最近做研究碰到了一个难题,需要对程序变量按生命期进行重命名。考虑到 SSA 中一个变量在不同的程序分支中赋值时会进行重命名,因此打算以此作为参考,看看能否采取同样的方法达到目的。由于之前看到的文档中都说 LLVM IR 是 SSA 形式的,然而在用 Clang 打印生成 LLVM IR 后发现它并不是 SSA 形式,百思不得其解。本篇文章是查阅资料后对此问题的解答,顺便介绍了 LLVM SSA 的相关知识。
SSA 介绍
1 概念
首先看一下维基对静态单一赋值(SSA)形式的定义:
In compiler design, static single assignment form (often abbreviated as SSA form or simply SSA) is a property of an intermediate representation (IR), which requires that each variable is assigned exactly once, and every variable is defined before it is used.
– From Wikipedia
从上面的描述可以看出,SSA 形式的 IR 主要特征是每个变量只赋值一次。相比而言,非 SSA 形式的 IR 里一个变量可以赋值多次。为了得到 SSA 形式的 IR,起初的 IR 中的变量会被分割成不同的版本(version),每个定义(definition:静态分析术语,可以理解为赋值)对应着一个版本。在教科书中,通常会在旧的变量名后加上下标构成新的变量名,这也就是各个版本的名字。显然,在 SSA 形式中,UD 链(Use-Define Chain)是十分明确的。也就是说,变量的每一个使用(use:静态分析术语,可以理解为变量的读取)点只有唯一一个定义可以到达。
注释:关于 UD 链的详细解释,可以参考维基给出的说明 Use-define chain 。在这里我们只需要知道,编译器在做常量传播、公共子表达式删除等优化之前,必须获取程序的 UD 链和 DU 链。显然,UD 链越简洁,越方便做编译优化。
2 为什么要使用 SSA ?
SSA 通过简化程序中变量的特性,可以同时达到两种目的:第一,可以简化很多编译优化方法的过程;第二,对很多编译优化方法来说,可以获得更好的优化结果。下面给出一个例子:
y := 1
y := 2
x := y
显然,我们一眼就可以看出,上述代码第一行的赋值行为是多余的,第三行使用的 y 值来自于第二行中的赋值。对于采用非 SSA 形式 IR 的编译器来说,它需要做数据流分析(具体来说是到达-定义分析)来确定选取哪一行的 y 值。但是对于 SSA 形式来说,就不存在这个问题了。如下所示:
y1 := 1
y2 := 2
x1 := y2
显然,我们不需要做数据流分析就可以知道第三行中使用的 y 来自于第二行的定义,这个例子很好地说明了 SSA 的优势。除此之外,还有许多其他的优化算法在采用 SSA 形式之后优化效果得到了极大提高。甚至,有部分优化算法只能在 SSA 上做。
3 如何生成 SSA ?
把程序转换为 SSA 形式,最简单的方法就是将每个被赋值的变量用一个新的变量(版本)来取代,同时将每次使用的变量替换为这个变量到达该程序点的“版本”。以下面左边的流图为例,右边的流图则是按照这个方法生成的 SSA:
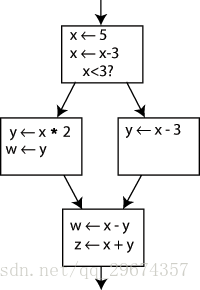
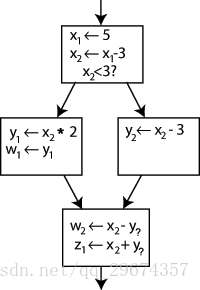
图一 原程序流图 图二 SSA 形式的程序
眼尖的人可以发现,右边的图其实也不是最后的 SSA 形式,它最下面的基本块里 y 的使用尚未确定。由于该基本块的多个前驱基本块里都对 y 进行了定义,这里我们并不知道程序最终会从哪个前驱基本块到达该基本块。那么,我们如何知道 y 该取哪个版本?这时候 Φ(Phi) 函数便出场了。
我们在最后一个基本块的起始处添加了一条新的语句(Φ),它给出了 y 的一个新的定义 y3,根据程序的运行路径选择对应的版本。最后得出的 SSA 如下图所示:
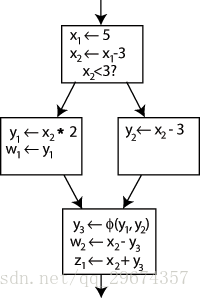
图三 最终的 SSA
要注意的是,Φ 函数并不是一条实际的指令,现在的 target 指令集大多都不支持这样的指令,因此需要编译器做特殊处理。编译器后端在碰到 Φ 函数时,会进行相关处理得到正确的汇编代码,这个过程叫做 resolution。知乎有一个帖子专门介绍了 Phi 的处理方式,可以戳这里:Phi Node 是如何实现它的功能的?
4 如何插入 Φ 函数 ?
根据上面的了解,我们可以知道实现 SSA 的一个关键点是 Φ 函数。自然而然的,我们需要回答下述问题:给出任意一个控制流图,在哪里插入 Φ 函数?哪些变量需要 Φ 函数来进行选择?这些问题很难,但是迄今已经有了一个高效的解决方案。该方法的计算涉及到我们下面要介绍的一个概念:支配边界。
4.1 求解支配边界
在介绍支配边界之前,简单回顾一下支配点(dominator)的概念,这个概念在另一篇博客上有介绍(控制流分析之循环)。在控制流图中,我们称结点 A 严格支配(strictly dominate)结点 B 当且仅当结点 A 与 B 并非同一结点,并且到达结点 B 的所有路径都包含结点 A。简单说,在到达结点 B 的时候,结点 A 中的代码都跑了一遍。要注意的是,概念严格支配和概念支配的区别在于俩结点是否同一节点。如果结点 A 与结点 B 可以是同一结点,那么称结点 A 支配(dominate)结点 B。换句话说,一个结点一定支配它本身。
现在可以提出支配边界(dominance frontiers)的概念了:如果结点 A 并不严格支配结点 B,而是支配结点 B 的立即前驱,那么结点 B 就在结点 A 的支配边界中。要特别注意以下情况,即当结点 A 不严格支配结点 B 且结点 A 就是结点 B 的立即前驱时,由于所有结点都支配它本身,于是结点 A 也支配它本身,这种情况下结点 B 也在结点 A 的支配边界里。从结点 A 的角度来看,可以把支配边界理解为结点 A 的支配关系终止的地方,也就是会有其他控制流出现的地方。
显然,通过支配边界可以准确获取到 Φ 函数应当出现的地方。如果结点 A 定义了某个变量,那么这个变量会到达被结点 A 支配的每一个结点。我们只有抛开这些结点,考虑支配边界,才会发现有其他的控制流可能对同样的变量进行了定义。下面介绍一个计算支配边界的主流算法,它是由 Cooper 等人在论文《A Simple, Fast Dominance Algorithm》中提出:
1 for each node b
2 if the number of immediate predecessors of b ≥ 2
3 for each p in immediate predecessors of b
4 runner := p
5 while runner ≠ idom(b)
6 add b to runner’s dominance frontier set
7 runner := idom(runner)
注意 1:上述算法中出现的 idom(b) 即立即支配(immediate dominate)结点 b 的结点。顾名思义,结点 b 的立即支配结点是指在支配树(dominator tree)中结点 b 的父亲,也就是离结点 b 最近的支配结点。对于非 entry 结点来说,这样的结点有且只有一个。
注意 2:对于只有一个立即前驱的结点来说,这个前驱也一定是它的立即支配结点。因此,上述算法第五行的循环条件恒不成立,没有必要考虑这种情况。
4.2 Φ 函数插入算法
在求出了支配边界后,后面的工作就简单很多了。接着,我们需要利用上一节求出的支配边界,求解需要使用 Φ 函数的基本块。下面给出一个插入算法的例子,该算法在所有支配边界的结点中插入了 Φ 函数:
// has-phi(B) is true if a φ-function has already been placed in B
// processed(B) is true if B has already been processed once for variable v
// Assignment-nodes(v) is the set of nodes containing statements assigning to v
// W is the work list (i.e., queue)
function Place-phi-function(v)
for all nodes B in the flow graph do
has-phi(B) = false;
processed(B) = false;
end for
W = ∅;
for all nodes B ∈ Assignment-nodes(v) do
processed(B) = true;
Add(W, B);
end for
while W != ∅ do
begin
B = Remove(W);
for all nodes y ∈ DF(B) do
if (not has-phi(y)) then
begin
place < v = φ(v, v, ..., v) > in y;
has-phi(y) = true;
if (not processed(y)) then
begin
processed(y) = true;
Add(W, y);
end
end
end for
end
end
显然,此算法并没有考虑到去除冗余的 Φ 函数,得出的 SSA 肯定不是精简 SSA。我们在这里列出此算法,只是为了说明如何使用支配边界分配 Φ 函数。此外,要说明的是,流图的 entry 结点中声明的每个变量(一个函数的所有局部变量都在 entry 里声明,可以参考 LLVM)都需要执行一次此算法。因此,本过程结束后,流图中部分基本块都插入了相应变量的 Φ 函数。现在,只需要进行最后一步工作了,也就是对程序变量进行重命名。
4.3 重命名算法
在开始介绍算法前,要特别指出这里的重命名是指把程序中某个变量分割成不同的版本号。只要算法碰到了一次变量定义,就会进行一次重命名。SSA 形式需要满足一种支配关系:变量的定义支配每一次使用,并且如果使用存在于 Φ 函数中,定义是该使用的前驱。因此,我们需要从上往下遍历支配树,按照深度优先序在每个基本块上迭代。下面提出重命名算法:
begin // calling program
for all variables x in the flow graph do
V = ∅;
v = 1;
push 0 onto V;
Rename-variables(x, Start);
end for
end
function Rename-variables(x, B) // x is a variable and B is a block
begin
ve = Top(V); // V is the version stack of x
for all statements s ∈ B do
if s is a non-φ statement then
replace all uses of x in the RHS(s) with Top(V);
if s defines x then
begin
replace x with xv in its definition;
push xv onto V; // xv is the renamed version of x in this definition
v = v + 1; // v is the version number counter
end
end for
for all successors s of B in the flow graph do
j = predecessor index of B with respect to s
for all φ-functions f in s which define x do
replace the jth operand of f with Top(V);
end for
end for
for all children c of B in the dominator tree do // Depth-First Order
Rename-variables(x, c);
end for
repeat Pop(V);
until (Top(V) == ve);
end
重命名过程完成后,SSA 形式的代码便构造完成了。上述过程比较难以理解,最好是结合实例分析代码。这里提供一个文档 SSA Form: Construction and Application to Program Optimizations,可以按照上面的例子结合上面的算法进行研究。至此,之前的几个问题都已回答完毕!
5 精简 SSA
我们上面的方法求出的 SSA 叫做最小化 SSA(minimal SSA),它在保证每个变量名只分配一次值的前提下插入最少的 Φ 函数。然而,这些 Φ 函数中有一部分可能已经死亡了。因此,最小化 SSA 其实并不需要这类 Φ 函数,冗余的 Φ 函数会导致分析过程更加低效。所以,我们提出了精简 SSA(pruned SSA)形式,LLVM SSA 便是一种精简 SSA。
精简 SSA 形式的提出基于以下观察:只有变量在 Φ 函数插入点后仍然活跃,我们才需要 Φ 函数。“活跃”就是说,该变量在 Φ 函数后的路径里仍被使用。如果一个变量并不活跃,Φ 函数的结果不会使用,Φ 函数产生的赋值也就死亡了。精简 SSA 形式的构造需要使用 Φ 函数插入点后的活跃变量信息。如果在插入之后原来的变量并不活跃,就不需要插入 Φ 函数。
我们可以看出,精简化的过程其实就是一个死代码删除问题。当程序里所有变量的使用被 Φ 函数替代,或者当一个 Φ 函数被用作另外一个 Φ 函数的参数时,它才是活跃的。具体来讲,在进入 SSA 形式后,每一次变量的使用都会被重写为支配它的最近一次定义。只要 Φ 函数的定义至少支配了一个使用,或者至少是一个活跃 Φ 函数的参数,这个 Φ 函数就是活跃的。
当然,还有其他形式的 SSA,例如半精简 SSA。这种 SSA 的提出针对的是活跃变量分析开销过大的问题,同时也能达到减少 Φ 函数的目的。
LLVM 里的 SSA
在了解了 SSA 的理论知识后,我们可以开始着手讨论 LLVM SSA。回想文章开头的问题,为什么由 Clang 生成的 IR 并不是 SSA 形式?难道在 LLVM 里,IR 并非 SSA 形式吗?其实不是这样的,我们下面开始具体介绍。
1 LLVM IR
这是一个很容易被误解的点,就是 LLVM IR 具体是指什么?我们知道,LLVM 在程序编译过程中会出现各种各样的 IR。例如,有前端的 AST 表示;有 Function 和 Instruction 类表示的 target 无关 IR;还有 MachineFunction 和 MachineInstr 表示的 target 相关 IR(又叫做 MIR)。这些表示方法都可以称作 IR,这样很容易造成混乱。一般来说,我们把 Function 和 Instruction 类表示的 IR 才称作 LLVM IR,LLVM 的官方文档也是如此处理。
在 LLVM 的代码表示里,主要使用了三种不同的格式:1. 内存内(in-memory)表示的编译器 IR,也就是用Function 和 Instruction 类表示的 LLVM IR;2. 磁盘上(on-disk)表示的 bitcode,这种方式适用于 JIT 编译器的快速加载;3. 便于人类阅读的汇编语言表示,叫做 LLVM assembly language,即 Clang 产生的 .ll 文件。这三种不同的表示是等价的,可以互相转换。其中,1->3 的转换由 AsmWriter.cpp 完成;3->1 的转换由 LLParser.cpp 完成。
下面,来看一个 .ll 文件的例子。首先,列出 C 程序源码:
int foo(int a, int b, int e) {
int c, d;
goto L1;
L1: {
c = a + b;
d = c - a;
if (d) goto L2;
d = b * d;
e = e + 1;
}
L2: {
b = a + b;
e = c - a;
if (e) goto L1;
a = b * d;
b = a - d;
}
return b;
}
使用命令“clang -S -emit-llvm test.c -o test.ll”生成的 .ll 文件如下:
; ModuleID = '.\test.c'
target datalayout = "e-m:x-p:32:32-i64:64-f80:32-n8:16:32-a:0:32-S32"
target triple = "i686-pc-windows-msvc18.0.0"
; Function Attrs: nounwind
define i32 @foo(i32 %a, i32 %b, i32 %e) #0 {
entry:
%e.addr = alloca i32, align 4
%b.addr = alloca i32, align 4
%a.addr = alloca i32, align 4
%c = alloca i32, align 4
%d = alloca i32, align 4
store i32 %e, i32* %e.addr, align 4
store i32 %b, i32* %b.addr, align 4
store i32 %a, i32* %a.addr, align 4
br label %L1
L1: ; preds = %if.then5, %entry
%0 = load i32, i32* %a.addr, align 4
%1 = load i32, i32* %b.addr, align 4
%add = add nsw i32 %0, %1
store i32 %add, i32* %c, align 4
%2 = load i32, i32* %c, align 4
%3 = load i32, i32* %a.addr, align 4
%sub = sub nsw i32 %2, %3
store i32 %sub, i32* %d, align 4
%4 = load i32, i32* %d, align 4
%tobool = icmp ne i32 %4, 0
br i1 %tobool, label %if.then, label %if.end
if.then: ; preds = %L1
br label %L2
if.end: ; preds = %L1
%5 = load i32, i32* %b.addr, align 4
%6 = load i32, i32* %d, align 4
%mul = mul nsw i32 %5, %6
store i32 %mul, i32* %d, align 4
%7 = load i32, i32* %e.addr, align 4
%add1 = add nsw i32 %7, 1
store i32 %add1, i32* %e.addr, align 4
br label %L2
L2: ; preds = %if.end, %if.then
%8 = load i32, i32* %a.addr, align 4
%9 = load i32, i32* %b.addr, align 4
%add2 = add nsw i32 %8, %9
store i32 %add2, i32* %b.addr, align 4
%10 = load i32, i32* %c, align 4
%11 = load i32, i32* %a.addr, align 4
%sub3 = sub nsw i32 %10, %11
store i32 %sub3, i32* %e.addr, align 4
%12 = load i32, i32* %e.addr, align 4
%tobool4 = icmp ne i32 %12, 0
br i1 %tobool4, label %if.then5, label %if.end6
if.then5: ; preds = %L2
br label %L1
if.end6: ; preds = %L2
%13 = load i32, i32* %b.addr, align 4
%14 = load i32, i32* %d, align 4
%mul7 = mul nsw i32 %13, %14
store i32 %mul7, i32* %a.addr, align 4
%15 = load i32, i32* %a.addr, align 4
%16 = load i32, i32* %d, align 4
%sub8 = sub nsw i32 %15, %16
store i32 %sub8, i32* %b.addr, align 4
%17 = load i32, i32* %b.addr, align 4
ret i32 %17
}
attributes #0 = { nounwind "disable-tail-calls"="false" "less-precise-fpmad"="false" "no-frame-pointer-elim"="true" "no-frame-pointer-elim-non-leaf" "no-infs-fp-math"="false" "no-nans-fp-math"="false" "stack-protector-buffer-size"="8" "target-cpu"="pentium4" "target-features"="+fxsr,+mmx,+sse,+sse2" "unsafe-fp-math"="false" "use-soft-float"="false" }
!llvm.ident = !{!0}
!0 = !{!"clang version 3.8.0 (tags/RELEASE_380/final)"}
不难看出,此 .ll 文件所展示的 IR 并非完全的 SSA 形式,这也是我的疑惑所在。相反,这里采取的是 alloca/load/store 的方法,把所有局部变量通过“alloca”指令进行分配。为什么要这样做呢?在第一部分,我们介绍了构造 SSA 的基本过程。不难发现,构造 SSA 的算法不能算快,而且需要各种复杂的数据结构,这些因素导致前端在生成 SSA 形式的 IR 时十分笨拙。因此,LLVM 采用了一个“小技巧(trick)”,可以把构造 SSA 的工作从前端分离出来。要说明的是,这个 trick 是 LLVM 所特有的:
LLVM does require all register values to be in SSA form, it does not require (or permit) memory objects to be in SSA form.
2 LLVM 的内存
基于上述的 trick,前端可以直接把函数里的变量按照栈的方式分配到内存当中。并且,这个放在内存里的变量不需要遵循SSA形式,可以经受多次定义,从而避免了构造 phi 函数产生的大量开销。接下来,我们有必要介绍一下 LLVM 里如何表示这种栈上的变量。
在 LLVM 里,所有的内存访问都要显式地调用 load/store 指令。要说明的是,LLVM 并没有给出“取地址”的操作符。以上面源程序里的变量 c 为例:
...
entry:
%c = alloca i32, align 4
...
L1:
store i32 %add, i32* %c, align 4
...
L2:
%10 = load i32, i32* %c, align 4
...
变量 c 通过 LLVM Alloca Instr 声明,分配了 i32 大小的空间。这里的 %c 类型为 i32*,也就是说,%c 代表的是这段空间的地址。alloca 分配的栈变量可以进行任何操作,比如上述的 %c 就可以被多次赋值。因此,通过 alloca 技术我们避免了 PHI 结点的使用。总结一下,这种可以避免产生 PHI 结点的方法分为四个步骤:
1. Each mutable variable becomes a stack allocation.
2. Each read of the variable becomes a load from the stack.
3. Each update of the variable becomes a store to the stack.
4. Taking the address of a variable just uses the stack address directly.
不难发现,这种方法虽然可以避免 PHI 结点的出现,却也引入了另外一个问题:由于每一次变量存取都需要访问内存,这导致了严重的性能问题。于是,LLVM 提供了一个叫做“mem2reg”的重要 pass 来处理该问题,这个 pass 可以把上述使用了 alloca 技术的 IR 转化成 SSA 形式。具体来说,它会把 alloca 指令分配的栈变量转化成 SSA 寄存器,并且在合适的地方插入 PHI 结点。这里要指出的是,mem2reg pass 的工作工程并非完全按照我们上面介绍的算法走的,它把支配边界的计算过程和 Φ 函数的插入过程放在一起实现,并且重命名算法也有一定的区别。
目前,LLVM 官方大力支持使用上述“alloca + mem2reg”技术,这点可以从 Clang 默认生成的 IR 是基于栈分配的方式中看出来(默认不开优化)。alloca 技术可以把前端从繁琐的 SSA 构造工作中解脱出来,而 mem2reg 则可以极其快速地生成 SSA 形式。这两者的结合大大提高了编译的效率。
3 问题总结
在使用命令“clang -S -emit-llvm test.c -o test.ll”时,Clang 默认不会开启优化(O0)。由第一部分可以知道,SSA 提出的主要原因是方便做优化。因此,在 O0 下,Clang 不做优化,也没有必要生成完全的 SSA 形式。注意,这里我用了“完全的 SSA 形式”这样的说法,主要是为了区别 O0 条件下的 SSA。在 O0 下,Clang 输出的 IR 是“非完全的SSA形式”。这是因为这种情况下虽然采取了 alloca 技术导致内存上的变量并非单一赋值,但 IR 里的其他符号(指虚拟寄存器)都是单一赋值的。举个例子,假设我们有下面两条语句:
c = a + b;
c = c - b;
假设a, b, c是32位整数,在前端不开优化的情况下会生成如下代码:
%a = alloca i32, align4
%b = alloca i32, align4
%c = alloca i32, align4
%0 = load i32, i32* %a, align 4
%1 = load i32, i32* %b, align 4
%add = add nsw i32 %0, %1
store i32 %add, i32* %c, align 4
%2 = load i32, i32* %c, align 4
%3 = load i32, i32* %b, align 4
%sub = sub nsw i32 %2, %3
store i32 %sub, i32* %c, align 4
可以发现,这个例子里 alloca 指令定义的 %c 经过了多次赋值操作。然而,%add 和 %sub 这两个符号同样是变量 c 的化身,却满足 SSA 形式。可以用上面提到的 trick 总结这种现象,即:LLVM 里,虚拟寄存器是 SSA 形式,而内存则并非 SSA 形式。如果我们给 Clang 加上 O1 等优化,就可以得出想要的 SSA 形式 IR:
; ModuleID = '.\test.c'
target datalayout = "e-m:x-p:32:32-i64:64-f80:32-n8:16:32-a:0:32-S32"
target triple = "i686-pc-windows-msvc18.0.0"
; Function Attrs: norecurse nounwind readnone
define i32 @foo(i32 %a, i32 %b, i32 %e) #0 {
entry:
br label %L1
L1: ; preds = %L1, %entry
%b.addr.0 = phi i32 [ %b, %entry ], [ %add, %L1 ]
%add = add nsw i32 %b.addr.0, %a
%tobool = icmp eq i32 %b.addr.0, 0
br i1 %tobool, label %if.end6, label %L1
if.end6: ; preds = %L1
%mul7 = mul nsw i32 %add, %b.addr.0
%sub8 = sub nsw i32 %mul7, %b.addr.0
ret i32 %sub8
}
attributes #0 = { norecurse nounwind readnone "disable-tail-calls"="false" "less-precise-fpmad"="false" "no-frame-pointer-elim"="false" "no-infs-fp-math"="false" "no-nans-fp-math"="false" "stack-protector-buffer-size"="8" "target-cpu"="pentium4" "target-features"="+fxsr,+mmx,+sse,+sse2" "unsafe-fp-math"="false" "use-soft-float"="false" }
!llvm.ident = !{!0}
!0 = !{!"clang version 3.8.0 (tags/RELEASE_380/final)"}
由本文的分析可以看出,SSA 主要用于机器无关的优化,即 Clang 在前端做的优化。因此,我最开始认为 llc 会调用 mem2reg pass 的想法不成立,实验证明也是如此。llc 主要做的是后端优化,即机器相关的优化,它既可以在 SSA 形式的 IR 上做(前端做了优化),也可以在 alloca 形式的 IR 上做(前端未做优化)。两种情况下的后端优化应该是有区别的,具体差异就等以后慢慢研究了。然而,还有一个问题,就是我不太清楚在 mem2reg pass 把前端默认输出的 IR 转化成 SSA 形式后,如何在该 SSA 上做机器无关优化。想来应该是需要执行一些相关的优化 pass,这个也等以后慢慢研究了。
参考文献
[0] LLVM SSA
[1] Static Single Assignment Form
[2] LLVM Language Reference Manual
[3] LLVM Concepts - llvmpy 0.9.0 documentation
[4] Kaleidoscope: Extending the Languages: Mutable Variables - LLVM 6 documentation
[5] Getting Started With LLVM Core Libraries
[6] SSA Form: Construction and Application to Program Optimizations