1、实验内容:
(1) numpy数组的建立、索引、计算、统计等。
(2) 利用numpy对数据集“iris.data”进行分析。
2、实验过程:
2.1 numpy数组的建立、索引、计算、统计等
(1)numpy数组分析
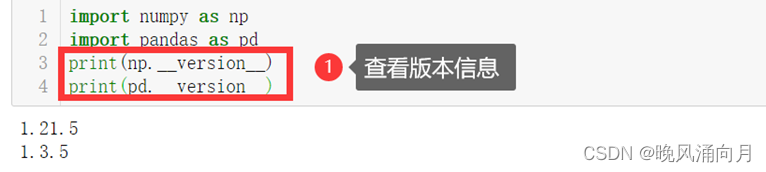
①查看版本信息
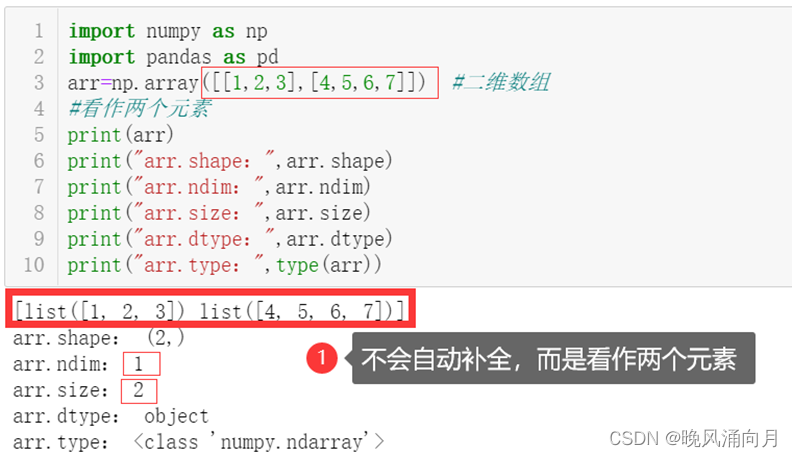
②数组属性


(2) numpy数组的建立
①有规则数组:
Ⅰ、arange(起点,终点,步长) 起点与终点可省,步长不可省



Ⅱ、np.linspace(起点,终点,等分数)
结果是左闭右闭的区间,即起点与终点都可以取到

Ⅲ、数组数据类型的转变


②无规则(随机)数组
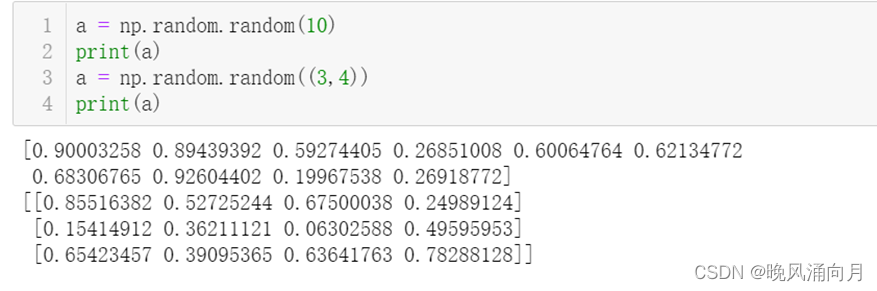
Ⅰ、创建无约束随机数组
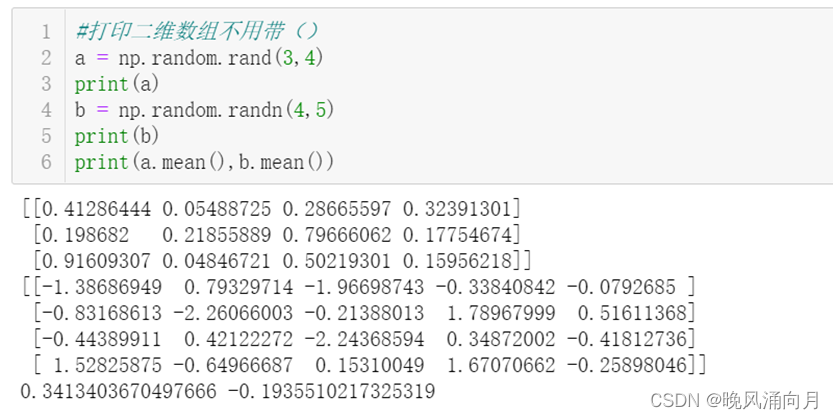
Ⅱ、创建均匀分布随机数组:每一段出现的概率均等

Ⅲ、正态分布随机数组

Ⅳ、均匀分布与正态分布的二维数组
Ⅴ、randint:产生随机整数。randint(起点,终点,size)

Ⅵ、shuffle:打乱顺序;reshape:改变形状。


③全0数组

④全1数组


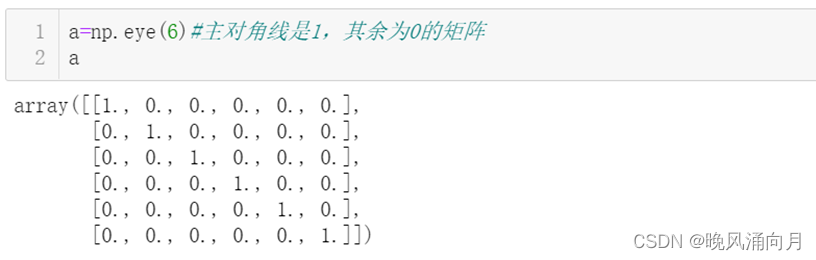
⑤创建主对角线是1,其余为0的矩阵
⑥概率划分(抽奖问题)
random.choice(整数或序列,size,p)
一般不给定p,此时默认为等概率划分

(3) numpy数组的索引
①简单索引分析


②根据索引,挑选一维数组中符合要求的数

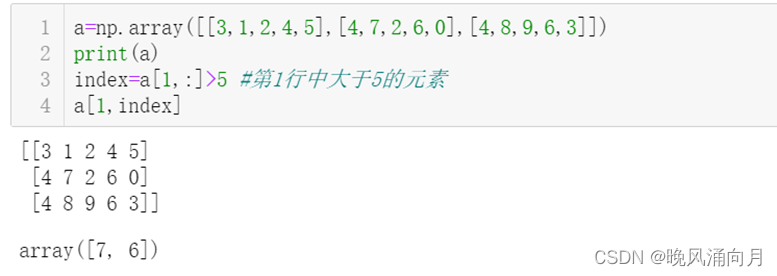
③根据索引,挑选二维数组中符合要求的数


④替换指定值

⑤改变数组的形状

⑥多维数组的展平


(4) numpy数组的计算
①相同形状数组的运算



②列表不能加减数字

③不同形状的数组不能相加减乘除

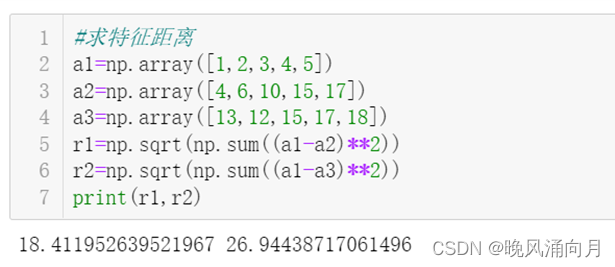
④特征计算

⑤简单统计

(5)numpy数组的统计
①删除带有空值的行

②列均值替代nan,如果整列是nan,则删除该列

2.2 利用numpy对数据集“iris.data”进行分析
Numpy综合练习:鸢尾花数据集分析(题目)
Tip——样本标准化:(真实值-最小值)/(最大值-最小值)【极差】
任务一:
①读出数据,计算四列数据中任一列的平均值、中位值、标准差、并将其标准化(将其值转为0~1范围内的标准值)
#读出数据,将第0列花萼长度放入数组len中
import numpy as np
iris=np.loadtxt("D:/python_files/iris-20.data",delimiter=',',dtype='object')
len=iris[:,0] #读出0列,花萼长度
len=np.float64(len) #强制类型转换,转化为浮点数
#计算花萼长度的均值,中位值,标准差
means=np.mean(len)
len_std=(len-len.min())/(len.max()-len.min()) #样本标准化
len_std=np.round(len_std,2) #round表示四舍五入,2表示小数精度
#计算标准化数据,将数据插入到原数组
iris=np.insert(iris,4,len_std,axis=1)#20个数据--20行--维度为1
②以某列为主关键字,对数组排序
#2.以刚插入的标准值(第4列)为关键字,按列排序
#以新增列为关键字,对数组排序
seq=np.argsort(iris[:,4])
iris[seq]
#写文件
np.savetxt("D:/python_files/temp.txt",iris[seq],fmt="%s")
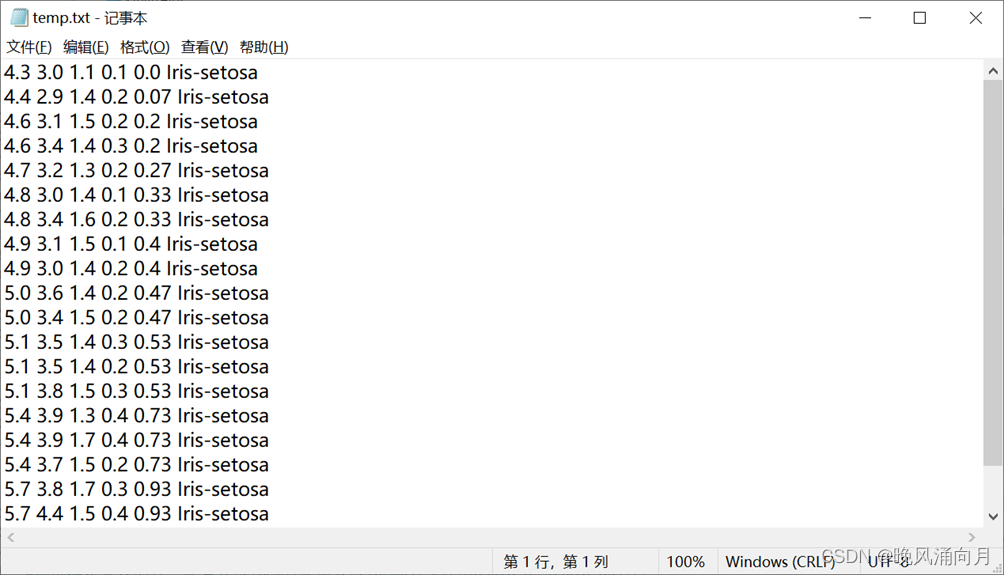
任务二:
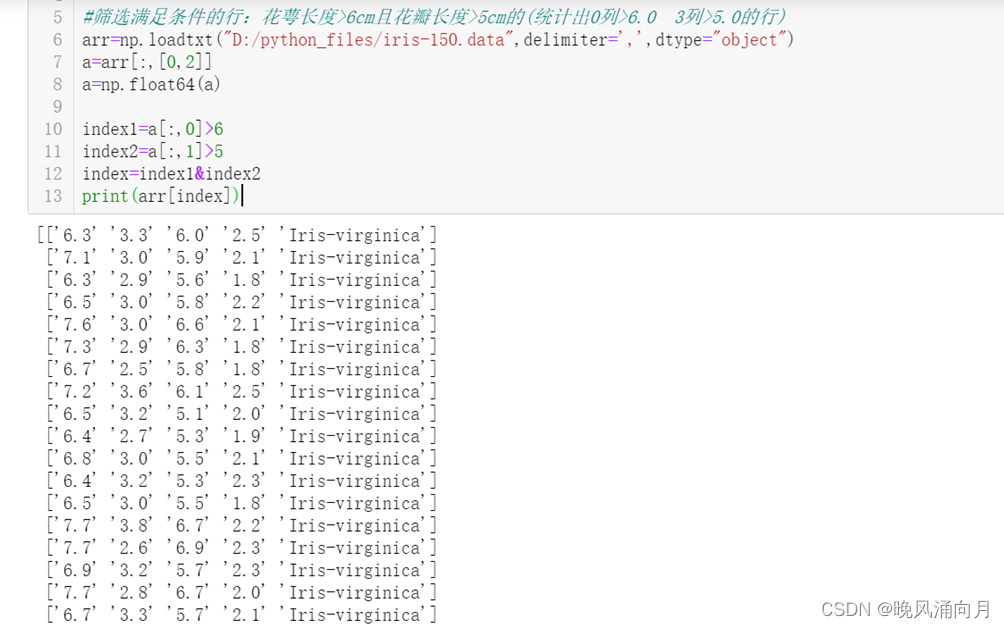
①筛选满足条件的行:花萼长度>6cm且花瓣长度>5cm的(统计出0列>6.0 3列>5.0的行)
arr=np.loadtxt("D:/python_files/iris-150.data",delimiter=',',dtype="object")
a=arr[:,[0,2]]
a=np.float64(a)
index1=a[:,0]>6
index2=a[:,1]>5
index=index1&index2
print(arr[index])
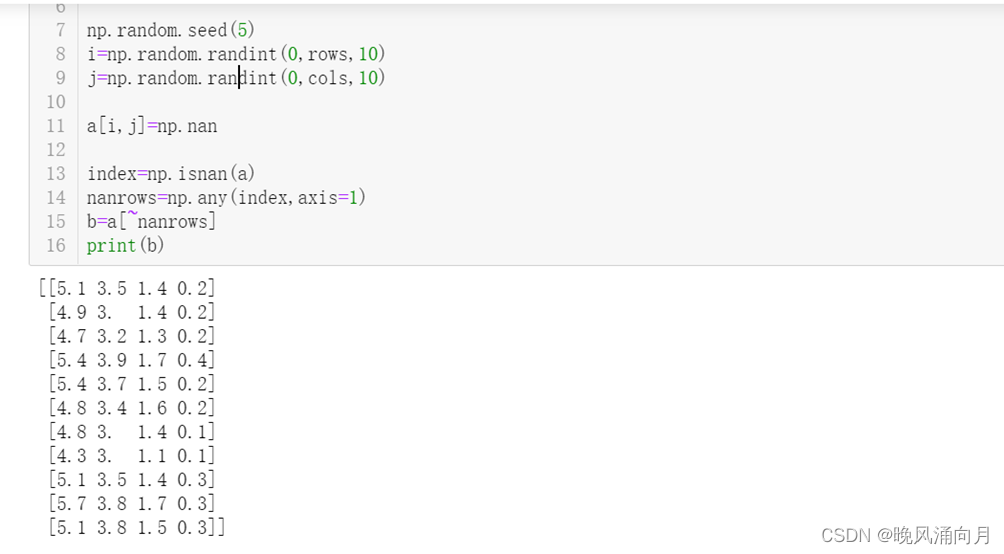
②若原始数据中有空值,删除带有空值的行
#制造10个随机空值,放入数组,删除带有空值的行
a=np.loadtxt("D:/python_files/iris-20.data",delimiter=',',usecols=[0,1,2,3])
#print(iris)
rows,cols=a.shape
np.random.seed(5)
i=np.random.randint(0,rows,10)
j=np.random.randint(0,cols,10)
a[i,j]=np.nan
index=np.isnan(a)
nanrows=np.any(index,axis=1)
b=a[~nanrows]
print(b)
3、实验结论及注意事项
(1) np.linspace与np.arange 的区别:
①np.linspace (起点,终点,等分数)
结果是左闭右闭的区间,即起点与终点都可以取到;
②np.arange(起点,终点,步长)
是左闭右开的区间,即起点可以取到,终点不能取到。
(2) “?+名词”查看属性,例如:
?np.ones
?np.random.random
(3) 均匀分布与正态分布的平均值,分别接近于0.5与0
①均匀分布平均值计算方法:
a = np.random.rand(10000)
print(a.mean())
②正态分布的平均值计算方法:
b = np.random.randn(10000)
print(b.mean())
(4) shuffle:只打乱最高维度
对于a=np.arange(60).reshape(5,3,4),表示将一维数组形状转变为三维数组,且三维数组为3行4列的5个面,如果再次基础上通过shuffle打乱,只能将最高维度——面维度打乱。若要将元素出场顺序全部打乱,可采取方法:先shuffle,再reshape,例如:
a=np.arange(12)
np.random.shuffle(a)
a=a.reshape(3,4)
print(a)
(5)在多维数组的展平中flatten不能改变原始数组,应写成a=a.flatten()。
(6) “delimiter=‘,’”:原始文件是用逗号分隔的,所以需要指定分隔符为逗号。
(7)dtype='object’中object表示混合类型,原始数据中最后一列有字符,所以应写为:object。
(8)实验心得:本次实验学习了关于Numpy库的数值计算及分析,主要掌握了Numpy数组属性、索引方法以及相关数组运算,明白了如何创建各种类型数组、如何转换数组类型,在动手实践中发现问题、解决问题,使我受益颇多。