集群
对于kafka来说,一个单独的broker意味着kafka集群中只有一个节点。要想增加kafka集群中的节点数量,只需要多启动几个broker实例即可,为了有更好的理解,现在我们在一台机器上同时启动三个broker实例。
1. 搭建个集群
建立好2个broker的配置文件:
cp config/server.properties config/server-1.properties
cp config/server.properties config/server-2.properties
针对配置文件进行修改:
server-1.properties
#broker.id属性在kafka集群中必须要是唯一
broker.id=1
#kafka部署的机器ip和提供服务的端口号
listeners=PLAINTEXT://192.168.65.60:9093
log.dir=/usr/local/data/kafka-logs-1
#kafka连接zookeeper的地址,要把多个kafka实例组成集群,对应连接的zookeeper必须相同
zookeeper.connect=192.168.65.60:2181
config/server-2.properties:
broker.id=2
listeners=PLAINTEXT://192.168.65.60:9094
log.dir=/usr/local/data/kafka-logs-2
zookeeper.connect=192.168.65.60:2181
确定这两个实例:
bin/kafka-server-start.sh -daemon config/server-1.properties
bin/kafka-server-start.sh -daemon config/server-2.properties
现在我们创建一个新的topic,副本数设置为3,分区数设置为2:
bin/kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 3 --partitions 2 --topic my-replicated-topic
查看一下topic的情况:
bin/kafka-topics.sh --describe --zookeeper localhost:2181 --topic my-replicated-topic

- leader节点负责给定partition 的所有读写请求,同一个topic不同分区的leader副本一般不一样(为了容灾)。比如图上一共有两个分区,分区1的leader在broker11,分区0的leader在broker0。
- replicas 表示某个partition在哪几个broker上存在备份。不管这几个点是不是“leader”,甚至这个节点挂了,也会列出。
- isr 是replicas的一个子集,它只列出当前还存活着的,并且已同步备份了该partition的节点。
2. 集群发送消息
现在我们向新建的 my-replicated-topic 中发生了一些message,kafka集群可以加上所有kafka节点:
./kafka-console-producer.sh --broker-list localhost:9092,localhost:9093,localhost:9094 --topic my-replicated-topic
现在我们向新建的 my-replicated-topic 中发送一些message,kafka集群可以加上所有kafka节点:
./kafka-console-consumer.sh --bootstrap-server localhost:9092,localhost:9093,localhost:9094 --from-beginning --topic my-replicated-topic
现在我们来测试我们容错性,因为broker1目前是my-replicated-topic的分区0的leader,所以我们要将其kill:
ps -ef | grep server.properties ## 找到broker进程。
kill 48028 ## 杀死掉
现在执行命令:
bin/kafka-topics.sh --describe --zookeeper localhost:9092 --topic my-replicated-topic

我们可以看到,分区0的leader节点已经变成了broker0.要注意的是,在isr中,已经没有1号节点,leader的选举也是从ISR(in-sync replica)中进行的。
此时,我们依然可以消费消息:
bin/kafka-console-consumer.sh --bootstrap-server localhost:9092,localhost:9093,localhost:9094 --from-beginning --topic my-replicated-topic
my test msg 1
my test msg 2
查看主题分区对应的leader信息:

kafka将很多集群关键信息记录在zookeeper里,保证自己的无状态,从而在水平扩容时非常方便。
3. 集群消费
log的partitions分布在kafka集群中不同的broker上,每个broker可以请求备份其他broker上partition上的数据。kafka集群支持配置一个partition备份的数量。
针对每个partition,都有一个broker起到“leader”作用,0个或多个其他的broker作为“follwers”的作用。leader处理所有的针对这个partition的读写请求,而followers被动复制leader的结果,不提供读写(主要是为了保证多副本数据与消费的一致性)。如果这个leader失效了,其中的一个follower将会自动的变成新的leader。
3.1 Procuder
生产者将消息发送到topic中去,通知负责选择message发送到topic的哪一个partition中。通过round-robin做简单的负载均衡。也可以根据消息中的某个关键字来进行区分。通常第二种方式使用的更多。
3.2 Consumer
传统的消息传递模式有2中:队列(queue)和(publish-subscribe)
- queue模式:多个consumer从服务器中读取数据,消息只会到达一个consumer。
- publish-subscribe模式:消息会被广播给所有的consumer。
kafka基于这2中模式提供了一种consumer的抽象概念:consumer-group
- queue模式:所有的consumer都位于同一个consumer group 下
- publish-subscribe模式:所有的consumer都有着自己唯一的consumer group
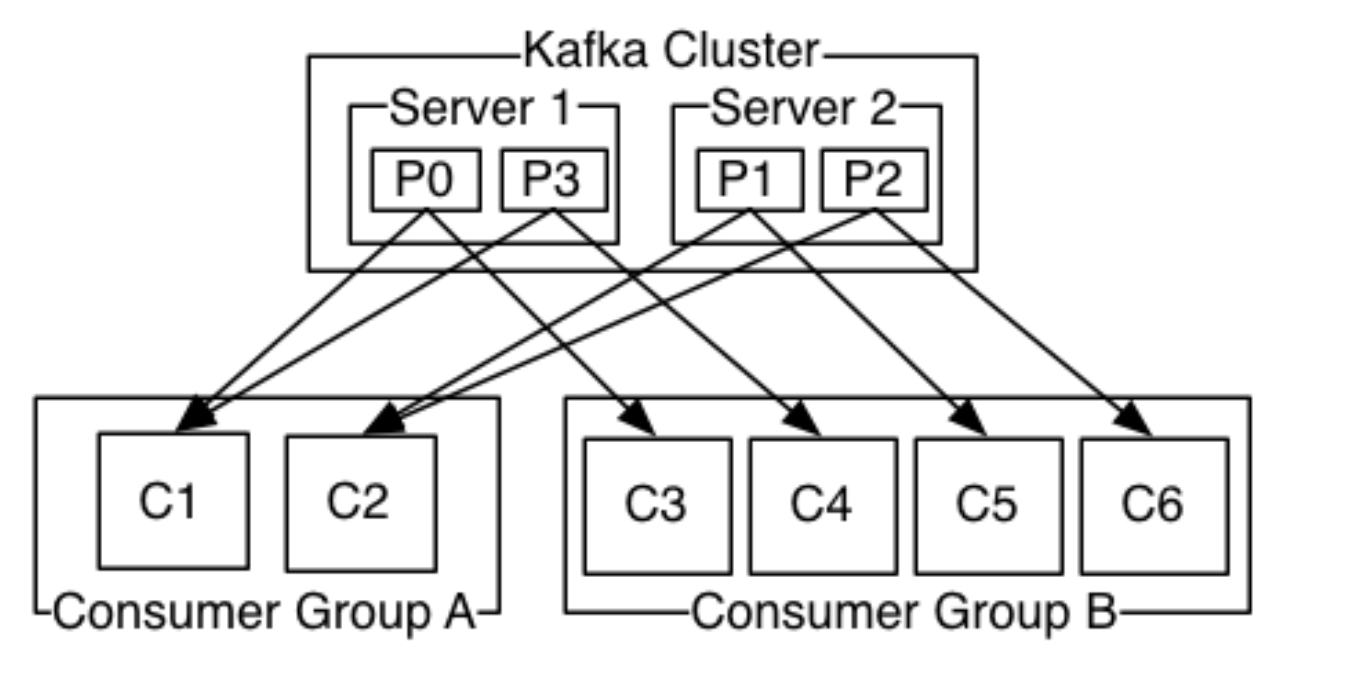
上图说明:由2个broker组成的kafka集群,某个主题总共有4个partition(P0-P3),分别位于不同的broker上。这个集群由2个consumer group消费,A有2个consumer instances,B有4个。
通常一个topic 会有几个consumer group。每个consumer group 都是一个逻辑上的订阅者(logical subscriber)。每个consumer group 有多个consumer instance组成,从而达到可扩展和容灾的功能。
4. 消费顺序
一个partition同一时刻在一个consumer group 中只能有一个consumer instance消费,从而保证消费顺序。
consumer group 中的consumer instance 的数量不能比一个Topic中的partition的数量多,否则,多出来的consumer消费不到消息。
Kafka只能在partition 的范围内保证消息消费的局部顺序性,不能在同一个topic中的多个partition中保证总的顺序性。
如果有在总体上保证消费顺序的需求,那么我们可以通过将topic的partition数量设置为1,将consumer group 中的consumer instance的数量也设置为1,但是这样会影响性能,所以kafka的顺序消费很少用。