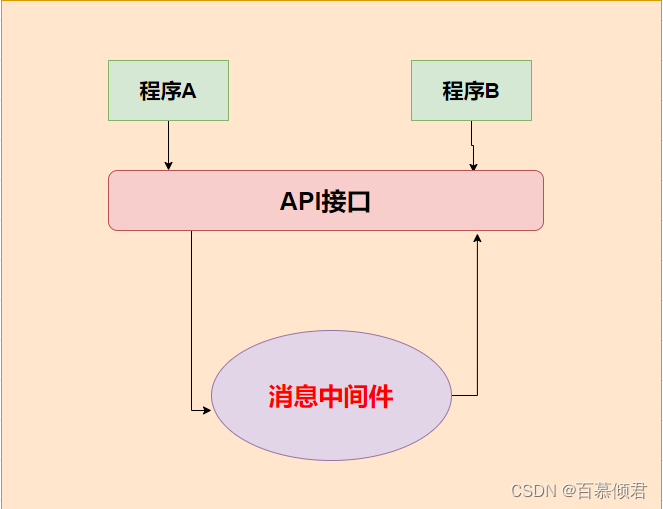
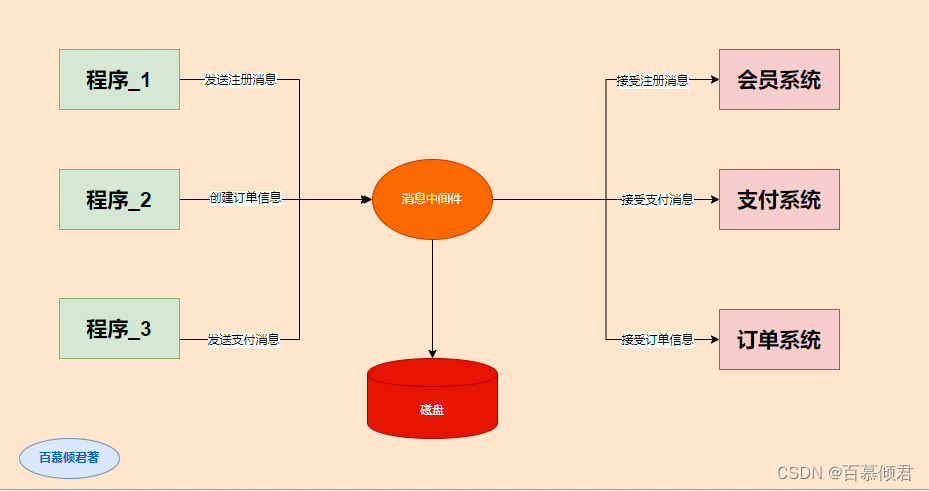
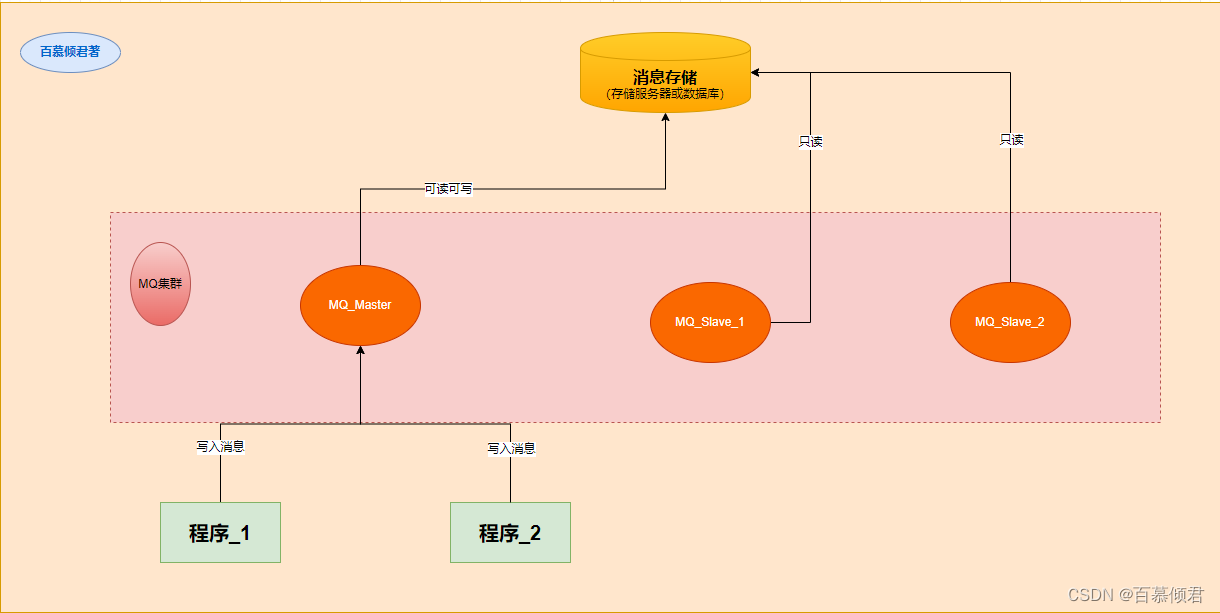
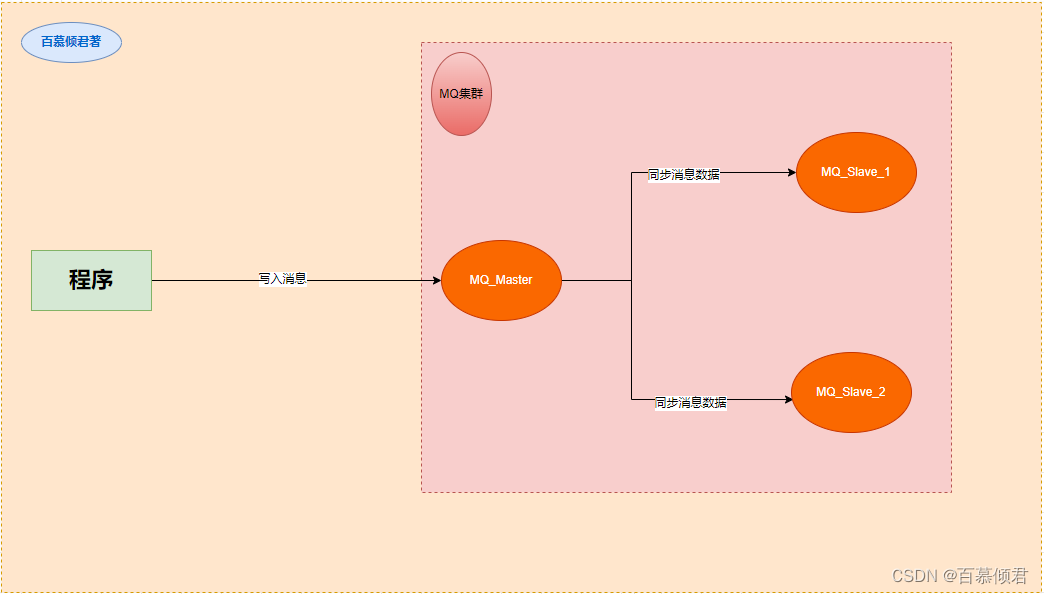
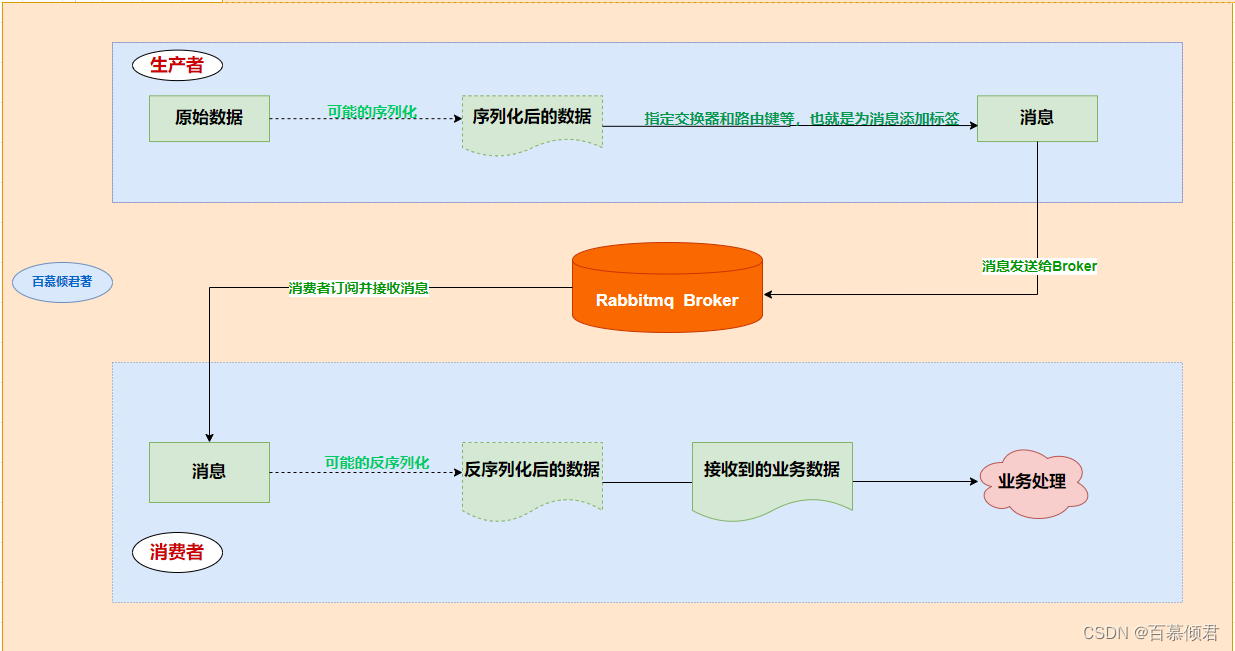
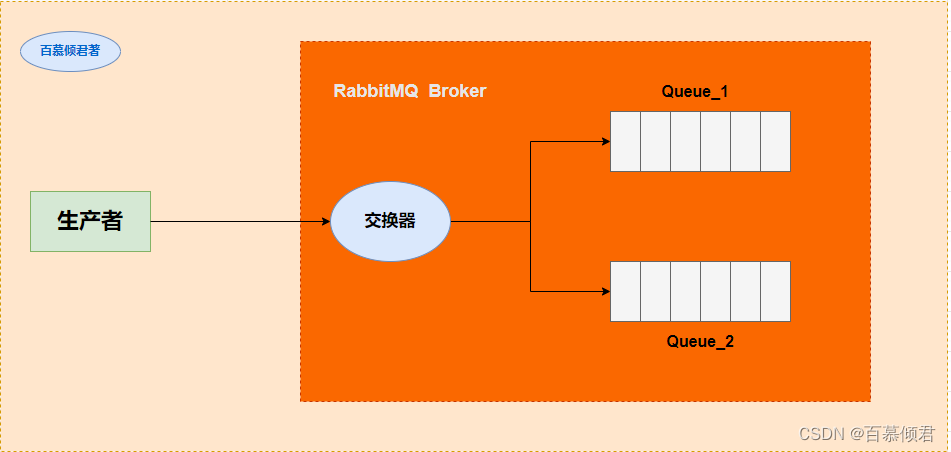
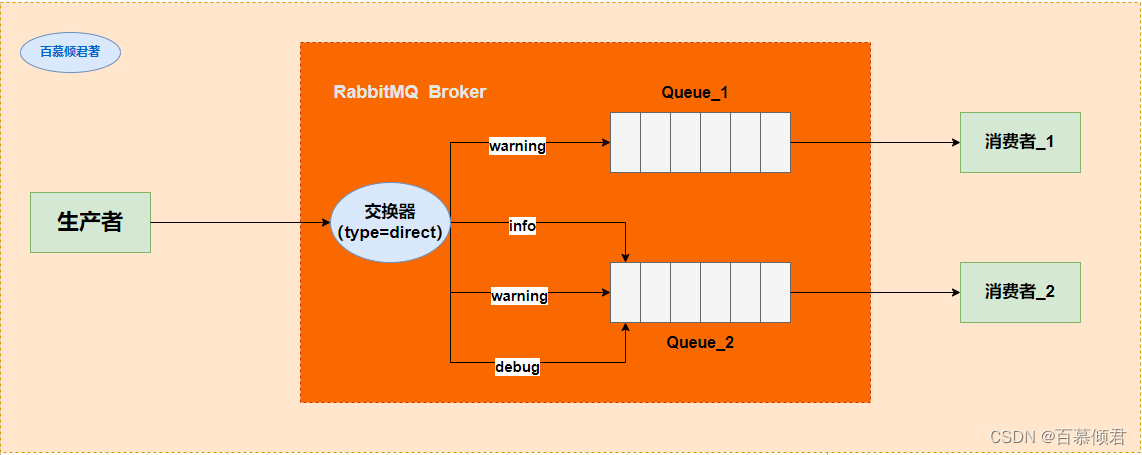
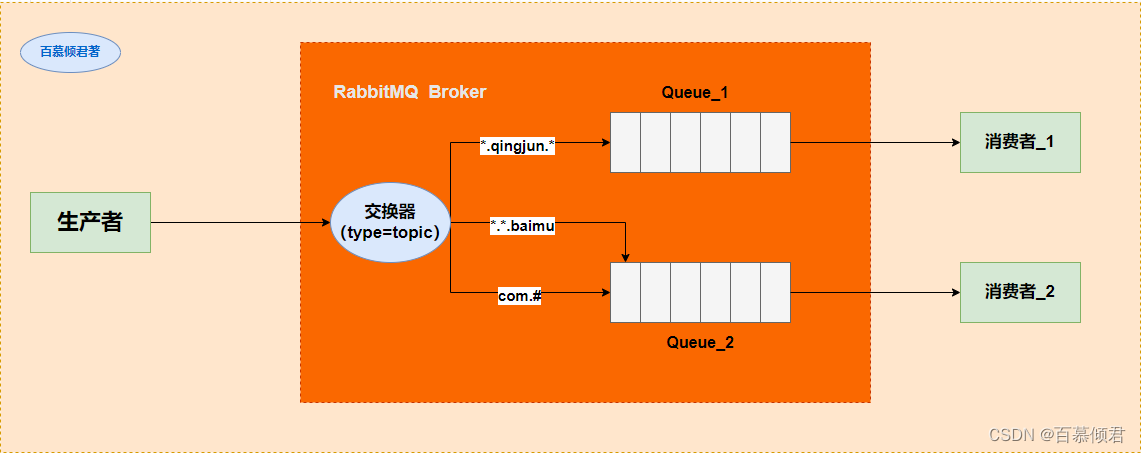
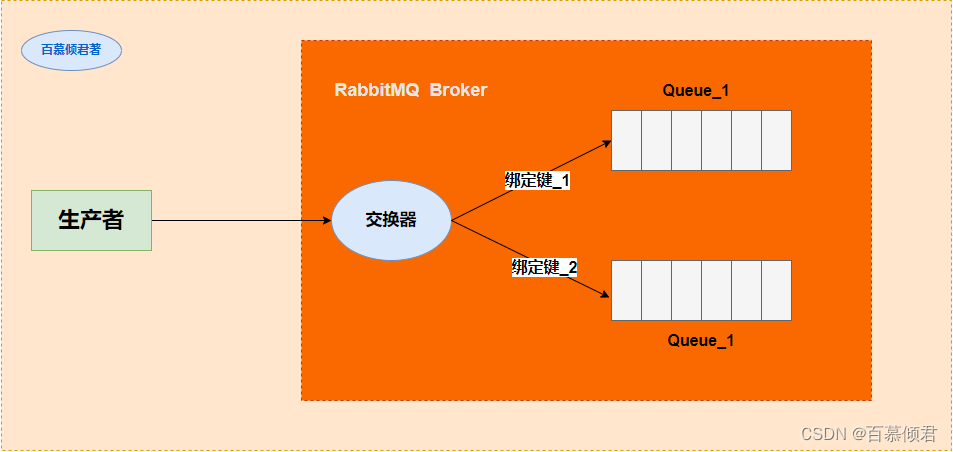
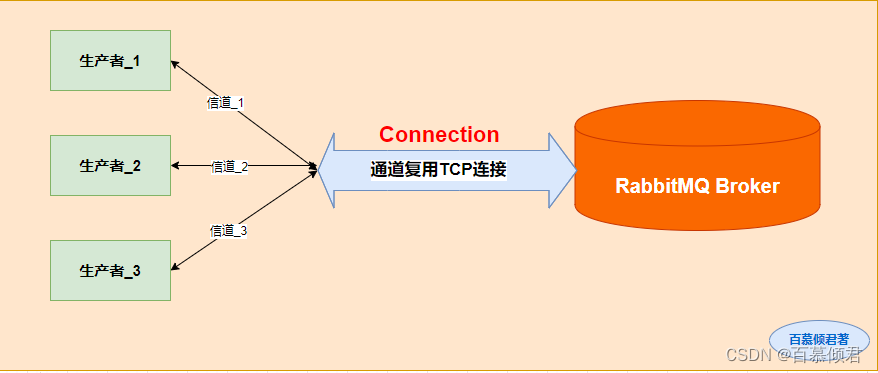
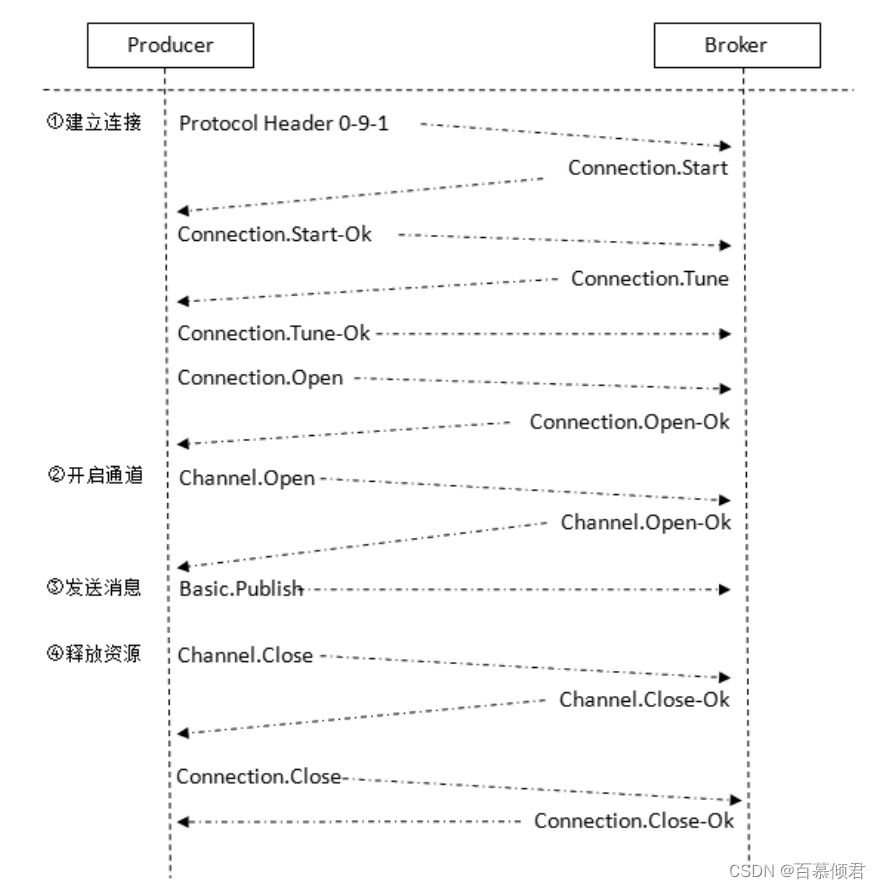
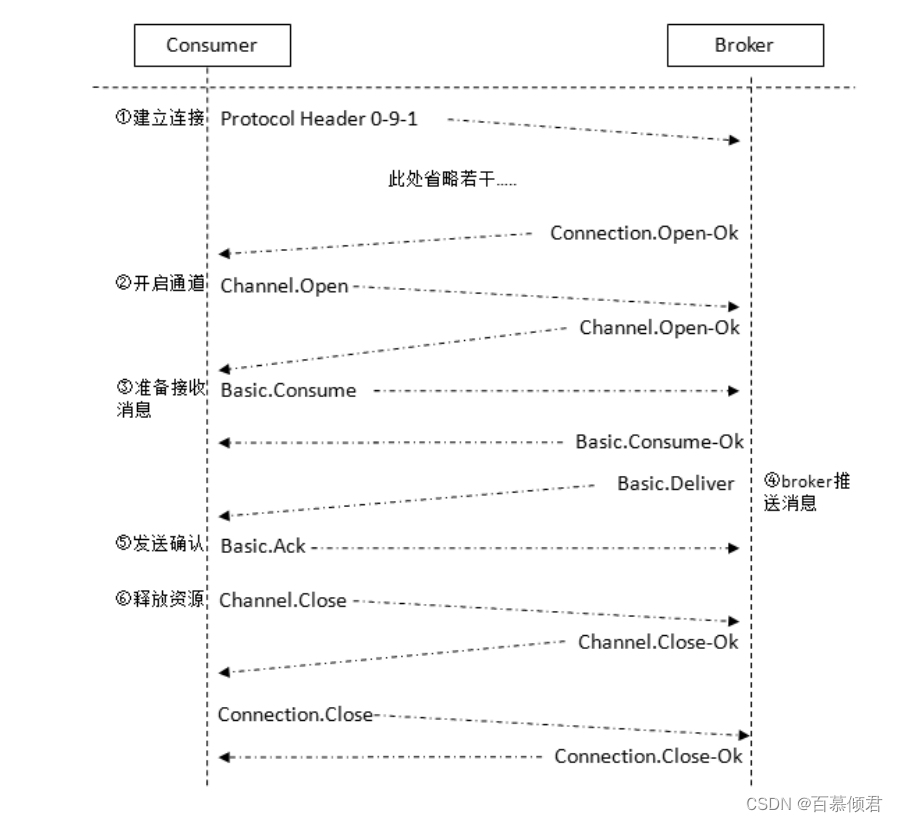
1985年,开始用于金融交易。发布订阅模式,用软件总线来处理各种不同类型的信息,只需要一个终端来接入软件总线,那么就可以订阅想要的消息了。同时诞生了第一个消息队列软件TIB(The Information Bus)。很快,这种数据传输模式便得到更广泛的应用,并进入了电信、新闻行业。1994年,路透社收购了Teknekron公司。
2001年,JMS诞生。因为那些公司的中间件价格昂贵,一般只应用于大型组织机构,它们需要可靠性、解耦及实时消息通信的功能。由于商业壁垒,商业 MO 供应商想要解决应用互通的问题,而不是去创建标准来实现不同的 MO 产品间的互通,或者允许应用程序更改 MQ 平台。为了打破这个壁垒,使得同一个应用可以消费不同的MQ产品,JMS就这样产生了。
JMS 通过提供公共 Java API 的方式,隐藏单独 MQ 产品供应商提供的实际接口,解决了互通问题。从技术上讲,Java 应用程序只需针对JMS API 编程,选择合适的 MO 驱动即可,JMS 会打理好其他部分。ActiveMO 就是JMS的一种实现。不过尝试使用单独标准化接口来胶合众多不同的接口,最终会暴露出问题,使得应用程序变得更加脆弱。所以急需一种新的消息通信标准化方案。