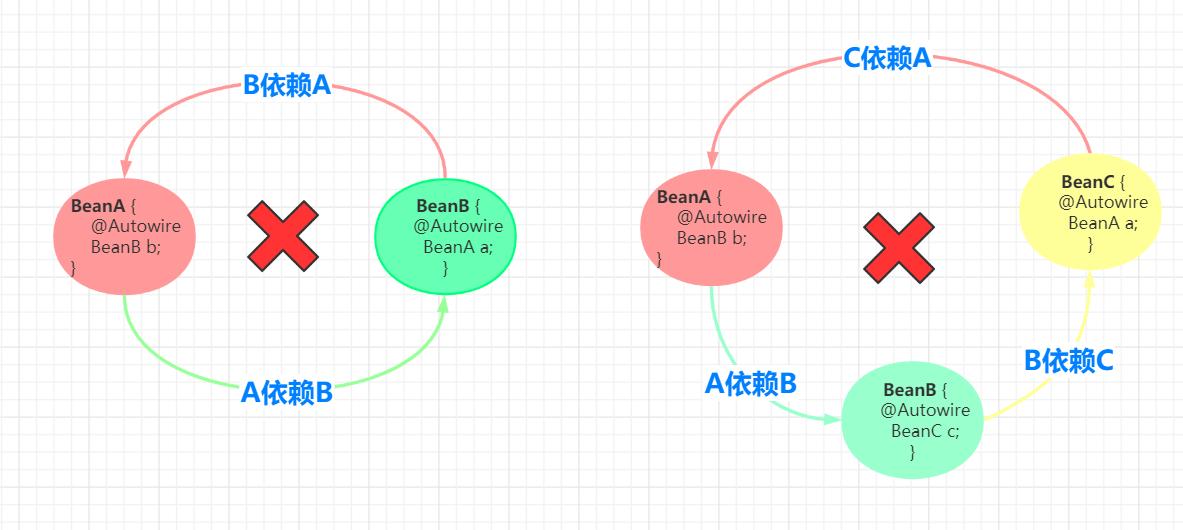
循环依赖代码如下:
public class InstanceA {
@Autowired
private InstanceB instanceB; // InstanceA中依赖InstanceB
}
public class InstanceB {
@Autowired
private InstanceA instanceA; // InstanceB中依赖InstanceA
}
无论先创建InstanceA还是InstanceB时,都会发生循环依赖!
2.解决循环依赖思路
为了更加理解循环依赖的解决思路,尝试通过手写伪代码代码来实现Bean的初始化过程,在这之前先分析一下一、二、三级缓存 存在的意义,以及解决了什么问题吧!
只使用一级缓存时:
先看一下流程图:中间的闭环就是循环依赖
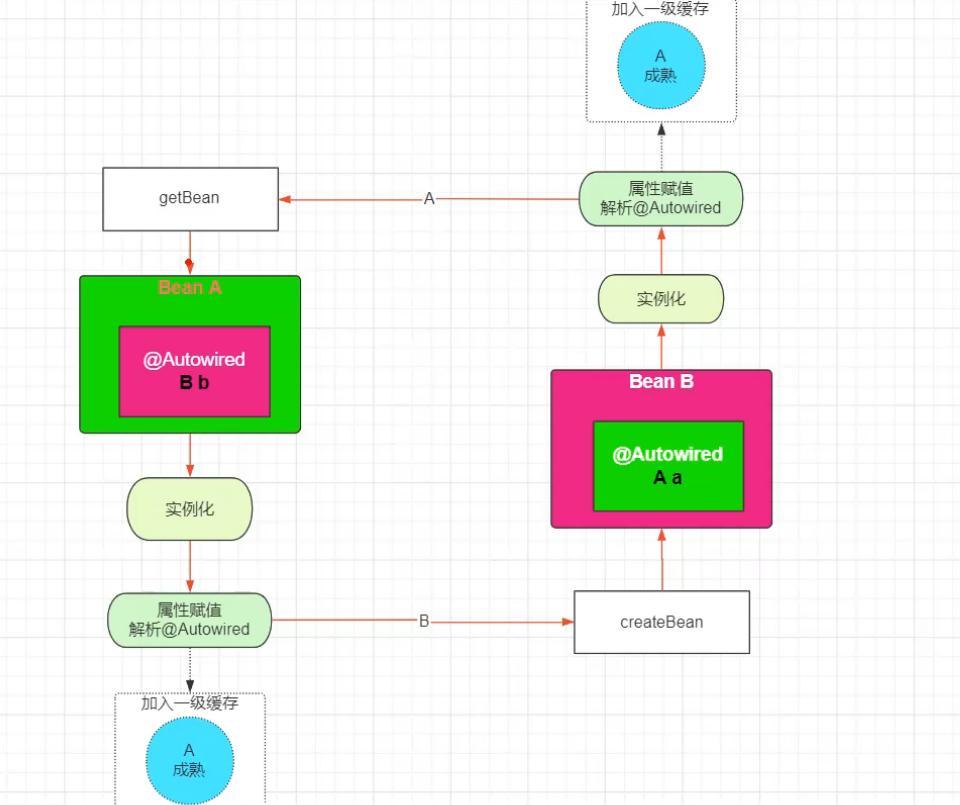
为了解决循环依赖导致的闭环问题,我们可以在闭环中增加一个出口,具体做法是:修改把bean放入一级缓存的时机,以前是属性赋值、初始化完成后才放进去,现修改为实例化完成后就先加入缓存中。并在获取某个对象时先去一级缓存中找一下,找到了直接返回,这样可以解决单线程的缓存依赖!如图所示
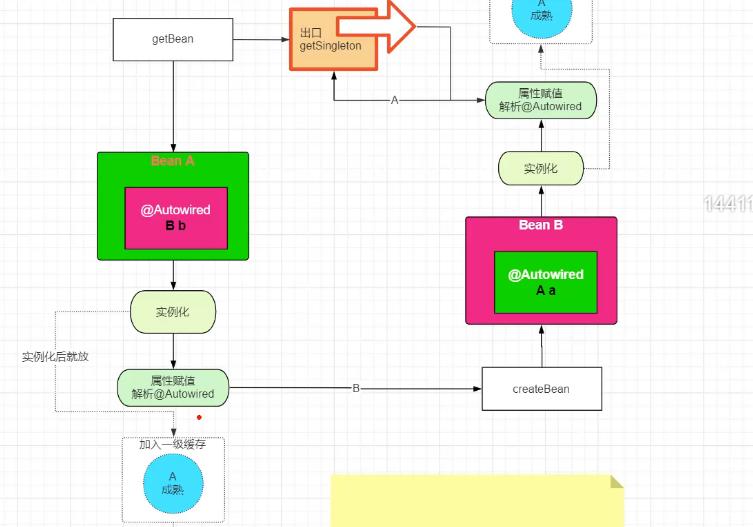
但是这里又会带来一个新的问题,就是在多线程模式下,如果别的线程从一级缓存中获取到的是实例化后的类,这样明显是不可行的,因为这个类并不完整,是纯净的Bean,属性并没有真正被赋值!为了解决这个问题,二级缓存应运而生。
为什么要使用二级缓存?
二级缓存作用是:暴露早期对象,为了将成熟bean 和 纯净bean 分离。防止多线程中在Bean还未创建完成时读取到的Bean是不完整的。
还有一点关于bean的Aop动态代理的问题,我们都知道Bean的aop动态代理创建是在初始化之后,但是循环依赖的Bean如果使用了AOP。 那无法等到解决完循环依赖再创建动态代理, 因为这个时候已经注入属性。 所以如果循环依赖的Bean使用了aop. 需要提前创建aop。
3.二级缓存能否解决循环依赖,三级缓存存在的意义
首先说明一下一二三级缓存的意义:
三级缓存分别是:
-
singletonObject:一级缓存,该缓存key = beanName, value = bean;这里的bean是已经创建完成的,该bean经历过实例化->属性填充->初始化以及各类的后置处理。因此,一旦需要获取bean时,我们第一时间就会寻找一级缓存
-
earlySingletonObjects:二级缓存,该缓存key = beanName, value = bean;这里跟一级缓存的区别在于,该缓存所获取到的bean是提前曝光出来的,是还没创建完成的。也就是说获取到的bean只能确保已经进行了实例化,但是属性填充跟初始化肯定还没有做完,因此该bean还没创建完成,仅仅能作为指针提前曝光,被其他bean所引用
-
singletonFactories:三级缓存,不是用来存bean的实例,而是用来存函数接口、钩子函数的!该缓存key = beanName, value =beanFactory;在bean实例化完之后,属性填充以及初始化之前,如果允许提前曝光,spring会将实例化后的bean提前曝光,也就是把该bean转换成beanFactory并加入到三级缓存。在需要引用提前曝光对象时再通过singletonFactory.getObject()获取。
这里抛出问题,如果我们直接将提前曝光的对象放到二级缓存earlySingletonObjects,Spring循环依赖时直接取就可以解决循环依赖了,为什么还要三级缓存singletonFactory然后再通过getObject()来获取呢?这不是多此一举?
我们回到添加三级缓存,添加SingletonFactory的地方,看看getObject()到底做了什么操作
this.addSingletonFactory(beanName, () -> {
return this.getEarlyBeanReference(beanName, mbd, bean);
});
可以看到在返回getObject()时,多做了一步getEarlyBeanReference操作,这步操作是BeanPostProcess的一种,也就是给子类重写的一个后处理器,目的是用于被提前引用时进行拓展。即:曝光的时候并不调用该后置处理器,只有曝光,且被提前引用的时候才调用,确保了被提前引用这个时机触发。
4.多例和构造器为什么无法解决循环依赖
为什么多例Bean不能解决循环依赖?
我们自己手写了解决循环依赖的代码,可以看到,核心是利用一个map,来解决这个问题的,这个map就相当于缓存。
为什么可以这么做,因为我们的bean是单例的,而且是字段注入(setter注入)的,单例意味着只需要创建一次对象,后面就可以从缓存中取出来,字段注入,意味着我们无需调用构造方法进行注入。
如果是原型bean,那么就意味着每次都要去创建对象,无法利用缓存;
如果是构造方法注入,那么就意味着需要调用构造方法注入,也无法利用缓存。
为什么Spring不能解决构造器的循环依赖?
因为构造器是在实例化时调用的,此时bean还没有实例化完成,如果此时出现了循环依赖,一二三级缓存并没有Bean实例的任何相关信息,在实例化之后才放入三级缓存中,因此当getBean的时候缓存并没有命中,这样就抛出了循环依赖的异常了。
5.如何进行扩展
6. SPRING在创建BEAN的时候,在哪里创建的动态代理?
①:如果没有循环依赖的话,在bean初始化完成后创建动态代理
②:如果有循环依赖,在bean实例化之后创建!