执行计划
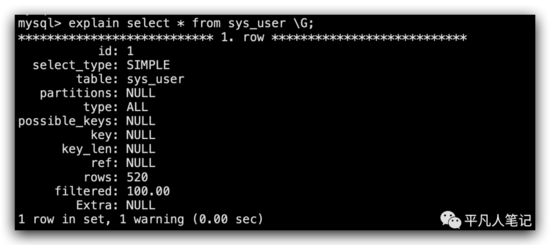
表示访问数据或进行查询的时候,所对应的类型是什么。效率优先级由低到高,all->index -> range -> index_ref -> cost -->system。all代表全表扫描 ,效率最低的一种方式,system效率是最高的。
如果sql语句里面有type=all,一定要进行sql优化的,尽可能的保证type类型的值在range以上。
执行计划的官网文档
https://dev.mysql.com/doc/refman/5.7/en/explain-output.html
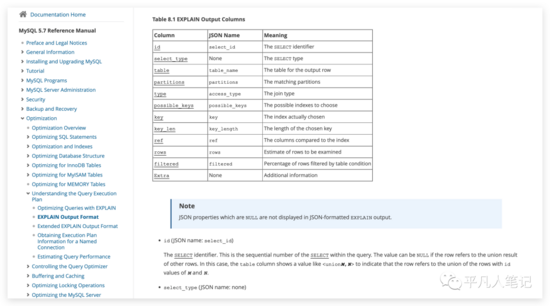
点开type,可以看到每种类型的解释

all的效率是最低的。
什么条件都不带的排序 怎么进行优化
大部分的排序都是在内存中进行的,比如冒泡、归并、快排、希尔排序、基数排序、堆排序。
如果数据量非常非常大的话,内存存不下怎么办?可以利用索引,

索引要看名字,不要看行数
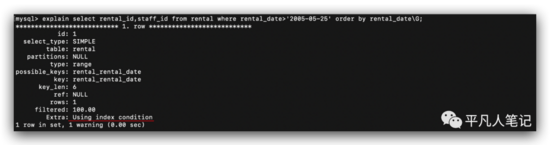
使用索引排序,
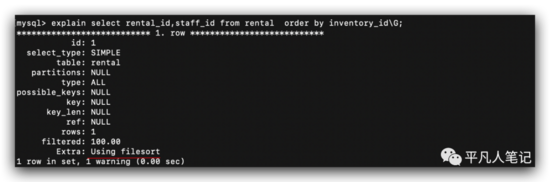
使用临时文件排序。利用索引的效率更快一些。
如果是一个全乱序的数组,在进行查看的时候,需要把所有的数组加载到内存里面,然后再进行一个排序。
如果数据本身是有序的,直接从数据文件中把数据取出来。
利用了索引的有序性这个特点来进行相关的优化和调整,这就是执行计划带给我们的意义。
索引系统设计所需的基本理论知识
执行计划最关键最核心的点在于索引,索引加快数据的访问。
索引采用b+树数据结构。
数据存储在磁盘,读取磁盘数据,内存和磁盘数据进行交换。
IO (输入和输出) 是硬件层面解决问题,比如将机械磁盘换成固态磁盘(机械硬盘是一种传统的硬盘,它包括磁盘的转轴,磁头控制器,数据转换器和控制马达。而固态硬盘,就是由固态的电子储存晶片组成的硬碟)。
尽量减少读取次数,每次读取量尽量少。
考虑存储的数据是什么类型的数据(数据格式),比如书的目录,先找到目录名称对应的页面,直接翻到对应页看找到内容。
索引是由关键字和指针组成,存储是K-V格式的数据。用什么样的数据结构来进行存储这个数据?
比如hash表、树(二叉树、红黑树、avl树、btree、b+tree等),但不管什么样的数据,要保持K-V的数据格式。
查询出来的数据是一行一行的,而写到磁盘是一个个固定的文件。
一个文件假设1T的磁盘,没有1T的内存空间存储全量数据,保证数据在读取的时候要分块读取,比如每次读10M,切分成一个一个的单独块,分的次数多些或者需要读的时候再读,不需要读的时候就不读了。
操作系统基本概念
-
局部性原理
数据和程序都有聚集成群的倾向,叫空间局部性,在进行数据拼接的时候把某些具体类别的数据放到一起,比如相同特征的数据放在一起,不相同不放在一块;之前被访问过的数据有可能很快被下一次访问到,这个叫时间局部性。
-
磁盘预读
内存跟磁盘发生磁盘交互的时候 ,有一个基本的逻辑单位叫做页,页的大小跟操作系统相关,一般是4K或8K,在进行数据交互的时候数据大小是页的整数倍,比如某一页是4KB,读数据的时候可以是8K、16K、32K 、64K,必须是整数倍。分块的时候,每次读取大于4K或者 4K整数倍的数据,也没有固定块大小多少,是4K的整数倍就行了。
innodb存储引擎,每次读取16KB的数据 ,不管磁盘文件多大,每次就读取16KB。
借鉴了这些理论知识来进行索引系统的设计。
如何存储数据
K-V数据格式,K是索引的值,V代表当前整个行记录/数据。
把数据聚集成群的进行存放,需要选择合适的数据结构,一个是hash表,一个是树。
计算下当前key的hash位置,放入某一个格子,如果有元素就往上面追加,如果没有元素直接放入进去。
hash数据结构的问题
-
hash冲突
需要优良的hash算法,否则会造成hash碰撞或hash冲突问题。比如0246有元素,1357没有元素,没有元素会浪费存储空间,导致数据散列不均匀。
-
无序
无序会导致无法进行范围查询,本身hash是散列的方式乱序放入。比如id>3 ,将会进行全表扫描, 效率极低。
-
需要大量的内存空间
在创建的时候,必须指定好长度,后面会进行扩容,但是对内存的消耗是比较大的。
mysql中是有hash索引的
https://dev.mysql.com/doc/refman/5.7/en/glossary.html#glos_hash_index

对于memory这种存储引擎,是支持hash索引的。在内存里,就算挨个对比,效率依然很高,不在磁盘中,不会发生内存和磁盘之间的数据交换。
innodb支持自适应hash。
树是比较复杂的
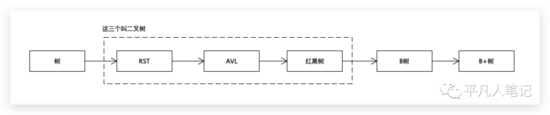
RST(鲁棒序列树)和AVL(平衡二叉查找树)和红黑树都属于二叉树。每一个节点有且仅有两个分支,只不过在AVL和红黑树会有一个平衡的过程,保证左右子树空间存储的数据尽可能一致。AVL是严格意义上的平衡树,红黑树是非严格。
将二叉树作为数据结构,会有什么问题
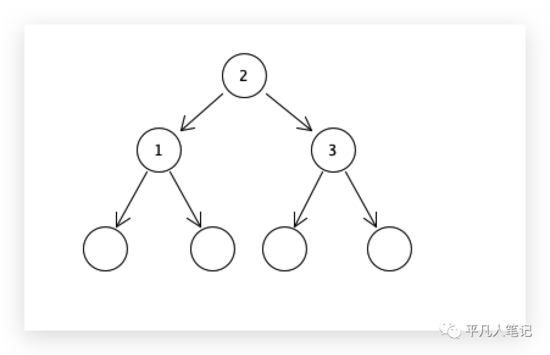
每个节点有且仅有两个分支。左边是小于key的,右边是大于key的。如果想往当前结构里面插入更多的数据的话,就可能会导致当前这棵树变得无限深,太深的话,会导致io次数会变高,最根本的原因在于二叉有且仅有两个分支,但是它里面依然有借鉴的地方即有序,缺点在于二叉。
为了保证这棵树不变高,变成一个"矮胖子",变形为多叉排序树(无论三叉还是四叉...),保证每个节点上尽可能多的去存储数据。
https://www.cs.usfca.edu/~galles/visualization/Algorithms.html

b树和b+树在进行数据插入的时候,有一个叫degree 度的, 表示每个节点最多可以存放多少个元素值。
每个节点里面只能放一个key值 ,多叉意味着有多个分支 (多个分支的话,一定要区分分支的范围)所以上面一定是多个值,有多个的范围。
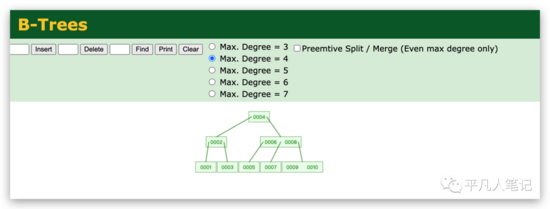
如果degree=4 就说明每个节点中可以放4-1=3的数据量。
10个数据,分三层。整个b树里面没有重复数据。
怎么把这样数据映射到数据库表里面?
在检索一行记录的时候,有key值和value(整行记录),就意味着key值和整行元素变成一个集合放到节点里面,变成某一个节点的值。在这种情况下做了一个演变或者叫变形,
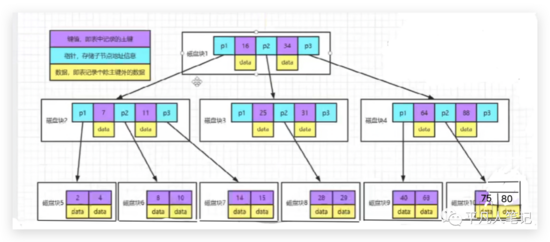
这是一个b树,在b树里面每一个磁盘块叫页,每个磁盘块默认16KB(这个大小可以自己去调整,默认是16KB)。在每个磁盘块里面,放了三个类型的数据,第一个类型指针,第二个类型是key值(索引列里面的数值),第三个类型是data整行的行记录。
b树的数据和key值放在一起,对于当前的三层的b树而言,如果要读取28这条记录的话,先拿到根节点,拿28和16做对比,大于16,小于34,则找到p2,通过p2找到磁盘3,在磁盘3上继续做判断,28大于25,小于31,找到p2指针,再通过磁盘3的p2指针找到磁盘8,进而找到key=28的数据。
在这整个遍历的过程中,读了多少数据或者读了多大的数据,每一块是16KB,读了3个磁盘块,16x3,一共读取了48kb的数据。
目前这样的一个数据结构,能存储的数据量有多少
一个表用这样三层数据结构来存储的话,这个表里面可以存储多少条数据。
假设一个data就代表一行记录,假设一行记录等于1kb,当前磁盘块里面最多可以存放15条记录。key和指针都是占空间的,为了方便计算,假设这些东西不占用空间,如果一个磁盘快存储16个数值的话,三层共16的三次方4096条记录,数据量很少。那如果想存储8000条怎么办,只能往下加一层,高度就变高了。为什么才存储了4000多条数据,是谁占用了大量的存储空间?
data 这里面要把分支变多,在整个基础之上,能不能让第一层和第二层不存数据 ,只放key值和指针。
在这个数据之上,就变成了b+树的数据结构。
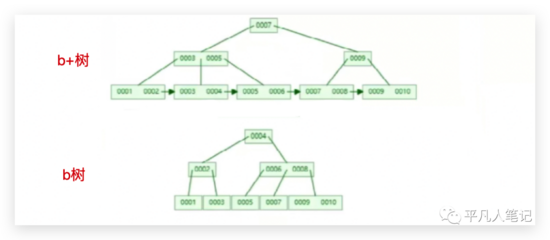
b+树的特点:
B+Tree是在BTree的基础之上做的一种优化,变化如下:
-
B+Tree每个节点可以包含更多的节点,这么做的原因,第一个是为了降低树的高度,第二个是将数据范围变为多个区间,区间越多,数据检索越快
-
非叶子节点存储key,叶子节点存储key和数据
-
叶子节点两两指针相互连接(符合磁盘的预读特性),顺序查询性能更高
-
在B+Tree上有两头指针,一头指向根节点,另一头指向关键字最小的叶子节点,而且所有叶子节点(即数据节点)之间是一种链式结构,因此可以对B+Tree进行两种查询运算:一种是对主键的范围查找和分页查找,另一种是从根节点开始,进行随机查找。
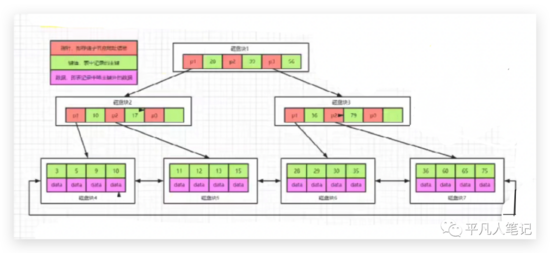
第一、二层少了data,叶子节点用一个双向链表把所有数据链接起来了
那当前b+能支持的数据存储量有多少?
数据总量没变,还是三层,还是读48K的数据,假设p1和20是一组,共同占用10个字节,第一个磁盘块可以存储多少个分支?16K等于16 X 1024个字节,为了好算,1024当1000来算,除以10即16 X 1000 / 10 =1600个分支,第二层也是1600个分支,第三层一个data为1kb即一个磁盘块存储16条数据,三层可以存储的数据规模是4000万,扩展了1万倍,所以3到4层的b+树,足以支撑千万级的数据量。
整体的块大小是不变的,key值发生了变化,如果key值+指针占100个字节,16x1000/100即160X160X16=40万零9600。
索引类型用int类型还是varchar类型
int 4个字节,varchar如果指定3个字节,在进行实际数值存储的时候,要看占用的字节数,一般情况下,你用varchar的情况肯定超过了10或超过4 ,但不排除其他情况,所以一般情况下用int。