环境准备
运行这个预训练的模型需要准备一些环境
首先需要下载谷歌的models-master.zip
地址在https://github.com/Master-Chen/models

下载完成后我们需要的是research/objection_detection这个项目
在运行这个项目之前还需要下载谷歌的protoc3.4.0
下载结束后只需要将bin目录里的protoc.exe文件放在有环境变量的一个目录下即可
之后在research路径下打开命令行 运行 protoc objection_detection/protocs/*.proto --python_out=.
这里运行后会在object_detection\protos路径下生成许多py文件,相当于把原来的proto文件编译成了py文件
至此,环境准备基本完成。注意的是,这里使用的tensorflow1.13.1-cpu
运行模型
准备工作完成后,在objection_detection路径下启动jupyter notebook,找到

进入这个笔记本
可以看到,这个笔记本将引导使用者运行这个预训练的目标检测模型
import warnings
warnings.filterwarnings("ignore")
import numpy as np
import os
import six.moves.urllib as urllib
import sys
import tarfile
import tensorflow as tf
import zipfile
from distutils.version import StrictVersion
from collections import defaultdict
from io import StringIO
from matplotlib import pyplot as plt
from PIL import Image
# This is needed since the notebook is stored in the object_detection folder.
sys.path.append("..")
from object_detection.utils import ops as utils_ops
# tf版本需要大于1.9
if StrictVersion(tf.__version__) < StrictVersion('1.9.0'):
raise ImportError('Please upgrade your TensorFlow installation to v1.9.* or later!')
# 在jupyter里面显示图片
%matplotlib inline
from utils import label_map_util
from utils import visualization_utils as vis_util
- 指定模型的相关配置,譬如模型名称,下载地址,对应得pb文件存放路径,数据集label映射文件路径
这里使用的是SSD模型,在coco数据集上训练的,其他模型文件可以在github下载
# 模型名称
MODEL_NAME = 'ssd_mobilenet_v1_coco_2017_11_17'
MODEL_FILE = MODEL_NAME + '.tar.gz'
# 下载地址
DOWNLOAD_BASE = 'http://download.tensorflow.org/models/object_detection/'
# pb模型存放位置
PATH_TO_FROZEN_GRAPH = MODEL_NAME + '/frozen_inference_graph.pb'
# coco数据集的label映射文件
PATH_TO_LABELS = os.path.join('data', 'mscoco_label_map.pbtxt')
# 下载文件
opener = urllib.request.URLopener()
opener.retrieve(DOWNLOAD_BASE + MODEL_FILE, MODEL_FILE)
# 解压文件
tar_file = tarfile.open(MODEL_FILE)
for file in tar_file.getmembers():
file_name = os.path.basename(file.name)
if 'frozen_inference_graph.pb' in file_name:
tar_file.extract(file, os.getcwd())
这里运行结束后会在object_detection路径下生成
并且会解压,且只解压出对应的pb文件,因为这里只使用模型,不重训练模型
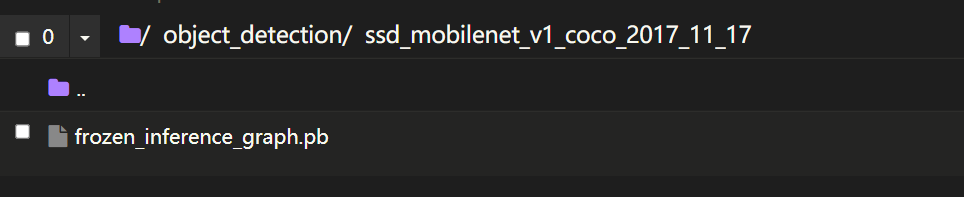
-这里下载大概率会因网络问题无法成功,可以手动下载解压
地址 https://github.com/tensorflow/models/blob/master/research/object_detection/g3doc/tf1_detection_zoo.md
# 载入训练好的pb模型
detection_graph = tf.Graph()
with detection_graph.as_default():
od_graph_def = tf.GraphDef()
with tf.gfile.GFile(PATH_TO_FROZEN_GRAPH, 'rb') as fid:
serialized_graph = fid.read()
od_graph_def.ParseFromString(serialized_graph)
tf.import_graph_def(od_graph_def, name='')
# 得到一个保存编号和类别描述映射关系的字典
category_index = label_map_util.create_category_index_from_labelmap(PATH_TO_LABELS, use_display_name=True)
print(category_index)

- 定义一个方法,把图片读取出三维数据,类型转换为uint8
def load_image_into_numpy_array(image):
(im_width, im_height) = image.size
return np.array(image.getdata()).reshape((im_height, im_width, 3)).astype(np.uint8)
# 目标检测
def run_inference_for_single_image(image, graph):
with graph.as_default():
with tf.Session() as sess:
# 获得图中所有op
ops = tf.get_default_graph().get_operations()
# 获得输出tensor的名字
all_tensor_names = {output.name for op in ops for output in op.outputs}
tensor_dict = {}
for key in [
'num_detections', 'detection_boxes', 'detection_scores',
'detection_classes',
]:
tensor_name = key + ':0'
# 如果tensor_name在all_tensor_names中
if tensor_name in all_tensor_names:
# 则获取到该tensor
tensor_dict[key] = tf.get_default_graph().get_tensor_by_name(
tensor_name)
# 图片输入的tensor
image_tensor = tf.get_default_graph().get_tensor_by_name('image_tensor:0')
# 传入图片运行模型获得结果
output_dict = sess.run(tensor_dict,
feed_dict={image_tensor: image})
# 所有的结果都是float32类型的,有些数据需要做数据格式转换
# 检测到目标的数量
output_dict['num_detections'] = int(output_dict['num_detections'][0])
# 目标的类型
output_dict['detection_classes'] = output_dict[
'detection_classes'][0].astype(np.uint8)
# 预测框坐标
output_dict['detection_boxes'] = output_dict['detection_boxes'][0]
# 预测框置信度
output_dict['detection_scores'] = output_dict['detection_scores'][0]
return output_dict
- 遍历测试图像,输出检测结果,测试图像路径在test_iamges,将要测试的图像放进该路径即可
for root,dirs,files in os.walk('test_images/'):
for image_path in files:
# 读取图片
image = Image.open(os.path.join(root,image_path))
# 把图片数据变成3维的数据,定义数据类型为uint8
image_np = load_image_into_numpy_array(image)
# 增加一个维度,数据变成: [1, None, None, 3]
image_np_expanded = np.expand_dims(image_np, axis=0)
# 目标检测
output_dict = run_inference_for_single_image(image_np_expanded, detection_graph)
# 给原图加上预测框,置信度和类别信息
vis_util.visualize_boxes_and_labels_on_image_array(
image_np,
output_dict['detection_boxes'],
output_dict['detection_classes'],
output_dict['detection_scores'],
category_index,
use_normalized_coordinates=True,
line_thickness=8)
# 画图
plt.figure(figsize=(12,8))
plt.imshow(image_np)
plt.axis('off')
plt.show()





编译好的项目文件可以从这里下载:https://download.csdn.net/download/cyj5201314/18171589