MySQL InnoDB相关参数设置
1.InnoDB参数
MySQL目前使用的主要为InnoDB引擎,一些InnoDB引擎参数调整到合理的值将很大程度上改善数据库性能,下面将对一些重要参数做说明。
2.InnoDB参数调整
2.1InnoDB存储结构
2.1.1表空间参数:
innodb_data_file_path:负责定义表空间路径、初始化大小、自动扩展策略等
innodb_file_per_table :用于控制数据存储使用独立表空间
InnoDB存储引擎中所有数据都存储在表空间,表空间分系统表空间和独立表空间,MySQL版本默认使用独立表空间.
表空间存储位置大小受innodb_data_file_path控制,初始大小默认12M,每次以64M自增,建议加大表空间大小为1G,高并发下会受很大影响
默认值:
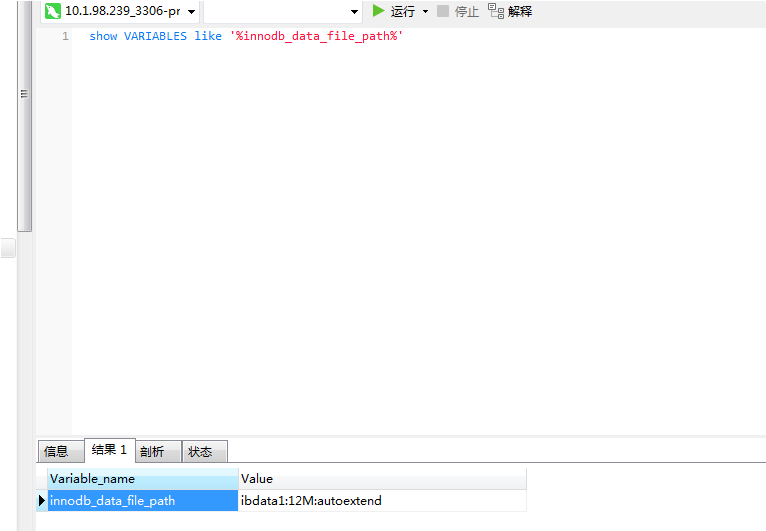
建议修改项:
innodb_data_file_path = ibdata1:1G:autoextend
2.1.2 行存储格式
InnoDB存储引擎面向行存储的,行记录数据按照行格式存放的。
InnoDB文件存储格式:Antelope、Barracuda
行记录格式:Antelope : compact 、redundant
行记录格式:Barracuda : dynamic 、compressed
MySQL 5.7 默认使用dynamic行记录格式 Barracuda文件存储格式,建议不修改。(成本核算系统未使用dynamic行记录格式)
如果需要修改需要了解:行溢出
可以通过show tables status 查看相关信息
2.2内存参数
MySQL内存组成类似ORACLE,也可以分为SGA(系统全局区)、PGA(程序缓存区),
可以通过show VARIABLES like '%buffer%' 查看
主要参数:
2.2.1. Innodb_buffer_pool_size:
用于缓存InnoDB表数据、索引、插入缓冲、数据字典等信息。常用数据可以缓存在内存处理,提高很大效率。
官方建议:该参数设置为物理内存的50%-80%,
生产建议修改参数:(目前生产数据库内存64G)
innodb_buffer_pool_size = 32G
2.2.2. Innodb_buffer_pool_instance:
默认情况下,innodb_buffer_pool_instance值为1个,当修改Innodb_buffer_pool_size值大于1G时候,生成的innodb_buffer_pool_instance才生效,修改后会变为8个,最大为64。
Innodb_buffer_pool_instance可以理解为划分innodb_buffer_pool_size为多个区域,各个缓冲区管理自己区域,高并发情况下可以避免内存征用问题。
缓冲池大小必须始终等于innodb_buffer_pool_chunk_size * 的倍数或倍数 innodb_buffer_pool_instances
优化参考:
调优参考计算方法: val = Innodb_buffer_pool_pages_data / Innodb_buffer_pool_pages_total * 100% val > 95% 则考虑增大 innodb_buffer_pool_size, 建议使用物理内存的75% val < 95% 则考虑减小 innodb_buffer_pool_size, 建议设置为:Innodb_buffer_pool_pages_data * Innodb_page_size * 1.05 / (1024*1024*1024)
2.2.3innodb_buffer_pool_load_at_startup
2.2.4innodb_buffer_pool_dump_at_shutdown
数据库高峰期,如果数据库突然夯机,内存中保留的数据就消失,只能从磁盘读取出来再调回内存中,这样会时i/o压力较大,影响业务。如何快速把内存热数据加载回来,MySQL 5.7 默认开启上述两个参数
2.2.5 innodb_thread_concurrency
Innodb最大并发线程数,默认值为0,大表不受限制。
建议:很多优化建议修改为cpu核数的2倍或者1.5倍
2.2.6 Interactive_timeout wait_timeout
Interactive_timeout是服务器关闭交互式连接前等待活动时间,默认为28800s(8小时)
wait_timeout是服务器关闭非交互式连接前等待活动时间,默认为28800s(8小时)
理解:交互式连接和非交互式连接
修改建议:8小时时间太过长,建议修改为300- 600s
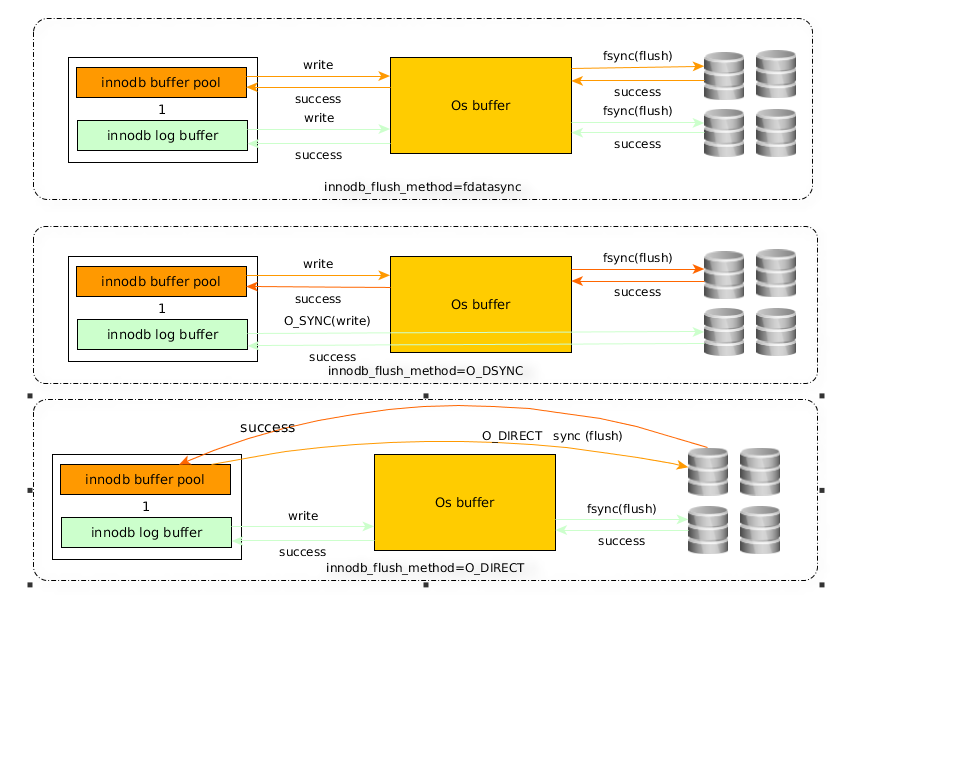
2.2.7 Innodb_flush_method
此参数主要影响Innodb数据文件、redo log文件打开刷写模式。主要三个值,建议采用O_DIRECT模式,三种值理解如下图。MySQL默认为第一种
2.2.8 Innodb_open_files
Innodb可同时打开的.bd 文件个数,最小值为10 默认值为200,建议调整大65535
2.2.9 Join_buffer_size
用途:表连接使用,按需调整,默认配置建议128M
2.2.10 Sort_buffer_size
用途:用于SQL语句在内存中临时排序,默认值2M,按需修改
2.2.11 Tmp_table_size
用途:sql语句在排序或者分组时没用到索引,就会使用临时表空间
建议设置
默认16M 可以按需调整大
2.2.12 Max_heap_table_size
用途:用于管理heap 、memory存储引擎表.值需要设置和Tmp_table_size一致
2.2.13 Innodb_io_capacity
Innodb后台进程最大io性能指标,影响刷新脏页和插入缓冲数量,默认值为200,官方建议修改为每秒I/o数据。需要进行性能压测找出合适值。
2.3线程参数:
MySQL四大线程read thread 、wirte thread、redo log thread、change buffer thread。Redo log thread负责吧日志缓冲中内容刷新到redo文件,change buffer thread负责把插入缓冲内容刷新到磁盘,read、write为数据库读写请求,默认值为4,磁盘i/o状态较好的情况下,可以修改增大。
2.3.1 innodb_flush_log_at_trx_commit
MySQL Redo log 文件同ORACLE 一样,循环写入,写满一个后会发生redo切换,redo首先写入redo log buffer,通过上述参数刷新到磁盘。
innodb_flush_log_at_trx_commit 参数如何选择合适值,0,1,2
0:redolog线程每隔1s将redo log buffer写入 redo log文件,同时进行磁盘刷新操作(性能最好,但是不安全,可能丢失1s内数据)
1:每次事务提交时将redo log buffer写入 redo log文件,同时进行磁盘刷新操作(最安全的方式,性能最慢)
2:每次事务提交时将redo log buffer写入redo log文件,但是不会刷新磁盘(介于2者之间)
建议:生产环境设置为 1
2.3.1 sync_binlog
MySQL binlog至关重要,我理解的主要用于备份恢复以及主从、集群同步使用。
Binlog写入也是先写入binlog_buffer,通过sync_binlog 参数刷新到磁盘
binlog 刷新到磁盘sync_log参数控制,sysnc_log=0,事务提交之后mysql不做binlog_cache刷新到磁盘,而是等filesystem自行决定什么时候刷新到磁盘,或者cache满了之后刷新
sync_log=n MySQL进行n次事务提交之后刷新数据到磁盘,设置为1(最安全)
建议:生产环境设置为1。主从情况下最不容易丢失数据
2.4其他参数:
2.4.1 Expie_logs_days binlog
过期参数,单位为天,主要用于保存binlog周期,建议修改为一周
2.4.2Lower_case_table_names
表名是否区分大小写,建议设置为1 不区分,全部转换为小写存储
2.4.3 Binlog_cache_size
所有未提交的事务会记录到binlog_cache,等待事务提交,提交之后会记录到binlog,缓存大小由参数binlog_cache_size决定,默认32k。
设置此值可以通过 show global status like '%binlog%'查看:
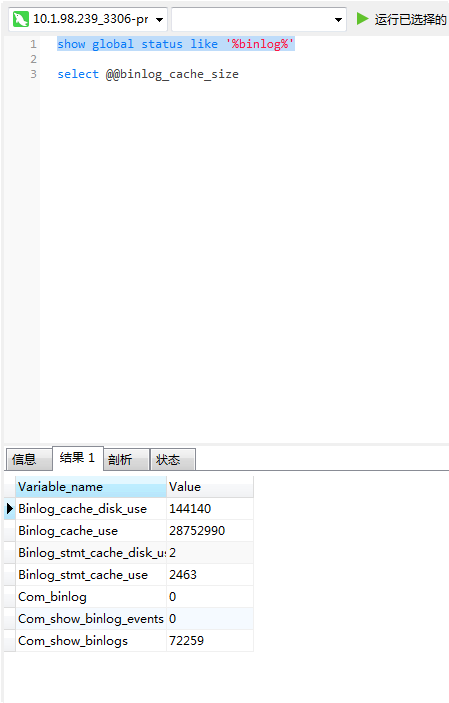
其中binlog_cache_disk_use为144k,已经使用磁盘临时文件,建议增大binlog_cache_size,生产建议2-4M。使用注意:binlog_cache_size是基于会画的,也就是开启一个会画连接时候,MySQL自动为这个会画事务开启一个binlog_cache_size 大小的缓存。
2.4.4 Max_binlog_size
Max_binlog_size 控制单个binlog文件大小,MySQL 5.7默认binlog大小为1G,当写满一个或者flush logs时候会触发刷新binlog操作。
生产环境建议减小binlog大小,可以设置为256M或者512M,更加便于采用binlog恢复。
2.4.5 Binlog_format
Binlog_format 代表binlog日志格式,生产环境强烈建议采用ROW模式,至于三种格式的优缺点请自己去研究学习。
2.4.4 Max_connections
MySQL最大连接数,需要合理评估目前业务连接数,性能测试后规划合理值,避免出现OOM现象。 类似于sort_buffer_size binlog_cache_size等是基于会画的,和数据库连接数有关联
2.5主从参数:
2.5.1 slave-parallel-type=LOGICAL_CLOCK slave-parallel-workers=16
如何减少延时:首先MySQL 5.6就有基于库的并行复制,MySQL5.7进一步实现了基于组提交的并行复制,简单说就是主库并行执行sql,从库也可以通过多个workers线程并发执行relay log,默认情况下slave_parallel_type=database,我们可以更改为基于组提交方式,(logical_database),并且增大slave_parallel_workers,让其>0.
生产环境主从下建议使用此参数
slave-parallel-type=LOGICAL_CLOCK
slave-parallel-workers=16
2.5.2 relay_log_recovery=ON
默认情况下,此参数是关闭的,强烈要求开启relay_log_recovery=ON,目的是从库发生故障意外夯机时候,会删除未执行完的中继日志,重新从主库binlog获取,重新生成relay log。
2.5.3 log_slave_updates=ON
此参数建议开启,此参数作用:从库接收到master传过来的binlog后会立即写入relay log
2.5.4 Relay_log_purge
此参数会清除从库上sql线程已经应用过的relay log,从库环境强烈建议开启。
5.7版本My.cnf参数模板
|
[mysqld]
basedir = /usr/local/mysql
datadir = /data/mysql/
socket = /data/mysql/mysql.sock
character-set-server = utf8
skip_name_resolve = 1 #禁用域名解析
open_files_limit = 65535 #修改最大文件打开数,默认1000
max_connections = 500 #最大连接数,按需调整,避免oom
max_connect_errors = 1000000 #最大错误连接次数
max_allowed_packet = 32M #按需调整,避免mysqldump出现max packet问题
sort_buffer_size = 4M #按需调整,排序空间
join_buffer_size = 4M #按需调整
thread_cache_size = 768 #线程缓冲,按需调整 show global status like '%thread%' 分析实际情况
interactive_timeout = 600 #服务器关闭交互式连接前等待活动时间,此参数和wait_timeout最好调整为一致,默认8小时
wait_timeout = 600 #服务器关闭非交互式连接前等待活动时间 和interactive_timeout保持一致,默认8小时
tmp_table_size = 32M #sql语句在排序或者分组时没用到索引,就会使用临时表空间,默认16M,按需调整
max_heap_table_size = 32M
slow_query_log = 1 #开启慢查询
slow_query_log_file = /data/mysql/slow.log
log-error = /data/mysql/error.log
long_query_time = 0.1 #慢查询时间默认10s,按需调整
server-id = 3306101 #配置主从时候一定要设置,且不能和从库一致,否则gg
log-bin = /data/mysql/mysql-binlog #生产环境必须开启binlog
sync_binlog = 1 #此参数也非常重要,建议为1,提交一个事务binlog_cache及刷新到磁盘
binlog_cache_size = 4M #此参数基于会画,按需调整,需要根据当前服务器状态调整,避免设置过大出现oom
max_binlog_cache_size = 1G
max_binlog_size = 1G #binlog最大大小
expire_logs_days = 7 #设置binlog过期参数
gtid_mode = on #gtid模式下主从必须开启
enforce_gtid_consistency = 1 #gtid模式必须开启,强制事务一致
log_slave_updates=on #从库环境开启,接收master binlog即写入relay
binlog_format = row #生产环境规范统一必须为ROW
relay_log_recovery = 1 #从库异常夯机,自动删除未应用的relay,建议从库开启
relay-log-purge = 1 #从库开启,自动删除应用过的relay
key_buffer_size = 32M
read_buffer_size = 8M
read_rnd_buffer_size = 4M
bulk_insert_buffer_size = 64M
lock_wait_timeout = 3600 #锁等待时间,默认较大,建议调整小
explicit_defaults_for_timestamp = 1 #此参数用于控制timestamp字段(参考第四部分说明)
innodb_thread_concurrency = 0 #Innodb最大并发线程数,默认值为0,大表不受限制。很多建议调整为cpu核数一致,建议设置为0
innodb_buffer_pool_size = 1024M #innodb缓冲池调整为物理内存的50%至80%
innodb_buffer_pool_instances = 8 #缓冲池实例,按需调整
innodb_buffer_pool_load_at_startup = 1 #默认开启,请勿关闭(作用参考上述文章)
innodb_buffer_pool_dump_at_shutdown = 1 #默认开启,请勿关闭
innodb_data_file_path = ibdata1:1G:autoextend #表空间文件大小,建议调大
innodb_flush_log_at_trx_commit = 1 #生产环境必须统一开启
innodb_log_buffer_size = 32M #生产环境建议按需调大,默认16M,不能调整过大,避免恢复耗费很长时间
innodb_io_capacity = 4000 #生产环境按需调整,官方建议调整为每秒i/o数,默认为200,建议调大
innodb_io_capacity_max = 8000
innodb_flush_neighbors = 0
innodb_write_io_threads = 8 #按需调整默认4
innodb_read_io_threads = 8 #按需调整默认4
innodb_purge_threads = 4
innodb_page_cleaners = 4
innodb_open_files = 65535
innodb_max_dirty_pages_pct = 50 #InnoDB尝试从缓冲池中刷新数据,以便脏页的百分比不超过此值,默认值为75。
innodb_flush_method = O_DIRECT #生产建议采用O_DIRECT模式
innodb_file_per_table = 1 #默认值
#从库参数
master_info_repository=TABLE
relay_log_info_repository=TABLE
relay_log_recovery=ON
log_slave_updates=ON
relay_log_purge=1
slave-parallel-type=LOGICAL_CLOCK
slave-parallel-workers=16
[mysqldump]
quick
max_allowed_packet = 32M
|
几种注意的数据类型
4.1 decimal类型
MySQL使用中经常用decimal(M,D)类型存储金钱,其中D代表小数点部分,若插入的值未指定小数部分,或者小数部分不足D位数,结果会被截断,并且采用四舍五入方式截断。多余当然无法插入,其中M代表总长度。使用时候需要注意
例如 decimal(6,2)
插入 22.3569 会自动四舍五入为22.36
4.2 Timestamp类型
Timestamp类型一开始我觉得非常的坑爹。默认环境中,你通过navicate建表,字段增加not null约束,您还特意勾掉默认值和触发器,建完成之后你查看建表语句,变成了如下,而且只要这个表和create_time不相关的字段执行了update操作,create_time都会变成当前默认时间
CREATE TABLE `t_user_archive_privilege` (
`id` int(11) NOT NULL AUTO_INCREMENT COMMENT '自增主键',
`user_account` varchar(30) NOT NULL COMMENT '用户account',
`archive_id` int(11) NOT NULL COMMENT '档案Id',
`create_time` datetime DEFAULT CURRENT_TIMESTAMP COMMENT '创建时间',
`expire_time` datetime DEFAULT NULL COMMENT '过期时间',
`original_doc` tinyint(4) NOT NULL DEFAULT '0' COMMENT '是否借阅原件 0:否 1:是',
`creator_account` varchar(30) DEFAULT '' COMMENT '创建者account',
`source` varchar(32) DEFAULT NULL COMMENT '文件来源,如:OA',
PRIMARY KEY (`id`),
KEY `idx_user_account` (`user_account`),
KEY `idx_archive_id` (`archive_id`)
) ENGINE=InnoDB AUTO_INCREMENT=10060 DEFAULT CHARSET=utf8 COMMENT='用户档案临时权限表'
生产环境中不建议这么使用,如果需要使用,可以修改参数。生产环境建议使用datatime
explicit_defaults_for_timestamp=off 时表结构
CREATE TABLE `t` (
`x` int(11) DEFAULT NULL,
`y` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
-- `y` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE
2、explicit_defaults_for_timestamp=on 时表结构
CREATE TABLE `t6` (
`x` int(11) DEFAULT NULL,
`y` timestamp NULL DEFAULT NULL
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
-- `y` timestamp NULL DEFAULT NULL
4.3 datatime类型
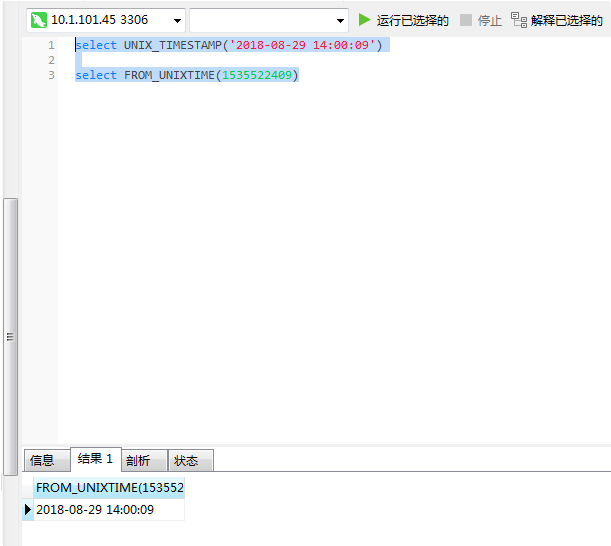
相比timestamp类型生产环境建议可以使用datatime类型,或者用时间戳(采用int)来存储,可以通过两个函数进行时间转换
Unix_timestamp from_unixtime
4.4 ip地址类型
IPv4这样的字段,建议使用int型存储,日常开发中可能大部分采用varchar存储。Inet_aton
Inet_ntoa 做相应转换