简介
梯度提升决策树(GBDT)由于准确率高、训练快速等优点,被广泛应用到分类、回归合排序问题中。该算法是一种additive树模型,每棵树学习之前additive树模型的残差。许多研究者相继提出XGBoost、LightGBM等,又进一步提升了GBDT的性能。
基本思想
提升树-Boosting Tree
以决策树为基函数的提升方法称为提升树,其决策树可以是分类树或者回归树。决策树模型可以表示为决策树的加法模型。
f
M
(
x
)
=
∑
m
=
1
M
T
(
x
;
Θ
m
)
f_{M}(x)=\sum_{m=1}^{M} T\left(x ; \Theta_{m}\right)
fM(x)=m=1∑MT(x;Θm)
其中,
T
(
x
;
θ
m
)
T\left(x ; \theta_{m}\right)
T(x;θm) 表示决策树,
θ
m
\theta_{m}
θm表示树的参数,
M
M
M为树的个数。
针对不同问题的提升树算法主要区别在于损失函数的不同。对于回归问题,使用的是平方损失函数;对于分类问题,使用的是指数损失函数;对二分类问题,提升树算法只需将AdaBoost的基分类器设置为二分类树即可,此时的提升树算法是AdaBoost算法的一个特例。以下主要关注回归问题的提升树算法。
对于回归问题的提升树算法,每一步拟合的是前一步的残差,具体为什么拟合的是残差看下面推导:
L
(
y
,
f
m
(
x
)
)
=
L
(
y
,
f
m
−
1
(
x
)
+
T
(
x
;
θ
m
)
)
=
[
y
−
f
m
−
1
(
x
)
−
T
(
x
;
θ
m
)
]
2
=
[
r
−
T
(
x
;
θ
m
)
]
2
\begin{aligned} L\left(y, f_{m}(x)\right) &=L\left(y, f_{m-1}(x)+T\left(x ; \theta_{m}\right)\right) \\=[y&-f_{m-1}(x)-T\left(x ; \theta_{m}\right) ]^{2} \\ &=\left[r-T\left(x ; \theta_{m}\right)\right]^{2} \end{aligned}
L(y,fm(x))=[y=L(y,fm−1(x)+T(x;θm))−fm−1(x)−T(x;θm)]2=[r−T(x;θm)]2
其中
r
r
r 代表残差。
回归问题中的提升树算法如下:
输入:训练数据集
T
=
{
(
x
1
,
y
1
)
,
(
x
2
,
y
2
)
,
…
.
,
(
x
N
,
y
N
)
}
T=\left\{\left(x_{1}, y_{1}\right),\left(x_{2}, y_{2}\right), \ldots .,\left(x_{N}, y_{N}\right)\right\}
T={(x1,y1),(x2,y2),….,(xN,yN)} 其中$x_{i} \in X \subseteq R^{n}
,
,
, y_{i} \in \gamma={-1,+1}$
输出:提升树
f
M
(
x
)
f_{M}(x)
fM(x)
-
初始化
f
0
(
x
)
=
0
f_{0}(x)=0
f0(x)=0
-
对
m
=
1
,
2
⋯
M
m=1,2 \cdots \mathrm{M}
m=1,2⋯M
- 计算每个数据的残差:
r
m
i
=
y
i
−
f
m
−
1
(
x
i
)
,
i
=
1
,
2
,
…
.
N
r_{m i}=y_{i}-f_{m-1}\left(x_{i}\right), i=1,2, \ldots . N
rmi=yi−fm−1(xi),i=1,2,….N
- 拟合残差学习一颗回归树,得到
T
(
x
;
θ
m
)
T\left(x ; \theta_{m}\right)
T(x;θm)
- 更新
T
(
x
;
θ
m
)
T\left(x ; \theta_{m}\right)
T(x;θm)
-
得到回归问题提升树
f
M
(
x
)
=
∑
m
=
1
M
T
(
x
;
θ
m
)
f_{M}(x)=\sum_{m=1}^{M} T\left(x ; \theta_{m}\right)
fM(x)=m=1∑MT(x;θm)
得到一颗提升树后,可以对输入数据进行预测。假设得到两棵树,下图给出预测过程:
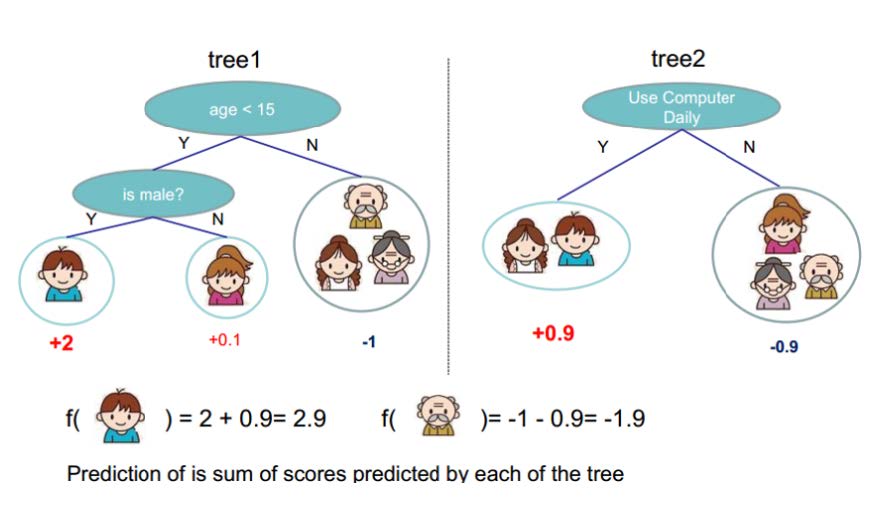
梯度提升-Gradient Boosting
梯度提升的思想借鉴与梯度下降法,回顾梯度下降法,对于优化问题:
min
f
(
w
)
\min f(w)
minf(w)
使用梯度下降法求解的基本步骤:
- 随机选择一个初始点
w
0
w_0
w0
- 重复以下过程:
- 求负梯度:
g
i
=
−
∂
∂
w
f
(
w
)
∣
w
i
g_{i}=-\frac{\partial}{\partial w} f\left.(w)\right|_{w_{i}}
gi=−∂w∂f(w)∣wi
- 选择步长
α
\alpha
α
- 更新参数:
w
i
+
1
=
w
i
+
α
∗
g
i
w_{i+1}=w_{i}+\alpha * g_{i}
wi+1=wi+α∗gi
- 直到满足终止条件
由以上过程可以看出,对于最终的最优解
w
∗
w^{*}
w∗,是由初始值
w
0
w_0
w0 经过M次迭代后得到的。设
w
0
=
d
0
w_0 = d_0
w0=d0,则
w
∗
w^{*}
w∗ 为:
w
∗
=
∑
i
=
0
M
α
i
∗
g
i
w^{*}=\sum_{i=0}^{M} \alpha_{i} * g_{i}
w∗=i=0∑Mαi∗gi
在函数空间中,我们也可以借鉴梯度下降的思想,进行最优函数的搜索。关键是利用损失函数的负梯度在当前模型的值
−
[
∂
L
(
y
,
F
(
X
)
)
∂
F
(
X
)
]
F
(
X
)
=
F
m
−
1
(
X
)
-\left[\frac{\partial L(y, F(X))}{\partial F(X)}\right]_{F(X)=F_{m-1}(X)}
−[∂F(X)∂L(y,F(X))]F(X)=Fm−1(X)
作为回归问题提升树算法中的残差的近似值,拟合一个回归树。
对于模型的损失函数
L
(
y
,
F
(
X
)
)
L(y, F(X))
L(y,F(X)),为了能够求解出最优的函数
F
∗
(
X
)
F^{*}(X)
F∗(X),首先设置初始值为:
F
0
(
X
)
=
f
0
(
x
)
F_{0}(X)=f_{0}(x)
F0(X)=f0(x)
以函数
F
(
X
)
F(X)
F(X) 为一个整体,与梯度下降法的更新过程一致,假设经过M代,得到最优的函数
F
∗
(
X
)
F^{*}(X)
F∗(X)为:
F
∗
(
X
)
=
∑
i
=
0
M
f
i
(
x
)
F^{*}(X)=\sum_{i=0}^{M} f_{i}(x)
F∗(X)=i=0∑Mfi(x)
其中
f
i
(
x
)
f_{i}(x)
fi(x) 为:
f
i
(
x
)
=
−
α
i
g
i
(
X
)
=
−
α
i
∗
[
∂
L
(
y
,
F
(
X
)
)
∂
F
(
X
)
]
F
(
X
)
=
F
m
−
1
(
X
)
f_{i}(x)=-\alpha_{i} g_{i}(X)=-\alpha_{i} *\left[\frac{\partial L(y, F(X))}{\partial F(X)}\right]_{F(X)=F_{m-1}(X)}
fi(x)=−αigi(X)=−αi∗[∂F(X)∂L(y,F(X))]F(X)=Fm−1(X)
可以看到这里梯度变量是一个函数,是在函数空间上求解;而以往的梯度下降是在N维的参数空间负梯度方向,变量是参数。在梯度提升中,这里变量是函数,通过当前函数的负梯度方向更新函数以修正模型,最后累加的模型近似最优函数。
GBDT的负梯度为什么近似于提升树的残差
对于损失函数
L
(
y
,
f
m
−
1
+
T
(
x
i
;
Θ
m
)
)
L\left(y, f_{m-1}+T\left(x_{i} ; \Theta_{m}\right)\right)
L(y,fm−1+T(xi;Θm)) ,我们将
f
(
x
)
f(x)
f(x) 而不是
θ
\theta
θ 作为自变量。根据梯度下降定义,可以得到损失函数参数的更新公式:
f
m
=
f
m
−
1
−
∂
L
∂
f
f_{m}=f_{m-1}-\frac{\partial L}{\partial f}
fm=fm−1−∂f∂L
同时提升树的定义为:
f
m
=
f
m
−
1
+
T
(
x
i
;
Θ
m
)
f_{m}=f_{m-1}+T\left(x_{i} ; \Theta_{m}\right)
fm=fm−1+T(xi;Θm),决策树拟合的值等于负梯度,为残差。
梯度提升决策树-GBDT
了解了GBDT的两个部分(提升树和梯度提升)后,我们以回归树为例,基模型为CART回归树,得到GBDT的实现思路如下
输入:训练数据集
T
=
{
(
x
1
,
y
1
)
,
(
x
2
,
y
2
)
,
…
.
,
(
x
N
,
y
N
)
}
T=\left\{\left(x_{1}, y_{1}\right),\left(x_{2}, y_{2}\right), \ldots .,\left(x_{N}, y_{N}\right)\right\}
T={(x1,y1),(x2,y2),….,(xN,yN)},其中其中$x_{i} \in X \subseteq R^{n}
,
,
, y_{i} \in \gamma={-1,+1}$
输出:提升树
f
M
(
x
)
f_{M}(x)
fM(x)
-
初始化
f
0
(
x
)
=
argmin
∑
i
=
1
N
L
(
y
i
,
c
)
f_{0}(x)=\operatorname{argmin} \sum_{i=1}^{N} L\left(y_{i}, c\right)
f0(x)=argmin∑i=1NL(yi,c)
-
对
m
=
1
,
2
⋯
M
\mathrm{m}=1,2 \cdots \mathrm{M}
m=1,2⋯M
-
计算每个数据:
r
m
i
=
[
∂
L
(
y
,
f
(
x
i
)
)
∂
f
(
x
i
)
]
f
(
x
)
=
f
m
−
1
(
x
)
r_{m i}=\left[\frac{\partial L\left(y, f\left(x_{i}\right)\right)}{\partial f\left(x_{i}\right)}\right]_{f(x)=f_{m-1}(x)}
rmi=[∂f(xi)∂L(y,f(xi))]f(x)=fm−1(x)
-
拟合
r
m
i
r_{m i}
rmi学习一棵回归树,得到
T
(
x
;
θ
m
)
T\left(x ; \theta_{m}\right)
T(x;θm)。更详细一点,得到第
m
m
m棵树的叶节点区域
R
m
j
,
j
=
1
,
2
…
J
R_{m j}, j=1,2 \dots J
Rmj,j=1,2…J,即一颗由
J
J
J 个叶子结点组成的树
-
计算每个区域的最优输出:
c
m
j
=
argmin
(
∑
x
i
∈
R
m
j
L
(
y
i
,
f
m
−
1
(
x
i
)
+
c
)
c_{m j}=\operatorname{argmin}(\sum_{x_{i} \in R_{m j}} L\left(y_{i}, f_{m-1}\left(x_{i}\right)+c\right)
cmj=argmin(xi∈Rmj∑L(yi,fm−1(xi)+c)
-
更新
f
m
(
x
)
=
f
m
−
1
(
x
)
+
∑
j
=
1
J
c
m
j
I
(
x
i
ϵ
R
m
)
f_{m}(x)=f_{m-1}(x)+\sum_{j=1}^{J} c_{m j} I\left(x_{i} \epsilon R_{m}\right)
fm(x)=fm−1(x)+j=1∑JcmjI(xiϵRm)
-
得到回归问题梯度提升树
f
M
(
x
)
=
∑
m
=
1
M
f
m
(
x
)
=
∑
m
=
1
M
∑
j
=
1
J
c
m
j
I
(
x
i
ϵ
R
m
j
)
f_{M}(x)=\sum_{m=1}^{M} f_{m}(x)=\sum_{m=1}^{M} \sum_{j=1}^{J} c_{m j} I\left(x_{i} \epsilon R_{m j}\right)
fM(x)=m=1∑Mfm(x)=m=1∑Mj=1∑JcmjI(xiϵRmj)
算法步骤1得到使损失函数最小的常数估计值,是一个只有根节点的树。在步骤2a计算损失函数的负梯度在当前模型的值,作为残差估计。在步骤2b估计回归树的叶节点区域,来拟合残差的近似值。第2c步利用线性搜索估计叶节点区域的值,使损失函数极小化。第2d步更新回归树。第3步得到输出的最终模型。
优点
- 预测阶段的计算速度快,树与树之间可并行化计算
- 在分布稠密的数据集上,泛化能力和表达能力都很好
- 采用决策树作为弱分类器使GBDT具有较好的解释性和鲁棒性,能够自动发现特征间的高阶关系,并且也不需要对数据进行特殊的处理如归一化等
缺点
- GBDT在高维稀疏的数据集上,表现不如SVM或者神经网络
- GBDT在处理文本分类特征问题上,不如处理数值特征
- 训练过程需要串行训练,只能在决策树内部采用一些局部并行的手段提高训练速度
实现
GBDT的python源码实现
常见问题
两者都是在每一轮迭代中,利用损失函数相对于模型的负梯度方向的信息来对当前模型进行更新,只不过在梯度下降中,模型是以参数化的形式表示,从而模型的更新等价于参数的更新。
而在梯度提升中,模型并不需要参数化表示,而是直接定义在函数空间中,从而大大扩展了可以使用的模型种类。
Bagging通过模型集成降低方差,提高弱分类器的性能。
Boosting通过模型集成降低偏差,提高弱分类器的性能。
|
Bagging |
Boosting |
| 降低 |
方差 |
偏差 |
| 训练 |
各个弱分类器可独立训练 |
弱分类器需要依次生成 |
|
|
|
|
|
|
用每个样本的残差训练下一棵树,直到残差收敛到某个阈值以下,或者树的总数达到某个上限为止。
A. 计算每个样本的负梯度
B. 分裂挑选最佳特征及其分割点时,对特征计算相应的误差及均值时
C. 更新每个样本的负梯度时
D. 最后预测过程中,每个样本将之前的所有树的结果累加的时候
优点
(1)预测阶段计算速度块,树与树之间可并行化计算
(2)在分布稠密的数据集上,泛化能力和表达能力都很好
(3)采用决策树作为弱分类器使得GBDT模型具有较好的可解释性和鲁棒性,能够自动发现特征间的高阶关系,并且不需要对数据进行特殊的预处理如归一化等
缺点
(1)GBDT在高维稀疏的数据集上,表现不如支持向量机或者神经网络
(2)GBDT在处理文本分类特征问题上,优势不如在处理数值特征时明显
(3)训练过程需要串行训练,只能在决策树内容采用一些局部并行手段提高训练速度
基于残差的GDBT对异常值敏感。对于回归类的问题,如果采用平方损失函数。当出现异常值时,后续模型会对异常值关注过多。我们来看一个例子:
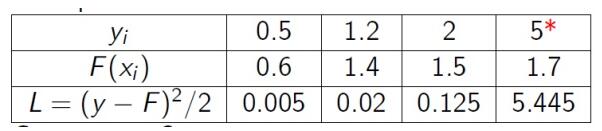
很明显后续的模型会对第4个值关注过多,这不是一种好的现象,所以一般回归类的损失函数会用绝对损失或者huber损失函数来代替平方损失函数:

参考资料
- 李航《统计学习方法》
- GBDT算法原理深入解析
- 机器学习-一文理解GBDT的原理-20171001
- http://www.ccs.neu.edu/home/vip/teach/MLcourse/4_boosting/slides/gradient_boosting.pdf
- GBDT的python源码实现