Kafka就不介绍了,主要记录下安装的过程。
1、安装kafka得先安装jdk:
可以使用以下命令查看下是否有安装过jdk:
rpm -qa | grep jdk
没有则运行一下命令安装jdk
yum install java-1.8.0-openjdk* -y
可以通过以下命令查看到安装目录:
which java
2、kafka是依赖zookeeper的,所以得安装zookeeper先
选择一个目录下载一下zookeeper
wget https://dlcdn.apache.org/zookeeper/zookeeper-3.7.1/apache-zookeeper-3.7.1-bin.tar.gz
// 解压下
tar -zxvf apache-zookeeper-3.7.1-bin.tar.gz
cd apache-zookeeper-3.7.1-bin
启动zookeeper:
// 启动zookeeper,当前目录:/xxx/zookeeper/apache-zookeeper-3.7.1-bin
bin/zkServer.sh start

客户端连接zookeeper:
// 连接客户端
bin/zkCli.sh
// 查看zk根目录节点
ls /

安装kafka
先下载kafka安装包:https://archive.apache.org/dist/kafka
# 下载 : kafka版本号是2.8.1,2.12是scala的版本号,kafka是用scala语音开发的
wget https://archive.apache.org/dist/kafka/2.8.1/kafka_2.12-2.8.1.tgz
# 解压
tar -xzf kafka_2.12-2.8.1.tgz
cd kafka_2.12-2.8.1
# 修改配置文件
config/server.properties
配置文件config/server.properties需要改动的信息:
# broker实例的唯一号
broker.id=0
# kafka的服务ip号和提供的端口
listeners=PLAINTEXT://localhost:9092
# 日志文件存储地址
log.dirs=/tmp/kafka-logs
# zookeeper的连接地址
zookeeper.connect=localhost:2181
这里需要注意一点的是,当你的listeners配置的是ip地址,则需要将ip地址和主机名绑定到/etc/hosts 文件里:
# 查看主机名:
hostname
vim /etc/hosts
#格式如下:
# 第一部份:网络IP地址; 第二部份:主机名或域名; 第三部份:主机名别名;
192.168.88.255 hostname1
现在就可以启动下kafka了。
# daemon 表示后台启动,在kafka安装目录下执行的命令
bin/kafka-server-start.sh -daemon config/server.properties
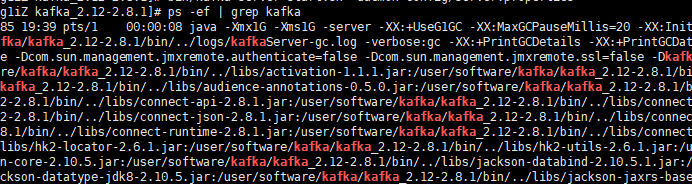
可以使用命令查看是否启动成功:
ps -ef | grep kafka
进入zookeeper里查看数据可以看到和刚开始安装时的节点不一样了:


可以看到多了很多节点。
其中kafka的实例节点只有一个,上图中的 ls /brokers/ids 命令查询所示。
关闭kafka服务:
bin/kafka-server-stop.sh
至此kafka就搭建完成了。
kafka集群搭建
kafka的集群搭建起来更加方便,只是启动多个kafka实例就好了,使用同一个zookeeper的服务注册中心。
复制两份配置文件:
# 切换到config目录下
cp server.properties server-2.properties
cp server.properties server-3.properties
然后修改两个配置信息的端口号等信息:
# server-2.properties
broker.id=1
listeners=PLAINTEXT://localhost:9093
log.dirs=/xxxx/kafka/data/logs2
# server-3.properties
broker.id=2
listeners=PLAINTEXT://localhost:9094
log.dirs=/xxxx/kafka/data/logs3
然后启动下:
bin/kafka-server-start.sh -daemon config/server.properties
bin/kafka-server-start.sh -daemon config/server-2.properties
我就启动了0和1的id实例。可以看到下面检测到的实例就两个

然后就可以查看到zookeeper上注册了几个broker实例了。

就ok了,就是这么简单。