简单查询
term
单词查询
- 对于不分词的字段(数组视同普通字段,查询数组字段时,只要匹配上一项就算匹配)条件直接匹配字段值
- 对于分词的字段;在字段倒排索引表,仅限分词结果内查找条件值
terms
同样是单词查询;但条件值可以是多个值,效果为 term1 or term2
should : [
{term1…}, {term2…}
]
range
数值范围查询
"range": {
"FIELD": {
"gte": 10,
"lte": 20
}
}
match
match 匹配字段,会对条件分词,然后每个词以or的关系在文档倒排索引内进行查询
match:对于不分词的字段直接匹配值;
对于分词的字段,先进行分词得到词典,然后对词典执行tern的组合(or 或 and,默认为 or )
GET bank/_search
{
"query": {
"match": {
"address": "244 Columbus Place"
},
"match": {
"name": {
"query": "条件值",
"operator": "and/or"
}
}
}
}
可以看到
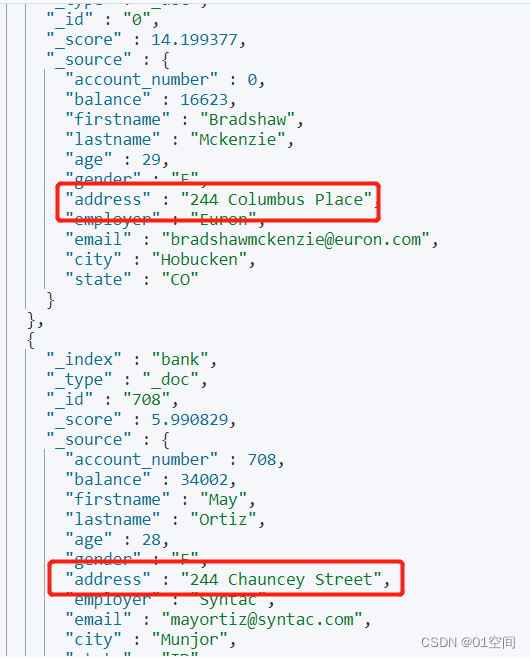
上面两条数据的 address 的相同点就是 都有244。
debug 查看分词结果
GET _analyze
{
"text": ["244 Columbus Place"]
}
# res 可以看到,拆分成了 244,columbus,place;
# 实际查询条件为 244 or columbus or place
{
"tokens" : [
{
"token" : "244",
"start_offset" : 0,
"end_offset" : 3,
"type" : "<NUM>",
"position" : 0
},
{
"token" : "columbus",
"start_offset" : 4,
"end_offset" : 12,
"type" : "<ALPHANUM>",
"position" : 1
},
{
"token" : "place",
"start_offset" : 13,
"end_offset" : 18,
"type" : "<ALPHANUM>",
"position" : 2
}
]
}
match_phrase
不对条件值分词,直接拿到文档里面找;只要能找到这个完整的关键词就能匹配。
文档字段包含这个词就能匹配
查询连续的多个完整词
GET bank/_search
{
"query": {
"match_phrase": {
"address": "244 Columbus Place"
}
}
}
# 可以看到,只查询到一条数据
{
"took" : 7,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 1,
"relation" : "eq"
},
"max_score" : 14.199377,
"hits" : [
{
"_index" : "bank",
"_type" : "_doc",
"_id" : "0",
"_score" : 14.199377,
"_source" : {
"account_number" : 0,
"balance" : 16623,
"firstname" : "Bradshaw",
"lastname" : "Mckenzie",
"age" : 29,
"gender" : "F",
"address" : "244 Columbus Place",
"employer" : "Euron",
"email" : "bradshawmckenzie@euron.com",
"city" : "Hobucken",
"state" : "CO"
}
}
]
}
}
match_phrase_prefix
查询多个连续的词(term),最后一个词 以 prefix 查询
举例:name = my name is tony
查询条件值为 my n
match_phrase 查不到数据,因为 n 没有在字段分词找到对应的词
match_phrase_prefix 能查到数据,最后一个条件 值为 n,对n执行前缀查询,所以能查到
match_bool_prefix
条件分词后,前面的词以 term 查询,最后一个以 prefix 查询
should [
term: 条件分词1,
term: 条件分词2,
prefix:最后一个条件词
]
multi_match
友视需要在多个字段上查询相同条件。比如搜索商品关键词,既可以在商品名称上匹配,也可以在品牌名称上匹配
"multi_match": {
"query": "条件值",
"fields": ["goods_name", "brand"]
}
复合查询
在实际使用中,往往是在多个条件下查询数据。
bool 查询
在 query 下使用 bool 聚合多条件,通过组合内部多个条件的逻辑关系,形成最终的查询条件。
bool 内部 must ,must_not,filter,should 之间为与的关系
以下查询条件为:
- address 分词匹配 244 Columbus Plac 且 age = 29
GET bank/_search
{
"query": {
"bool": {
"must": [
{
"match": {
"address": "244 Columbus Place"
}
},
{
"match": {
"age": 29
}
}
]
}
}
}
标记数据匹配的条件
查询结果还可以标记当前记录,匹配上了哪些条件
在查询中,指定查询条件值时:
_name标记当前条件
实际测试下来,不同查询方式,写法还不太一样
"term": {
"age": {
"value": "30",
"_name": "age"
}
}
"terms": {
"age": ["30"],
"_name": "age"
}
"match": {
"name": { 字段名
"query": "四",
"_name": "name"
}
}
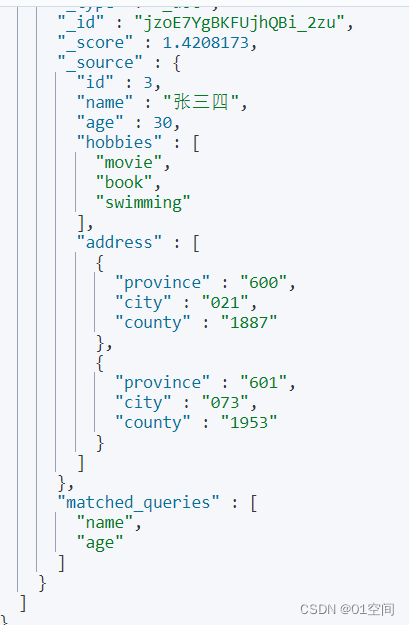
可以看到最后有一个 matched_queries字段,说明本条记录是匹配了哪些条件。
但是,这个机制好像对嵌套查询没效果,后续有机会再了解
bool 子元素区别
- must: 与 (内部做与运算)
- must_not:非(内部做 与 运算,最后在外层做非运算)不进行相关性评分,不影响整体评分
- should:或 (内部做 或运算)
- filter 过滤器,单纯过滤,先于 上述条件执。,不进行相关性评分,不影响整体评分,会使用过滤器缓存。速度更快。
每个元素内部,还可以嵌套复杂条件(再来一层bool)
boosting 查询(人为降低指定条件得分)
在bool查询中,我们的查询结果是将 bool 内部的所有条件做 与运算,
所有都匹配的数据会查出来,并根据相关性进行计分,默认倒序排列。
而 boosting 查询,则是
先根据 positive下的条件查询结果并得出一个初始评分,
再根据negative 下的条件匹配查询结果,如果匹配上了,则再根据negative_boost的值对其进行降分的处理,使其排名降低。
# boosting 查询
GET /stu/_search
{
"query": {
"boosting": {
"positive": {
"match_phrase": {
"name": {
"query": "张三",
"_name": "name"
}
}
},
"negative": {
"term": {
"age": {
"value": "30",
"_name": "age"
}
}
},
"negative_boost": 0.2
}
}
}
简单总结,就是 以 positive 查询数据,再以 negative + negative_boost 对结果降分
constant_score 查询(固定得分)
普通的查询相关性分数是es根据相关性确定的,在此基础上,我们可以通过boosting查询降低匹配特定指标的分数。
还有一种,我们可以返回固定分数。
通过前面的学习,我们知道在 bool 查询中 filter 和 must_not 是不计算分数的;因此 constant_score查询其实就是通过 filter查询,然后为其指定固定分数实现。
# constant_score 查询
GET /stu/_search
{
"query": {
"constant_score": {
"filter": { # 查询条件
"term": {
"age": "30"
}
},
"boost": 1.2 # 固定分数
}
}
}
dis_max 查询(单条件 最高分)
其他查询,最终得分是由所有query综合得分构成。
而dis_max 查询只取评分最高的那一项查询,而忽略其他条件的评分
以下条件查询 name 匹配 张三 或者 hobbies 包含 book 的用户
GET /stu/_search
{
"query": {
"dis_max": {
"queries": [
{
"match": {
"name": "张三"
}
},
{
"match": {
"hobbies": "book"
}
}
]
}
}
}
得到以下得分
"hits" : [
{
"_index" : "stu",
"_type" : "_doc",
"_id" : "jToE7YgBKFUjhQBivmyC",
"_score" : 0.9983525,
"_source" : {
"id" : 1,
"name" : "张三",
"age" : 10,
"hobbies" : [
"swimming",
"walk",
"drive"
],
"address" : [
{
"province" : "500",
"city" : "023",
"county" : "1991"
},
{
"province" : "501",
"city" : "024",
"county" : "1992"
}
]
}
},
{
"_index" : "stu",
"_type" : "_doc",
"_id" : "jzoE7YgBKFUjhQBi_2zu",
"_score" : 0.9808291,
"_source" : {
"id" : 3,
"name" : "张三四",
"age" : 30,
"hobbies" : [
"movie",
"book",
"swimming"
],
"address" : [
{
"province" : "600",
"city" : "021",
"county" : "1887"
},
{
"province" : "601",
"city" : "073",
"county" : "1953"
}
]
}
}
]
| 条件 |
得分 |
| 张三_name |
0.9983525 |
| 张三_hobbies |
0 |
| 张三四_name |
0.8416345 |
| 张三四_hobbies |
0.9808291 |
可以看到,第一条记录虽然只匹配上了 name = 张三,但是它的得分是 0.9983525,
而第二条记录虽然匹配上了两个条件 ,但是单算 name = 张三四 的评分只有 0.8416345,而 单算 hobbies 含有 book 的得分为 0.9808291,因此第二条记录采用了 较高匹配度的 hobbies 的得分。
总体算下来,低于第一条
算上其他 query 的得分
只使用 dis_max 会完全忽略其他query条件的得分,可能导致最终结果,不准确;因此,我们可以算上其他query的得分。
通过 参数 tie_breaker 来指定其他query得分的缩小比例,取值范围 [0, 1],当这个值为1时,其效果了 bool 查询一致。
这里我们将缩小比例设置为0.7,再看看查询的结果
GET /stu/_search
{
"query": {
"dis_max": {
"queries": [
{
"match": {
"name": "张三"
}
},
{
"match": {
"hobbies": "book"
}
}
],
"tie_breaker": 0.7
}
}
}

可以看到,张三四 在 hobbies 的基础之上,加上 name 的分数已经超越了 张三。
再结合上面表格单项得分,“tie_breaker”: 0.7
张三得分 = 0.9983525 + 0 = 0.9983525
张三四得分 = 0.9808291 + 0.8416345 * 0.7 = 1.56997325
与上图相符。
function_score 查询
使用函数自定义评分逻辑;可以使用内置函数或脚本完全自定义评分逻辑。
内置函数
- weight 对当前分值做 乘法,实现 增加或减少
- random_score :生成随机分数
- field_value_factor :将文档指定字段(数值或者可转化为数值)纳入得分计算。
- 衰减函数 - linear,exp,gauss 等
- script_score 使用脚本,完全自定义评分逻辑
我们还可以使用 functions 为不同匹配条件指定不同的计分逻辑;匹配上了执行对应的计分逻辑,未匹配上的得1分,未匹配上的数据也会展示出来
functions 外面的查询及其评分只展示匹配上的数据;如果外面没有过滤,只在 functions 内进行查询和评分,那么评分逻辑只作用于匹配上的数据,未匹配上的数据统统1分
自定义函数有个计分计算方式字段 “boost_mode”: “multiply” 默认是乘法(weight及field 方式都是乘以现有分数)。
weight 成倍增减现有得分
GET /stu/_search
{
"query": {
"function_score": {
"query": {
"match": {
"name": "张三"
}
},
"weight": 0.5,
"boost_mode": "multiply"
}
}
}
两条数据
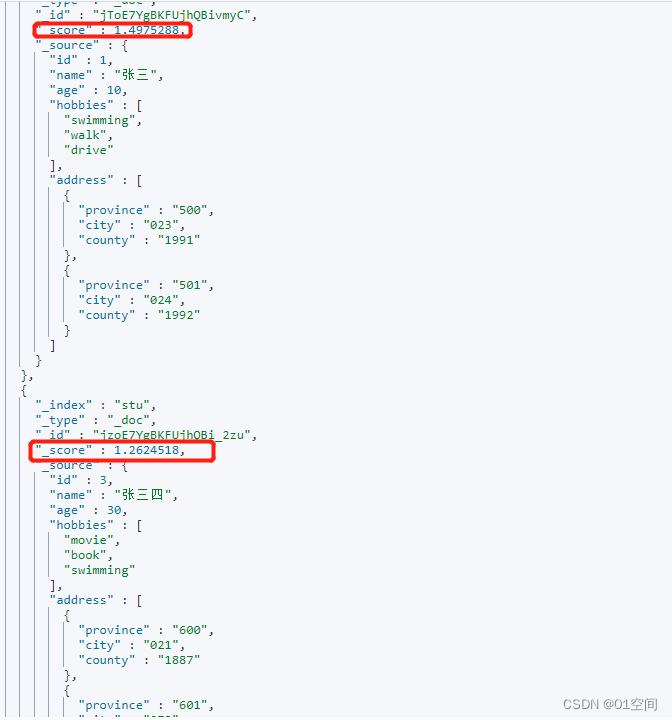
random_score 随机得分
GET /stu/_search
{
"query": {
"function_score": {
"query": {
"match": {
"name": "张三"
}
},
"random_score": {}
}
}
}
两条数据,随机得分
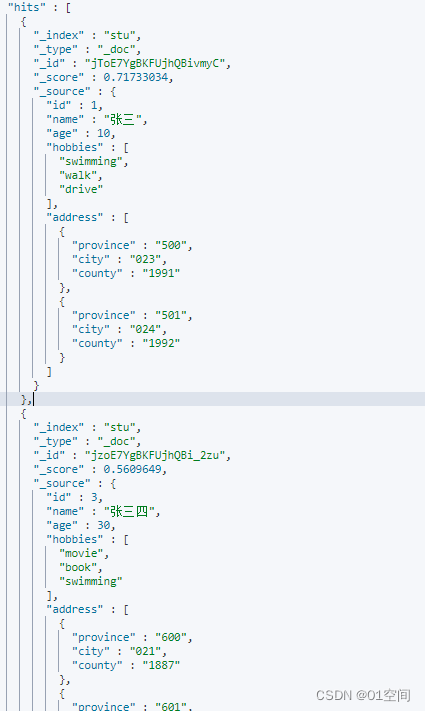
指定字段(数值或者可转为数值)纳入计分
GET /stu/_search
{
"query": {
"function_score": {
"query": {
"match": {
"name": "张三"
}
},
"field_value_factor": {
"field": "age"
}
}
}
}
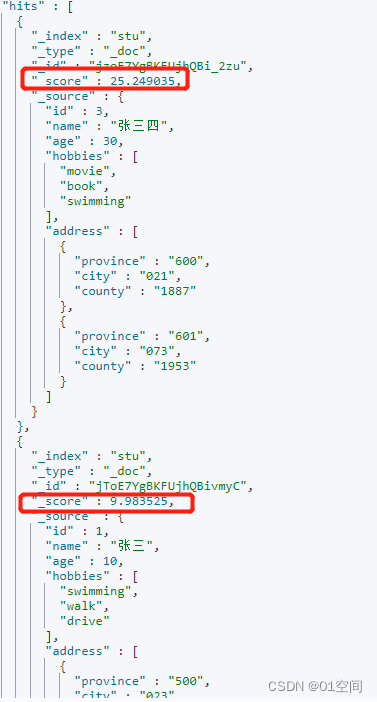
以下得分 = 现有得分 * 字段值 (age)* 比例(factor 默认为1) = 0.9983525 * 30 * 1 = 25.249035
自定义脚本得分
使用脚本完全自定义得分逻辑
直接以age为得分
script_score.script :指定得分计算方式,直接取 age 的值
boost_mode:replace;默认是 multiply,还是与age做乘法;使用replace,则是直接替换原有的分数而不做乘法。
# 直接以age得分
GET /stu/_search
{
"query": {
"function_score": {
"query": {
"match": {
"name": "张三"
}
},
"script_score": {
"script": "doc['age'].value"
},
"boost_mode": "replace"
}
}
}
因此得到分数分别为二者的 age
