Visual Attention Network阅读翻译笔记
原文:https://arxiv.org/abs/2202.09741
代码:https://github.com/Visual-Attention-Network
摘要——虽然最初是为自然语言处理任务而设计的,但自注意力机制最近已经席卷了各种计算机视觉领域。然而,图像的 2D 特性为在计算机视觉中应用自注意力带来了三个挑战。
(1) 将图像视为 1D 序列会忽略它们的 2D 结构。
(2) 二次复杂度对于高分辨率图像来说太昂贵了。
(3) 只捕捉空间适应性而忽略通道适应性。
在本文中,我们提出了一种新的线性注意,称为大核注意(LKA),以实现自我注意中的自适应和长程相关性,同时避免其缺点。此外,我们提出了一个基于 LKA 的神经网络,即视觉注意网络 (VAN)。虽然极其简单,但 VAN 在图像分类、对象检测、语义分割、全景分割、姿势估计等各种任务中都超过了类似大小的视觉转换器 (ViTs) 和卷积神经网络 (CNNs)。例如,VAN-B6 达到 87.8 ImageNet 基准上的 % 准确率,并为全景分割设置了新的最先进性能 (58.2 PQ)。此外,VAN-B2 在 ADE20K 基准上的语义分割超过 Swin-T 4% mIoU(50.1 vs. 46.1),在 COCO 数据集上的目标检测超过 2.6% AP(48.8 vs. 46.2)。它为社区提供了一种新颖的方法和简单而强大的基线。代码可在https://github.com/Visual-Attention-Network
即使取得了显着的成功,卷积操作和自注意力仍然有其不足之处。卷积运算采用静态权重,缺乏适应性,已被证明是关键的[12],[16]。正如最初为 1D NLP 任务设计的那样,selfattention [13]、[13] 将 2D 图像视为 1D 序列,这破坏了图像的关键 2D 结构。由于其二次计算和内存开销,处理高分辨率图像也很困难。此外,self-attention 是一种特殊的注意力,它只考虑空间维度的适应性,而忽略了通道维度的适应性,这对于视觉任务 [12]、[30]、[31]、[32] 也很重要。
在本文中,提出了一种新的线性注意力机制,称为大核注意力(LKA),它是为视觉任务量身定制的。 LKA吸收了卷积和selfattention的优点,包括局部结构信息、长程依赖和适应性。同时也避免了它们在渠道维度上忽略了适应性等缺点。基于 LKA,我们提出了一种称为视觉注意网络 (VAN) 的新型视觉骨干网,它显着超越了众所周知的基于 CNN 和基于变压器的骨干网。本文的贡献总结如下:
•我们为计算机视觉设计了一种名为 LKA 的新型线性注意机制,它考虑了卷积和自注意的优点,同时避免了它们的缺点。在 LKA 的基础上,我们进一步引入了一个简单的视觉骨干,称为 V AN。
• 在各种任务的广泛实验中,V ANs优于相似级别的 ViTs 和 CNNs,包括图像分类、对象检测、语义分割、实例分割、姿势估计等。
##LKA
LKA与 MobileNet [6] 有相似之处, MobileNet它将标准卷积解耦为两部分,一个深度卷积和一个点卷积(也称为 1 × 1 Conv [36])。LKA将卷积分解为三部分:深度卷积、深度和扩张卷积[37]、[38]和点卷积。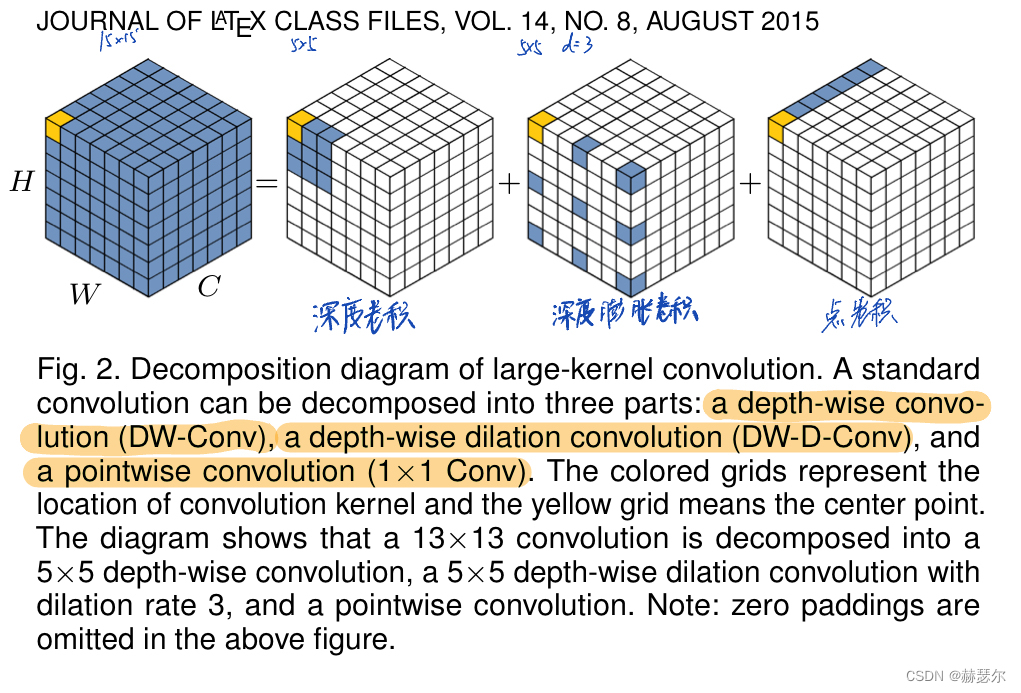
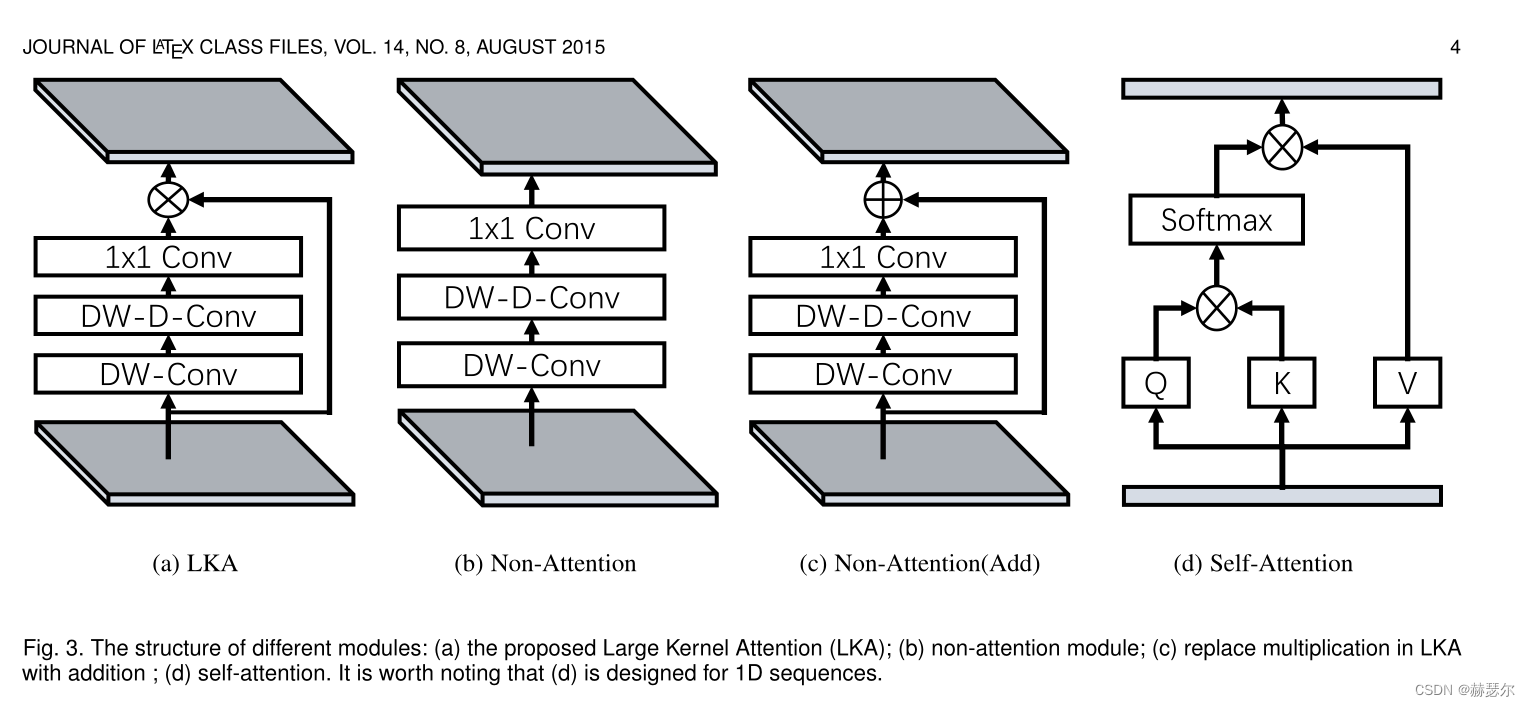
为了克服上述缺点并利用自注意力和大内核卷积的优点,我们建议分解大内核卷积操作来捕获远程关系。如图2所示,大核卷积可以分为三个部分:空间局部卷积(depthwise convolution)、空间长程卷积(depth-wise dilation convolution)和通道卷积(1×1卷积)。具体来说。我们可以将一个 K × K 卷积分解为一个 d/ K*d/ K的 depth-wise dilation convolution with dilation d、一个 (2d−1)×(2d−1) depth-wise 卷积和一个 1×1 卷积。通过上述分解,我们可以捕捉到计算成本和参数很小的远程关系。在获得远程关系后,我们可以估计一个点的重要性并生成注意力图。如图 3(a) 所示,LKA 模块可以写为
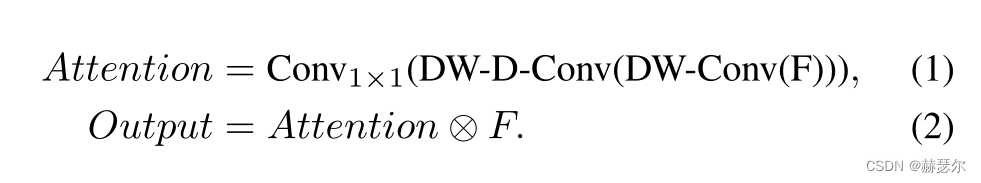
这里,F ∈ RC×H×W 是输入特征。 Attention ∈ RC×H×W 表示注意力图。注意图中的值表示每个特征的重要性。 ⊗ 表示元素产品。与常见的注意力方法不同,LKA 不需要像 sigmoid 和 softmax 那样的额外归一化函数,这在表中得到了证明。 3. 我们还认为注意力方法的关键特征是根据输入特征自适应地调整输出,而不是归一化的注意力图。如表中所示。 1,我们提出的 LKA 结合了卷积和自注意力的优点。它考虑了局部上下文信息、大感受野、线性复杂度和动态过程。此外,LKA不仅实现了空间维度的适应性,还实现了通道维度的适应性。值得注意的是,在深度神经网络 [43]、[65] 和通道维度的适应性对于视觉任务也很重要。
class LKA(nn.Module):
def __init__(self, dim):
super().__init__()
self.conv0 = nn.Conv2d(dim, dim, 5, padding=2, groups=dim)
self.conv_spatial = nn.Conv2d(dim, dim, 7, stride=1, padding=9, groups=dim, dilation=3)
self.conv1 = nn.Conv2d(dim, dim, 1)
def forward(self, x):
u = x.clone()
attn = self.conv0(x)
attn = self.conv_spatial(attn)
attn = self.conv1(attn)
return u * attn
Attention
class Attention(nn.Module):
def __init__(self, d_model):
super().__init__()
self.proj_1 = nn.Conv2d(d_model, d_model, 1)
self.activation = nn.GELU()
self.spatial_gating_unit = LKA(d_model)
self.proj_2 = nn.Conv2d(d_model, d_model, 1)
def forward(self, x):
shorcut = x.clone()
x = self.proj_1(x)
x = self.activation(x)
x = self.spatial_gating_unit(x)
x = self.proj_2(x)
x = x + shorcut
return x
Block
class Block(nn.Module):
def __init__(self, dim, mlp_ratio=4., drop=0.,drop_path=0., act_layer=nn.GELU):
super().__init__()
self.norm1 = nn.BatchNorm2d(dim)
self.attn = Attention(dim)
self.drop_path = DropPath(drop_path) if drop_path > 0. else nn.Identity()
self.norm2 = nn.BatchNorm2d(dim)
mlp_hidden_dim = int(dim * mlp_ratio)
self.mlp = Mlp(in_features=dim, hidden_features=mlp_hidden_dim, act_layer=act_layer, drop=drop)
layer_scale_init_value = 1e-2
self.layer_scale_1 = nn.Parameter(
layer_scale_init_value * torch.ones((dim)), requires_grad=True)
self.layer_scale_2 = nn.Parameter(
layer_scale_init_value * torch.ones((dim)), requires_grad=True)
self.apply(self._init_weights)
def _init_weights(self, m):
if isinstance(m, nn.Linear):
trunc_normal_(m.weight, std=.02)
if isinstance(m, nn.Linear) and m.bias is not None:
nn.init.constant_(m.bias, 0)
elif isinstance(m, nn.LayerNorm):
nn.init.constant_(m.bias, 0)
nn.init.constant_(m.weight, 1.0)
elif isinstance(m, nn.Conv2d):
fan_out = m.kernel_size[0] * m.kernel_size[1] * m.out_channels
fan_out //= m.groups
m.weight.data.normal_(0, math.sqrt(2.0 / fan_out))
if m.bias is not None:
m.bias.data.zero_()
def forward(self, x):
x = x + self.drop_path(self.layer_scale_1.unsqueeze(-1).unsqueeze(-1) * self.attn(self.norm1(x)))
x = x + self.drop_path(self.layer_scale_2.unsqueeze(-1).unsqueeze(-1) * self.mlp(self.norm2(x)))
return x
完整
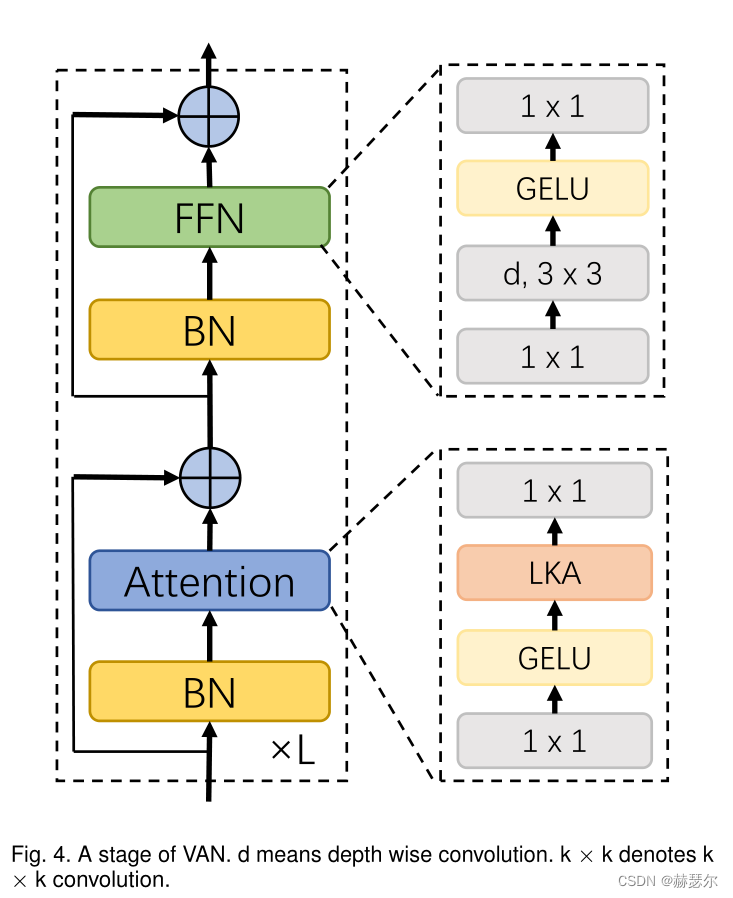
VAN 有一个简单的层次结构,即四个阶段的序列,输出空间分辨率降低,即分别为 H 4 × W 4 、 H 8 × W 8 、 H 16 × W 16 和 H 32 × W 32 。这里,H 和 W 表示输入图像的高度和宽度。随着分辨率的降低,输出通道的数量也在增加。输出通道 Ci 的变化如表所示。 5.

import torch
import torch.nn as nn
import torch.nn.functional as F
from functools import partial
from timm.models.layers import DropPath, to_2tuple, trunc_normal_
from timm.models.registry import register_model
from timm.models.vision_transformer import _cfg
import math
class Mlp(nn.Module):
def __init__(self, in_features, hidden_features=None, out_features=None, act_layer=nn.GELU, drop=0.):
super().__init__()
out_features = out_features or in_features
hidden_features = hidden_features or in_features
self.fc1 = nn.Conv2d(in_features, hidden_features, 1)
self.dwconv = DWConv(hidden_features)
self.act = act_layer()
self.fc2 = nn.Conv2d(hidden_features, out_features, 1)
self.drop = nn.Dropout(drop)
self.apply(self._init_weights)
def _init_weights(self, m):
if isinstance(m, nn.Linear):
trunc_normal_(m.weight, std=.02)
if isinstance(m, nn.Linear) and m.bias is not None:
nn.init.constant_(m.bias, 0)
elif isinstance(m, nn.LayerNorm):
nn.init.constant_(m.bias, 0)
nn.init.constant_(m.weight, 1.0)
elif isinstance(m, nn.Conv2d):
fan_out = m.kernel_size[0] * m.kernel_size[1] * m.out_channels
fan_out //= m.groups
m.weight.data.normal_(0, math.sqrt(2.0 / fan_out))
if m.bias is not None:
m.bias.data.zero_()
def forward(self, x):
x = self.fc1(x)
x = self.dwconv(x)
x = self.act(x)
x = self.drop(x)
x = self.fc2(x)
x = self.drop(x)
return x
class LKA(nn.Module):
def __init__(self, dim):
super().__init__()
self.conv0 = nn.Conv2d(dim, dim, 5, padding=2, groups=dim)
self.conv_spatial = nn.Conv2d(dim, dim, 7, stride=1, padding=9, groups=dim, dilation=3)
self.conv1 = nn.Conv2d(dim, dim, 1)
def forward(self, x):
u = x.clone()
attn = self.conv0(x)
attn = self.conv_spatial(attn)
attn = self.conv1(attn)
return u * attn
class Attention(nn.Module):
def __init__(self, d_model):
super().__init__()
self.proj_1 = nn.Conv2d(d_model, d_model, 1)
self.activation = nn.GELU()
self.spatial_gating_unit = LKA(d_model)
self.proj_2 = nn.Conv2d(d_model, d_model, 1)
def forward(self, x):
shorcut = x.clone()
x = self.proj_1(x)
x = self.activation(x)
x = self.spatial_gating_unit(x)
x = self.proj_2(x)
x = x + shorcut
return x
class Block(nn.Module):
def __init__(self, dim, mlp_ratio=4., drop=0.,drop_path=0., act_layer=nn.GELU):
super().__init__()
self.norm1 = nn.BatchNorm2d(dim)
self.attn = Attention(dim)
self.drop_path = DropPath(drop_path) if drop_path > 0. else nn.Identity()
self.norm2 = nn.BatchNorm2d(dim)
mlp_hidden_dim = int(dim * mlp_ratio)
self.mlp = Mlp(in_features=dim, hidden_features=mlp_hidden_dim, act_layer=act_layer, drop=drop)
layer_scale_init_value = 1e-2
self.layer_scale_1 = nn.Parameter(
layer_scale_init_value * torch.ones((dim)), requires_grad=True)
self.layer_scale_2 = nn.Parameter(
layer_scale_init_value * torch.ones((dim)), requires_grad=True)
self.apply(self._init_weights)
def _init_weights(self, m):
if isinstance(m, nn.Linear):
trunc_normal_(m.weight, std=.02)
if isinstance(m, nn.Linear) and m.bias is not None:
nn.init.constant_(m.bias, 0)
elif isinstance(m, nn.LayerNorm):
nn.init.constant_(m.bias, 0)
nn.init.constant_(m.weight, 1.0)
elif isinstance(m, nn.Conv2d):
fan_out = m.kernel_size[0] * m.kernel_size[1] * m.out_channels
fan_out //= m.groups
m.weight.data.normal_(0, math.sqrt(2.0 / fan_out))
if m.bias is not None:
m.bias.data.zero_()
def forward(self, x):
x = x + self.drop_path(self.layer_scale_1.unsqueeze(-1).unsqueeze(-1) * self.attn(self.norm1(x)))
x = x + self.drop_path(self.layer_scale_2.unsqueeze(-1).unsqueeze(-1) * self.mlp(self.norm2(x)))
return x
class OverlapPatchEmbed(nn.Module):
""" Image to Patch Embedding
"""
def __init__(self, img_size=224, patch_size=7, stride=4, in_chans=3, embed_dim=768):
super().__init__()
patch_size = to_2tuple(patch_size)
self.proj = nn.Conv2d(in_chans, embed_dim, kernel_size=patch_size, stride=stride,
padding=(patch_size[0] // 2, patch_size[1] // 2))
self.norm = nn.BatchNorm2d(embed_dim)
self.apply(self._init_weights)
def _init_weights(self, m):
if isinstance(m, nn.Linear):
trunc_normal_(m.weight, std=.02)
if isinstance(m, nn.Linear) and m.bias is not None:
nn.init.constant_(m.bias, 0)
elif isinstance(m, nn.LayerNorm):
nn.init.constant_(m.bias, 0)
nn.init.constant_(m.weight, 1.0)
elif isinstance(m, nn.Conv2d):
fan_out = m.kernel_size[0] * m.kernel_size[1] * m.out_channels
fan_out //= m.groups
m.weight.data.normal_(0, math.sqrt(2.0 / fan_out))
if m.bias is not None:
m.bias.data.zero_()
def forward(self, x):
x = self.proj(x)
_, _, H, W = x.shape
x = self.norm(x)
return x, H, W
class VAN(nn.Module):
def __init__(self, img_size=224, in_chans=3, num_classes=1000, embed_dims=[64, 128, 256, 512],
mlp_ratios=[4, 4, 4, 4], drop_rate=0., drop_path_rate=0., norm_layer=nn.LayerNorm,
depths=[3, 4, 6, 3], num_stages=4, flag=False):
super().__init__()
if flag == False:
self.num_classes = num_classes
self.depths = depths
self.num_stages = num_stages
dpr = [x.item() for x in torch.linspace(0, drop_path_rate, sum(depths))] # stochastic depth decay rule
cur = 0
for i in range(num_stages):
patch_embed = OverlapPatchEmbed(img_size=img_size if i == 0 else img_size // (2 ** (i + 1)),
patch_size=7 if i == 0 else 3,
stride=4 if i == 0 else 2,
in_chans=in_chans if i == 0 else embed_dims[i - 1],
embed_dim=embed_dims[i])
block = nn.ModuleList([Block(
dim=embed_dims[i], mlp_ratio=mlp_ratios[i], drop=drop_rate, drop_path=dpr[cur + j])
for j in range(depths[i])])
norm = norm_layer(embed_dims[i])
cur += depths[i]
setattr(self, f"patch_embed{i + 1}", patch_embed)
setattr(self, f"block{i + 1}", block)
setattr(self, f"norm{i + 1}", norm)
# classification head
self.head = nn.Linear(embed_dims[3], num_classes) if num_classes > 0 else nn.Identity()
self.apply(self._init_weights)
def _init_weights(self, m):
if isinstance(m, nn.Linear):
trunc_normal_(m.weight, std=.02)
if isinstance(m, nn.Linear) and m.bias is not None:
nn.init.constant_(m.bias, 0)
elif isinstance(m, nn.LayerNorm):
nn.init.constant_(m.bias, 0)
nn.init.constant_(m.weight, 1.0)
elif isinstance(m, nn.Conv2d):
fan_out = m.kernel_size[0] * m.kernel_size[1] * m.out_channels
fan_out //= m.groups
m.weight.data.normal_(0, math.sqrt(2.0 / fan_out))
if m.bias is not None:
m.bias.data.zero_()
def freeze_patch_emb(self):
self.patch_embed1.requires_grad = False
@torch.jit.ignore
def no_weight_decay(self):
return {'pos_embed1', 'pos_embed2', 'pos_embed3', 'pos_embed4', 'cls_token'} # has pos_embed may be better
def get_classifier(self):
return self.head
def reset_classifier(self, num_classes, global_pool=''):
self.num_classes = num_classes
self.head = nn.Linear(self.embed_dim, num_classes) if num_classes > 0 else nn.Identity()
def forward_features(self, x):
B = x.shape[0]
for i in range(self.num_stages):
patch_embed = getattr(self, f"patch_embed{i + 1}")
block = getattr(self, f"block{i + 1}")
norm = getattr(self, f"norm{i + 1}")
x, H, W = patch_embed(x)
for blk in block:
x = blk(x)
x = x.flatten(2).transpose(1, 2)
x = norm(x)
if i != self.num_stages - 1:
x = x.reshape(B, H, W, -1).permute(0, 3, 1, 2).contiguous()
return x.mean(dim=1)
def forward(self, x):
x = self.forward_features(x)
x = self.head(x)
return x
class DWConv(nn.Module):
def __init__(self, dim=768):
super(DWConv, self).__init__()
self.dwconv = nn.Conv2d(dim, dim, 3, 1, 1, bias=True, groups=dim)
def forward(self, x):
x = self.dwconv(x)
return x
def _conv_filter(state_dict, patch_size=16):
""" convert patch embedding weight from manual patchify + linear proj to conv"""
out_dict = {}
for k, v in state_dict.items():
if 'patch_embed.proj.weight' in k:
v = v.reshape((v.shape[0], 3, patch_size, patch_size))
out_dict[k] = v
return out_dict
model_urls = {
"van_b0": "https://huggingface.co/Visual-Attention-Network/VAN-Tiny-original/resolve/main/van_tiny_754.pth.tar",
"van_b1": "https://huggingface.co/Visual-Attention-Network/VAN-Small-original/resolve/main/van_small_811.pth.tar",
"van_b2": "https://huggingface.co/Visual-Attention-Network/VAN-Base-original/resolve/main/van_base_828.pth.tar",
"van_b3": "https://huggingface.co/Visual-Attention-Network/VAN-Large-original/resolve/main/van_large_839.pth.tar",
}
def load_model_weights(model, arch, kwargs):
url = model_urls[arch]
checkpoint = torch.hub.load_state_dict_from_url(
url=url, map_location="cpu", check_hash=True
)
strict = True
if "num_classes" in kwargs and kwargs["num_classes"] != 1000:
strict = False
del checkpoint["state_dict"]["head.weight"]
del checkpoint["state_dict"]["head.bias"]
model.load_state_dict(checkpoint["state_dict"], strict=strict)
return model
@register_model
def van_b0(pretrained=False, **kwargs):
model = VAN(
embed_dims=[32, 64, 160, 256], mlp_ratios=[8, 8, 4, 4],
norm_layer=partial(nn.LayerNorm, eps=1e-6), depths=[3, 3, 5, 2],
**kwargs)
model.default_cfg = _cfg()
if pretrained:
model = load_model_weights(model, "van_b0", kwargs)
return model
@register_model
def van_b1(pretrained=False, **kwargs):
model = VAN(
embed_dims=[64, 128, 320, 512], mlp_ratios=[8, 8, 4, 4],
norm_layer=partial(nn.LayerNorm, eps=1e-6), depths=[2, 2, 4, 2],
**kwargs)
model.default_cfg = _cfg()
if pretrained:
model = load_model_weights(model, "van_b1", kwargs)
return model
@register_model
def van_b2(pretrained=False, **kwargs):
model = VAN(
embed_dims=[64, 128, 320, 512], mlp_ratios=[8, 8, 4, 4],
norm_layer=partial(nn.LayerNorm, eps=1e-6), depths=[3, 3, 12, 3],
**kwargs)
model.default_cfg = _cfg()
if pretrained:
model = load_model_weights(model, "van_b2", kwargs)
return model
@register_model
def van_b3(pretrained=False, **kwargs):
model = VAN(
embed_dims=[64, 128, 320, 512], mlp_ratios=[8, 8, 4, 4],
norm_layer=partial(nn.LayerNorm, eps=1e-6), depths=[3, 5, 27, 3],
**kwargs)
model.default_cfg = _cfg()
if pretrained:
model = load_model_weights(model, "van_b3", kwargs)
return model
@register_model
def van_b4(pretrained=False, **kwargs):
model = VAN(
embed_dims=[64, 128, 320, 512], mlp_ratios=[8, 8, 4, 4],
norm_layer=partial(nn.LayerNorm, eps=1e-6), depths=[3, 6, 40, 3],
**kwargs)
model.default_cfg = _cfg()
if pretrained:
model = load_model_weights(model, "van_b4", kwargs)
return model
@register_model
def van_b5(pretrained=False, **kwargs):
model = VAN(
embed_dims=[96, 192, 480, 768], mlp_ratios=[8, 8, 4, 4],
norm_layer=partial(nn.LayerNorm, eps=1e-6), depths=[3, 3, 24, 3],
**kwargs)
model.default_cfg = _cfg()
if pretrained:
model = load_model_weights(model, "van_b5", kwargs)
return model
@register_model
def van_b6(pretrained=False, **kwargs):
model = VAN(
embed_dims=[96, 192, 384, 768], mlp_ratios=[8, 8, 4, 4],
norm_layer=partial(nn.LayerNorm, eps=1e-6), depths=[6,6,90,6],
**kwargs)
model.default_cfg = _cfg()
if pretrained:
model = load_model_weights(model, "van_b6", kwargs)
return model