MMU是 MemoryManagementUnit 的缩写即,内存管理单元. 针对各种CPU, MMU是个可选的配件. MMU负责的是虚拟地址与物理地址的转换. 提供硬件机制的内存访问授权.(现代 CPU 的应用中,基本上都选择了使用 MMU)
现代的多用户多进程操作系统, 需要MMU, 才能达到每个用户进程都拥有自己的独立的地址空间的目标. 使用MMU, OS划分出一段地址区域,在这块地址区域中, 每个进程看到的内容都不一定一样. 例如MICROSOFT WINDOWS操作系统, 地址4M-2G处划分为用户地址空间. 进程A在地址 0X400000映射了可执行文件. 进程B同样在地址 0X400000映射了可执行文件. 如果A进程读地址0X400000, 读到的是A的可执行文件映射到RAM的内容. 而进程B读取地址0X400000时则读到的是B的可执行文件映射到RAM的内容.
2. MMU的产生
许多年以前,当人们还在使用DOS或是更古老的操作系统的时候,计算机的内存还非常小,一般都是以K为单位进行计算,相应的,当时的程序规模也不大,所以内存容量虽然小,但还是可以容纳当时的程序。但随着图形界面的兴起还用用户需求的不断增大,应用程序的规模也随之膨胀起来,终于一个难题出现在程序员的面前,那就是应用程序太大以至于内存容纳不下该程序,通常解决的办法是把程序分割成许多称为覆盖块(overlay)的片段。覆盖块0首先运行,结束时他将调用另一个覆盖块。虽然覆盖块的交换是由OS完成的,但是必须先由程序员把程序先进行分割,这是一个费时费力的工作,而且相当枯燥。人们必须找到更好的办法从根本上解决这个问题。不久人们找到了一个办法,这就是虚拟存储器(virtual memory).虚拟存储器的基本思想是程序,数据,堆栈的总的大小可以超过物理存储器的大小,操作系统把当前使用的部分保留在内存中,而把其他未被使用的部分保存在磁盘上比如对一个16MB的程序和一个内存只有4MB的机器,OS通过选择,可以决定各个时刻将哪4M的内容保留在内存中,并在需要时在内存和磁盘间交换程序片段,这样就可以把这个16M的程序运行在一个只具有4M内存机器上了。而这个16M的程序在运行前不必由程序员进行分割
3. MMU 作用
MMU 的作用:
1. 将虚拟地址翻译成为物理地址,然后访问实际的物理地址
2. 访问权限控制
4. MMU 工作过程
MMU 进行虚拟地址转换成为物理地址的过程是 MMU 工作的核心
大多数使用虚拟存储器的系统都使用一种称为分页(paging)。虚拟地址空间划分成称为页(page)的单位,而相应的物理地址空间也被进行划分,单位是页框(frame).页和页框的大小必须相同。接下来配合图片我以一个例子说明页与页框之间在MMU的调度下是如何进行映射的:

在这个例子中我们有一台可以生成16位地址的机器,它的虚拟地址范围从0x0000~0xFFFF(64K),而这台机器只有32K的物理地址,因此他可以运行64K的程序,但该程序不能一次性调入内存运行。这台机器必须有一个达到可以存放64K程序的外部存储器(例如磁盘或是FLASH)以保证程序片段在需要时可以被调用。在这个例子中,页的大小为4K,页框大小与页相同(这点是必须保证的,内存和外围存储器之间的传输总是以页为单位的),对应64K的虚拟地址和32K的物理存储器,他们分别包含了16个页和8个页框。
我们先根据上图解释一下分页后要用到的几个术语,在上面我们已经接触了页和页框,上图中绿色部分是物理空间,其中每一格表示一个物理页框。橘黄色部分是虚拟空间,每一格表示一个页,它由两部分组成,分别是Frame Index(页框索引)和位p(present 存在位),Frame Index的意义很明显,它指出本页是往哪个物理页框进行映射的,位p的意义则是指出本页的映射是否有效,如上图,当某个页并没有被映射时(或称映射无效,Frame Index部分为X),该位为0,映射有效则该位为1。
我们执行下面这些指令(本例子的指令不针对任何特定机型,都是伪指令)
例1:
MOVE REG,0 //将0号地址的值传递进寄存器REG
虚拟地址0将被送往MMU,MMU看到该虚地址落在页0范围内(页0范围是0到4095),从上图我们看到页0所对应(映射)的页框为2(页框2的地址范围是8192到12287),因此MMU将该虚拟地址转化为物理地址8192,并把地址8192送到地址总线上。内存对MMU的映射一无所知,它只看到一个对地址8192的读请求并执行它。MMU从而把0到4096的虚拟地址映射到8192到12287的物理地址。
例2:
MOVE REG,8192
被转换为
MOVE REG,24576
因为虚拟地址8192在页2中,而页2被映射到页框6(物理地址从24576到28671)
例3:
MOVE REG,20500
被转换为
MOVE REG,12308
虚拟地址20500在虚页5(虚拟地址范围是20480到24575)距开头20个字节处,虚页5映射到页框3(页框3的地址范围是 12288到16383),于是被映射到物理地址12288+20=12308。
通过适当的设置MMU,可以把16个虚页隐射到8个页框中的任何一个,但是这个方法并没有有效的解决虚拟地址空间比物理地址空间大的问题。从上图中我们可以看到,我们只有8个页框(物理地址),但我们有16个页(虚拟地址),所以我们只能把16个页中的8个进行有效的映射。我们看看例4会发生什么情况:
例4:
MOV REG,32780
虚拟地址32780落在页8的范围内,从上图总我们看到页8没有被有效的进行映射(该页被打上X),这是又会发生什么?MMU注意到这个页没有被映射,于是通知CPU发生一个缺页故障(page fault).这种情况下操作系统必须处理这个页故障,它必须从8个物理页框中找到1个当前很少被使用的页框并把该页框的内容写入外围存储器(这个动作被称为page copy),随后把需要引用的页(例4中是页8)映射到刚才释放的页框中(这个动作称为修改映射关系),然后从新执行产生故障的指令(MOV REG,32780)。假设操作系统决定释放页框1,那么它将把虚页8装入物理地址的4-8K,并做两处修改:首先把标记虚页1未被映射(原来虚页1是被影射到页框1的),以使以后任何对虚拟地址4K到8K的访问都引起页故障而使操作系统做出适当的动作(这个动作正是我们现在在讨论的),其次他把虚页8对应的页框号由X变为1,因此重新执行MOV REG,32780时,MMU将把32780映射为4108。
我们大致了解了MMU在我们的机器中扮演了什么角色以及它基本的工作内容是什么,下面我们将举例子说明它究竟是如何工作的(注意,本例中的MMU并无针对某种特定的机型,它是所有MMU工作的一个抽象)。
首先明确一点,MMU的主要工作只有一个,就是把虚拟地址映射到物理地址。
我们已经知道,大多数使用虚拟存储器的系统都使用一种称为分页(paging)的技术,就象我们刚才所举的例子,虚拟地址空间被分成大小相同的一组页,每个页有一个用来标示它的页号(这个页号一般是它在该组中的索引,这点和C/C++中的数组相似)。在上面的例子中0~4K的页号为0,4~8K的页号为1,8~12K的页号为2,以此类推。而虚拟地址(注意:是一个确定的地址,不是一个空间)被MMU分为2个部分,第一部分是页号索引(page Index),第二部分则是相对该页首地址的偏移量(offset). 。我们还是以刚才那个16位机器结合下图进行一个实例说明,该实例中,虚拟地址8196被送进MMU,MMU把它映射成物理地址。16位的CPU总共能产生的地址范围是0~64K,按每页4K的大小计算,该空间必须被分成16个页。而我们的虚拟地址第一部分所能够表达的范围也必须等于16(这样才能索引到该页组中的每一个页),也就是说这个部分至少需要4个bit。一个页的大小是4K(4096),也就是说偏移部分必须使用12个bit来表示(2^12=4096,这样才能访问到一个页中的所有地址),8192的二进制码如下图所示:
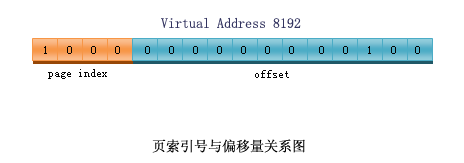
该地址的页号索引为0010(二进制码),既索引的页为页2,第二部分为000000000100(二进制),偏移量为4。页2中的页框号为6(页2映射在页框6,见上图),我们看到页框6的物理地址是24~28K。于是MMU计算出虚拟地址8196应该被映射成物理地址24580(页框首地址+偏移量=24576+4=24580)。同样的,若我们对虚拟地址1026进行读取,1026的二进制码为0000010000000010,page index="0000"=0,offset=010000000010=1026。页号为0,该页映射的页框号为2,页框2的物理地址范围是8192~12287,故MMU将虚拟地址1026映射为物理地址9218(页框首地址+偏移量=8192+1026=9218)。以上就是MMU的工作过程。
5. MMU 的 TLB
由上面的例子可知,在 MMU 工作的时候,软件也需要进行配合,软件需要准备一张表,来告诉 MMU 当前的地址映射的关系(即,虚拟地址和物理地址的对应关系)。而这张表存储在内存中(代码的数据结构),每次 MMU 工作的时候,都去便利这个表里面的关系,然后找到对应的映射,这个过程叫做 table walk。这样会严重影响系统效率。于是乎,MMU 中增加了 Cache,这个 Cache 叫做 TLB。
为了减少存储器访问的平均消耗, 转换表遍历结果被高速缓存在一个或多个叫作 Translation Lookaside Buffers(TLBs)的结构中。通常在ARM 的实现中每个内存接口有一个TLB。当存储器中的转换表被改变或选中了不同的转换表(通过写CP15 的寄存器,先前高速缓存的转换表遍历结果将不再有效。MMU 结构提供了刷新TLB 的操作。MMU 结构也允许特定的转换表遍历结果被锁定在一个TLB 中,这就保证了对相关的存储器区域的访问绝不会导致转换表遍历,这也对那些把指令和数据锁定在高速缓存中的实时代码有相同的好处。
当ARM 要访问存储器时,MMU 先查找 TLB 中的虚拟地址表,如果没有命中,则,还是要去走 table walk 的流程。即,如果TLB 中没有虚拟地址的入口,则转换表遍历硬件从存在主存储器中的转换表中获取转换和访问权限。一旦取到,这些信息将被放在 TLB 中,它会放在一个没有使用的入口处或覆盖一个已有的入口。
关于更多的 ARM 架构的 MMU 以及如何和 Linux 分页机制进行配合的步伐,在后续进行分析。