1. 搜索技术
搜索技术在我们日常生活的方方面面都会用到,例如:
- 综合搜索网站:百度、谷歌等
- 电商网站:京东、淘宝的商品搜索
- 软件内数据搜索:我们用的开发工具,如Idea的搜索功能
这些搜索业务有一些可以使用数据库来完成,有一些却不行。因此我们今天会学习一种新的搜索方案,解决海量数据、复杂业务的搜索。
1.1.关系型数据库搜索的问题
要实现类似百度的复杂搜索,或者京东的商品搜索,如果使用传统的数据库存储数据,那么会存在一系列的问题:
- 性能瓶颈:当数据量越来越大时,数据库搜索的性能会有明显下降。虽然可以通过分库分表来解决存储问题,但是性能问题并不能彻底解决,而且系统复杂度会提高、可用性下降。
- 复杂业务:百度或京东的搜索往往需要复杂的查询功能,例如:拼音搜索、错字的模糊搜索等。这些功能用数据库搜索难以实现,或者实现复杂度较高
- 并发能力:数据库是磁盘存储,虽然也有缓存方案,但是并不实用。因此数据库的读写并发能力较差,难以应对高并发场景
但是,并不是说数据库就一无是处。在一些对业务有强数据一致性需求,事物需求的情况下,数据库是不可替代的。
只是在海量数据的搜索方面,需要有新的技术来解决,就是我们今天要学习的倒排索引技术。
1.2.倒排索引
倒排索引是一种特殊的数据索引方式,虽然于数据库存储的数据结构没有太大差别,但是在检索方式上却大不一样。
1.2.1.基本概念
先来看两个概念:
- 文档(Document):用来检索的海量数据,其中的每一条数据就是一个文档。例如一个网页、一个商品信息
- 词条(Term):对文档数据或用户搜索数据,利用某种算法分词,得到的具备含义的词语就是词条。
例如,数据库中有下面的数据:
| id |
title |
| 10 |
谷歌地图之父跳槽FaceBook |
| 20 |
谷歌地图之父加盟FaceBook |
| 30 |
谷歌地图创始人拉斯离开谷歌加盟Facebook |
| 40 |
谷歌地图之父跳槽Facebook与Wave项目取消有关 |
| 50 |
谷歌地图之父拉斯加盟社交网站Facebook |
那么这里的每一行数据就是一条文档,如:
| id |
title |
| 10 |
谷歌地图之父跳槽FaceBook |
把标题字段分词,可以得到词语如:谷歌就是一个词条
现在,假设用户要搜索"谷歌创始人跳槽",来看看倒排索引的传统查找在检索时的区别:
1.2.1.传统查找流程
因为复杂搜索往往是模糊的查找,因此数据库索引基本都会实效,只能逐条数据判断。基本流程如下:
1)用户搜索数据,条件是title符合"谷歌创始人跳槽"
2)逐行获取数据,比如id为10的数据
3)判断数据中的title是否符合用户搜索条件
4)如果符合则放入结果集,不符合则丢弃。回到步骤1
如图:

如果有5条数据,则需要遍历并判断5次。如果有100万数据,则需要循环遍历和判断100万次。线性查找和判断,效率极差,一个10mb的硬盘文件,遍历一遍需要3秒。
1.2.2.倒排索引流程
倒排索引的数据存储方式与数据库类似,但检索方式不同。
1.2.2.1.数据存储方式
先看看倒排索引如何处理数据。
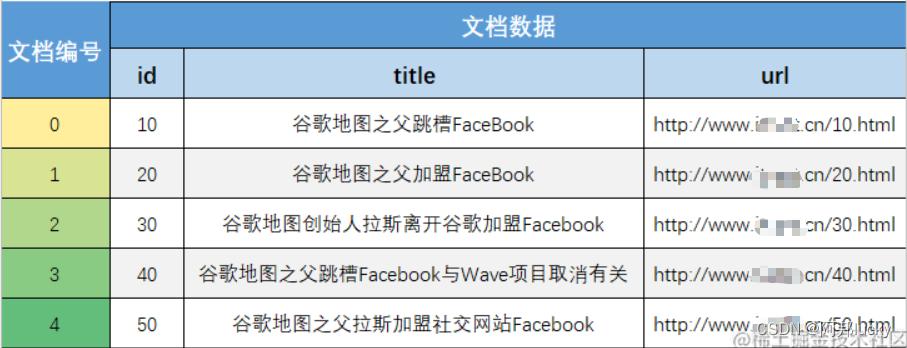
文档列表:
首先,倒排索引需要把文档数据逐个编号(从0递增),存储到文档表中。并且给每一个编号创建索引,这样根据编号检索文档的速度会非常快。
词条列表(Term Dictionary):
然后,对文档中的数据按照算法做分词,得到一个个的词条,记录词条和词条出现的文档的编号、位置、频率信息,如图:
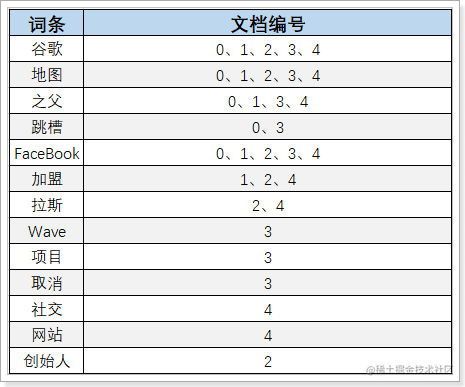
然后给词条创建索引,这样根据词条匹配和检索的速度就非常快。
1.2.2.2.检索数据过程
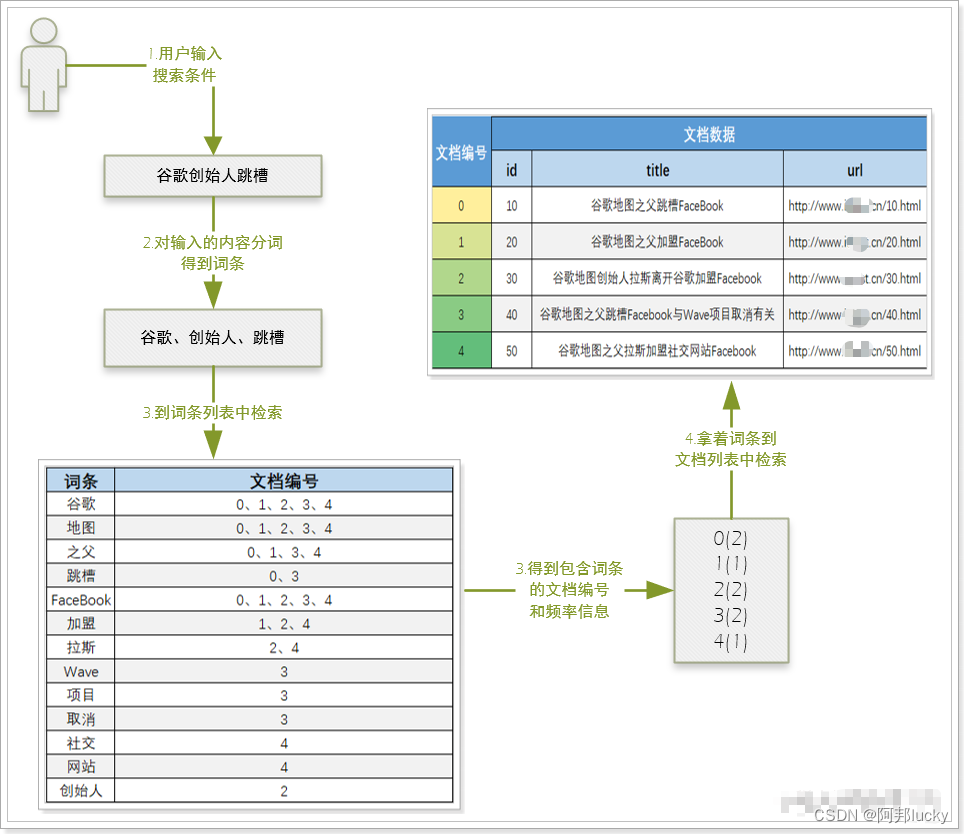
倒排索引的检索流程如下:
1)用户输入条件"谷歌创始人跳槽"进行搜索。
2)对用户输入内容分词,得到词条:谷歌、创始人、跳槽。
3)拿着词条到词条列表中查找,可以得到包含词条的文档编号:0、1、2、3、4。
4)拿着词条的编号到文档列表中查找具体文档。
如图:
虽然搜索会在两张表进行,但是每次都是根据索引查找,因此速度比传统搜索时的全表扫描速度要快的多。
1.3.Lucene
在java语言中,对倒排索引的实现中最广为人知的就是Lucene了,目前主流的java搜索框架都是依赖Lucene来实现的。
- Lucene是一套用于全文检索和搜寻的开源程序库,由Apache软件基金会支持和提供
- Lucene提供了一个简单却强大的应用程序接口(API),能够做全文索引和搜寻,在Java开发环境里Lucene是一个成熟的免费开放源代码工具
- Lucene并不是现成的搜索引擎产品,但可以用来制作搜索引擎产品,比较知名的搜索产品有:Solr、ElasticSearch
- 官网:http://lucene.apache.org/
企业生产中一般都会使用成熟的搜索产品,例如:Solr或者Elasticsearch,不过从性能来看Elasticsearch略胜一筹,因此我们今天的学习目标就是elasticsearch。
2.ElasticSearch介绍和安装
如果把Lucene比喻成一台发动机,那么Solr就是一台家用汽车,而Elasticsearch就是一台c超级跑车。
2.1.简介
Elastic官网:https://www.elastic.co/cn/
Elastic是一系列产品的集合,比较知名的是ELK技术栈,其核心就是ElasticSearch:
Elasticsearch官网:https://www.elastic.co/cn/products/elasticsearch

Elasticsearch是一个基于Lucene的搜索web服务,对外提供了一系列的Rest风格的API接口。因此任何语言的客户端都可以通过发送Http请求来实现ElasticSearch的操作。
ES的主要优势特点如下:
-
速度快:Elasticsearch 很快,快到不可思议。我们通过有限状态转换器实现了用于全文检索的倒排索引,实现了用于存储数值数据和地理位置数据的 BKD 树,以及用于分析的列存储。而且由于每个数据都被编入了索引,因此您再也不用因为某些数据没有索引而烦心。您可以用快到令人惊叹的速度使用和访问您的所有数据。实现近实时搜索,海量数据更新在Elasticsearch中几乎是完全同步的。
-
扩展性高:可以在笔记本电脑上运行,也可以在承载了 PB 级数据的成百上千台服务器上运行。原型环境和生产环境可无缝切换;无论 Elasticsearch 是在一个节点上运行,还是在一个包含 300 个节点的集群上运行,您都能够以相同的方式与 Elasticsearch 进行通信。它能够水平扩展,每秒钟可处理海量事件,同时能够自动管理索引和查询在集群中的分布方式,以实现极其流畅的操作。天生的分布式设计,很容易搭建大型的分布式集群(solr使用Zookeeper作为注册中心来实现分布式集群)
-
强大的查询和分析:通过 Elasticsearch,您能够执行及合并多种类型的搜索(结构化数据、非结构化数据、地理位置、指标),搜索方式随心而变。先从一个简单的问题出发,试试看能够从中发现些什么。找到与查询最匹配的 10 个文档是一回事。但如果面对的是十亿行日志,又该如何解读呢?Elasticsearch 聚合让您能够从大处着眼,探索数据的趋势和模式。如全文检索,同义词处理,相关度排名,复杂数据分析。
-
操作简单:客户端API支持Restful风格,简单容易上手。
使用ES的案例场景:
1、GitHub抛弃了Solr,采取ElasticSearch 来做PB级的搜索。 “GitHub使用ElasticSearch搜索20TB 的数据,包括13亿文件和1300亿行代码”
2、维基百科:启动以elasticsearch为基础的核心搜索架构
3、SoundCloud:“SoundCloud使用ElasticSearch为1.8亿用户提供即时而精准的音乐搜索服务”
4、百度:百度目前广泛使用ElasticSearch作为文本数据分析,采集百度所有服务器上的各类指标数据及用户自定义数据,通过对各种数据进行多维分析展示,辅助定位分析实例异常或业务层面异常。目前覆盖百度内部20多个业务线(包括casio、云分析、网盟、预测、文库、直达号、钱包、风控等),单集群最大100台机器,200个ES节点,每天导入30TB+数据。 新浪使用ES 分析处理32亿条实时日志。
5、阿里使用ES 构建自己的日志采集和分析体系
6、京东到家订单中心 Elasticsearch 演进历程
Elasticsearch 做为一款功能强大的分布式搜索引擎,支持近实时的存储、搜索数据,在京东到家订单系统中发挥着巨大作用,目前订单中心ES集群存储数据量达到10亿个文档,日均查询量达到5亿。
7、滴滴 2016 年初开始构建 Elasticsearch 平台,如今已经发展到超过 3500+ Elasticsearch 实例,超过 5PB 的数据存储,峰值写入 tps 超过了 2000w/s 的超大规模。
8、携程Elasticsearch应用案例
9、去哪儿:订单中心基于elasticsearch 的解决方案
。。。。。。。
本章是基于Docker安装
2.1 安装ElasticSearch
docker run -id --name elasticsearch \
-e "cluster.name=elastic-cluster" \
-e "http.host=0.0.0.0" \
-e "ES_JAVA_OPTS=-Xms512m -Xmx512m" \
-e "discovery.type=single-node" \
-e http.cors.enabled=true \
-e http.cors.allow-origin="*" \
-e http.cors.allow-headers=X-Requested-With,X-Auth-Token,Content-Type,Content-Length,Authorization \
-e http.cors.allow-credentials=true \
-v es-data:/usr/share/elasticsearch/data \
-v es-logs:/usr/share/elasticsearch/logs \
-v es-plugins:/usr/share/elasticsearch/plugins \
--privileged \
--hostname elasticsearch \
-p 9200:9200 -p 9300:9300 elasticsearch:7.4.2
命令解释:
-
-e "cluster.name=es-docker-cluster":设置集群名称
-
-e "http.host=0.0.0.0":监听的地址,可以外网访问
-
-e "ES_JAVA_OPTS=-Xms512m -Xmx512m":内存大小
-
-e "discovery.type=single-node":非集群模式
-
-v es-data:/usr/share/elasticsearch/data:挂载逻辑卷,绑定es的数据目录
-
-v es-logs:/usr/share/elasticsearch/logs:挂载逻辑卷,绑定es的日志目录
-
-v es-plugins:/usr/share/elasticsearch/plugins:挂载逻辑卷,绑定es的插件目录
-
--privileged:授予逻辑卷访问权
-
-p 9200:9200:端口映射配置
restart相关参数如下:
| 选项 |
作用 |
| –restart=no |
不自动重启容器. (默认) |
| –restart=on-failure |
容器发生error而退出(容器退出状态不为0)重启容器 |
| on-failure:3 |
在容器非正常退出时重启容器,最多重启3次 |
| –restart=unless-stopped |
在容器退出时总是重启容器,但是不考虑在Docker守护进程启动时就已经停止了的容器 |
| –restart=always |
在容器已经stop掉或Docker stoped/restarted的时候才重启容器 |
如果已经启动的容器项目,则使用update更新:
docker update --restart=always 容器名/ID
防火墙配置:
# 开放端口 9200 9300 5601
firewall-cmd --zone=public --add-port=9200/tcp --permanent
# 重启防火墙
firewall-cmd --reload
# 查看放行端口
firewall-cmd --list-ports
2.2 Kibana
ES提供了多种访问方式,官方推荐使用REST API,也是使用人数最多的访问方式。就是通过http协议,使用Restful的风格,按照es的api去操作数据,访问时我们需要传递给es json 参数,es处理后会给我们返回 json 的结果,不过浏览器不方便操作es 官方推荐使用kibana来操作ES
2.2.1 Kibana简介
Kibana是一个基于Node.js的Elasticsearch索引库数据统计工具,可以利用Elasticsearch的聚合功能,生成各种图表,如柱形图,线状图,饼图等。
而且还提供了操作Elasticsearch索引数据的控制台,并且提供了一定的API提示,非常有利于我们学习Elasticsearch的语法。
2.2.2 安装Kibana
# 可以指定es地址:-e ELASTICSEARCH_URL=http://192.168.200.150:9200
# es和kibana在同一docker下
# 可以直接: --link后面的 es容器的名称:elasticsearch
docker run -di --name kibana -p 5601:5601 --link elasticsearch:elasticsearch kibana:7.4.2
# Head 插件(了解)
docker run -d --name es_admin -p 9100:9100 mobz/elasticsearch-head:5
输入地址访问:http://192.168.200.150:5601
2.3 分词器
根据我们之前讲解的倒排索引原理,当我们向elasticsearch插入一条文档数据时,elasticsearch需要对数据分词,分词到底如何完成呢?
ElasticSearch 内置分词器
-
Standard Analyzer - 默认分词器,按词切分,小写处理
- Simple Analyzer - 按照非字母切分(符号被过滤), 小写处理
- Stop Analyzer - 小写处理,停用词过滤(the,a,is)
- Whitespace Analyzer - 按照空格切分,不转小写
- Keyword Analyzer - 不分词,直接将输入当作输出
- Patter Analyzer - 正则表达式,默认\W+(非字符分割)
- Language - 提供了30多种常见语言的分词器
2.3.1 默认的分词器
kibana中可以测试分词器效果,我们来看看elasticsearch中的默认分词器。
在kibana的DevTools中输入一段命令:
POST /_analyze
{
"text": "学习java太棒了",
"analyzer": "standard"
}
请求代表的含义:
效果:
2.3.2 IK分词器
标准分词器并不能很好处理中文,一般我们会用第三方的分词器,例如:IK分词器。
IKAnalyzer是一个开源的,基于java语言开发的轻量级的中文分词工具包,是一个基于Maven构建的项目,具有60万字/秒的高速处理能力,支持用户词典扩展定义。
IK分词器的 地址:https://github.com/medcl/elasticsearch-analysis-ik, 安装非常简单。
IK分词器可以用ik_max_word和ik_smart两种方式,分词粒度不同。
2.3.2.1 安装IK分词器
1、安装ik插件(在线较慢)
# 进入容器内部
docker exec -it elasticsearch /bin/bash
# 在线下载并安装
./bin/elasticsearch-plugin install https://github.com/medcl/elasticsearch-analysis-ik/releases/download/v7.4.2/elasticsearch-analysis-ik-7.4.2.zip
#退出
exit
#重启容器
docker restart elasticsearch
2、离线安装ik插件(推荐)
# 1、进入/var/lib/docker/volumes/es-plugins/_data/
cd /var/lib/docker/volumes/es-plugins/_data/
# 2、新建文件目录 ik 并且进入
mkdir ik
cd ik
# 3、解压elasticsearch-analysis-ik-7.4.2.zip
yum -y install unzip
unzip elasticsearch-analysis-ik-7.4.2.zip
# 4、重启容器
docker restart elasticsearch
# 查看es日志
docker logs -f elasticsearch

# 重启 Kibana
docker restart kibana
测试:
GET /_analyze
{
"analyzer": "ik_max_word",
"text": "程序员学习java太棒了"
}
结果:
{
"tokens" : [
{
"token" : "程序员",
"start_offset" : 2,
"end_offset" : 5,
"type" : "CN_WORD",
"position" : 1
},
{
"token" : "程序",
"start_offset" : 2,
"end_offset" : 4,
"type" : "CN_WORD",
"position" : 2
},
{
"token" : "员",
"start_offset" : 4,
"end_offset" : 5,
"type" : "CN_CHAR",
"position" : 3
},
{
"token" : "学习",
"start_offset" : 5,
"end_offset" : 7,
"type" : "CN_WORD",
"position" : 4
},
{
"token" : "java",
"start_offset" : 7,
"end_offset" : 11,
"type" : "ENGLISH",
"position" : 5
},
{
"token" : "太棒了",
"start_offset" : 11,
"end_offset" : 14,
"type" : "CN_WORD",
"position" : 6
},
{
"token" : "太棒",
"start_offset" : 11,
"end_offset" : 13,
"type" : "CN_WORD",
"position" : 7
},
{
"token" : "了",
"start_offset" : 13,
"end_offset" : 14,
"type" : "CN_CHAR",
"position" : 8
}
]
}
小结:
-
ik_smart:最小切分
-
ik_max_word:最细切分
2.3.2.2 扩展词词典
随着社会的发展,在原有的词汇列表中不是一个词的,但是现在已经是一个词了。比如:“白富美”,“高富帅” 等。
所以我们的词汇也需要不断的更新,IK分词器提供了扩展词汇的功能。
1)打开IK分词器config目录:
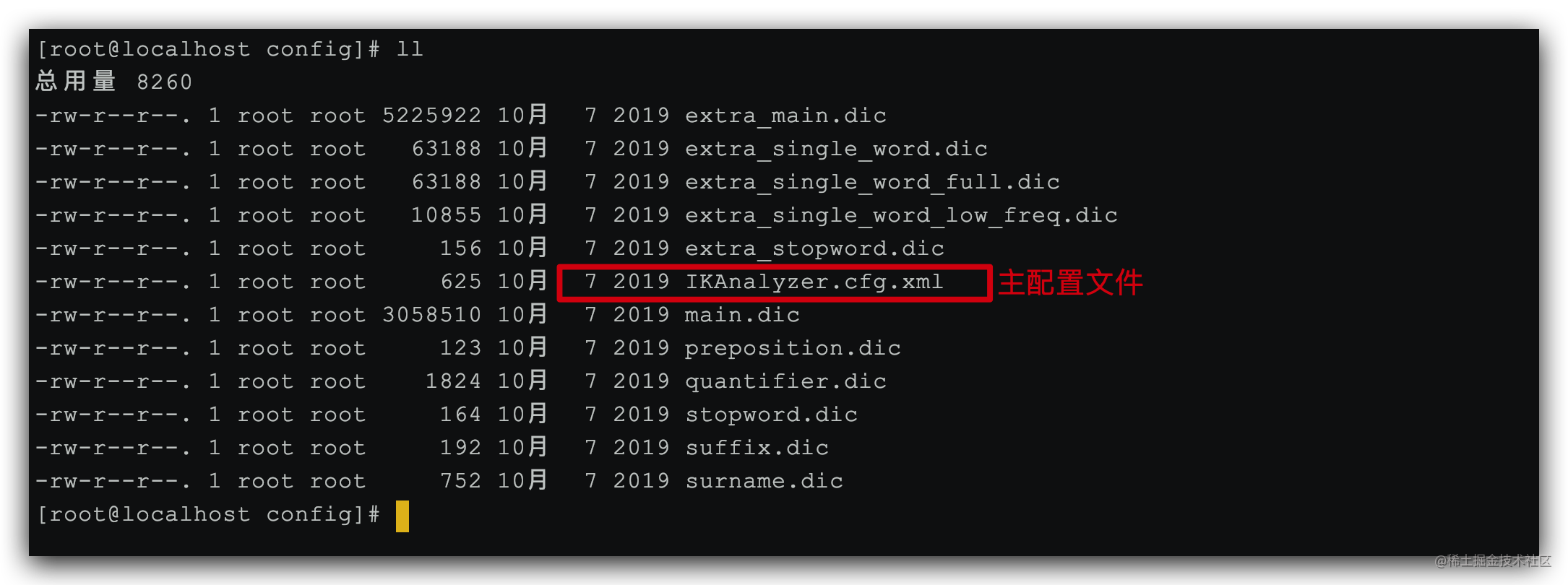
2)IKAnalyzer.cfg.xml配置文件内容添加:
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE properties SYSTEM "http://java.sun.com/dtd/properties.dtd">
<properties>
<comment>IK Analyzer 扩展配置</comment>
<!--用户可以在这里配置自己的扩展字典 *** 添加扩展词典-->
<entry key="ext_dict">ext.dic</entry>
<!--用户可以在这里配置自己的扩展停止词字典-->
<entry key="ext_stopwords"></entry>
<!--用户可以在这里配置远程扩展字典 -->
<!-- <entry key="remote_ext_dict">words_location</entry> -->
<!--用户可以在这里配置远程扩展停止词字典-->
<!-- <entry key="remote_ext_stopwords">words_location</entry> -->
</properties>
3)新建一个 ext.dic,可以参考config目录下复制一个配置文件进行修改
程序员
高富帅
白富美
我是一个爱学习的程序员
4)重启elasticsearch
docker restart elasticsearch
docker restart kibana
# 查看 日志
docker logs -f elasticsearch
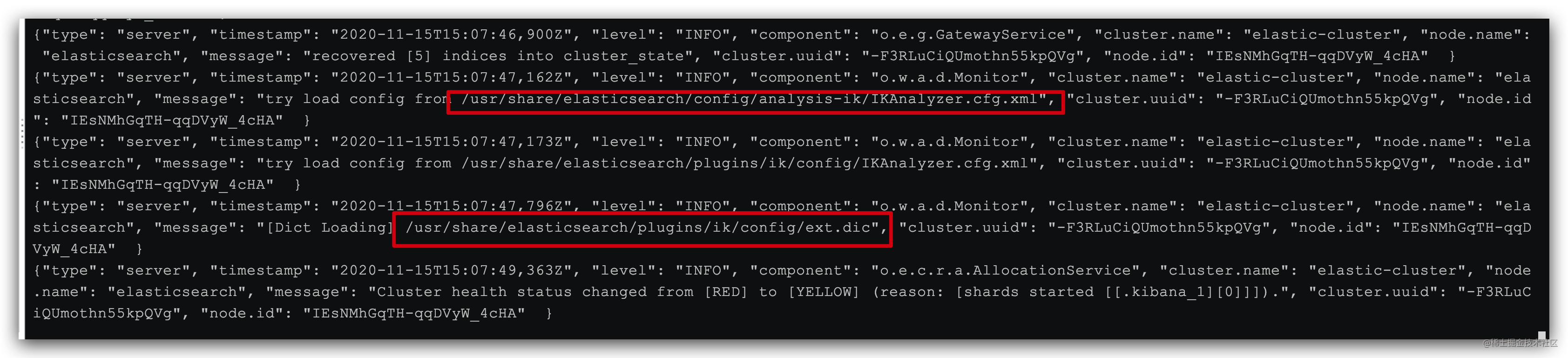
日志中已经成功加载ext.dic配置文件
5)测试效果:
GET /_analyze
{
"analyzer": "ik_max_word",
"text": "程序员里面也有高富帅,不知道有没有白富美"
}
注意当前文件的编码必须是 UTF-8 格式,严禁使用Windows记事本编辑
2.3.2.3 停用词词典
在互联网项目中,在网络间传输的速度很快,所以很多语言是不允许在网络上传递的,如:关于宗教、政治等敏感词语,那么我们在搜索时也应该忽略当前词汇。
IK分词器也提供了强大的停用词功能,让我们在索引时就直接忽略当前的停用词汇表中的内容。
1)IKAnalyzer.cfg.xml配置文件内容添加:
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE properties SYSTEM "http://java.sun.com/dtd/properties.dtd">
<properties>
<comment>IK Analyzer 扩展配置</comment>
<!--用户可以在这里配置自己的扩展字典-->
<entry key="ext_dict">ext.dic</entry>
<!--用户可以在这里配置自己的扩展停止词字典 *** 添加停用词词典-->
<entry key="ext_stopwords">stopword.dic</entry>
<!--用户可以在这里配置远程扩展字典 -->
<!-- <entry key="remote_ext_dict">words_location</entry> -->
<!--用户可以在这里配置远程扩展停止词字典-->
<!-- <entry key="remote_ext_stopwords">words_location</entry> -->
</properties>
3)在 stopword.dic 添加停用词
特朗普选举
4)重启elasticsearch
docker restart elasticsearch
docker restart kibana
# 查看 日志
docker logs -f elasticsearch
日志中已经成功加载stopword.dic配置文件
5)测试效果:
GET /_analyze
{
"analyzer": "ik_max_word",
"text": "特朗普选举失败"
}
注意当前文件的编码必须是 UTF-8 格式,严禁使用Windows记事本编辑