最近web端更新比较频繁,所以搞了很多方案来应对更新问题。
本文内容是其中一种方案,从用户主页的HTML响应内容中抽取user信息和作品列表数据。
下图中出现的内容都是在html名为RENDER_DATA的script标签中,以urlencode编码。
比如昵称、粉丝、获赞、地区、第一页的作品列表等。
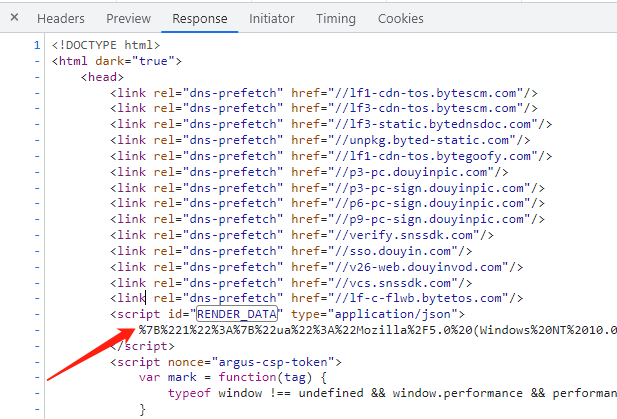
取出来格式化后可转换成Json格式查阅。用户信息在user中,作品列表在data中。

接下来就是如何获取用户主页HTML文本。
分析测试
根据笔者的分析和测试,目前请求 /user/sec_user_id 需要提前准备好的参数有cookie中的 __ac_nonce、__ac_signature、ttwid。
现在ttwid作为了游客ID,权重甚至超过了校验参数 s_v_web_id。
__ac_nonce和ttwid是服务端返回的,但是如果直接从用户主页去获取ttwid,则需要有 s_v_web_id作为注册前提,所以可以从index页面去注册ttwid。
__ac_signature的生成在之前的文章中有过讲解,《DY__ac_signature》,所以本文不再复述了。
请求流程
直接把流程贴出来吧。__ac_signature的生成可参考之前的文章《DY__ac_signature》。
请求这块经常更新,如果更新了大家自己照着官网流程改改。
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
import json
import re
from urllib import parse
import execjs
import requests
from requests.adapters import HTTPAdapter
from requests.packages.urllib3.util.ssl_ import create_urllib3_context
class CipherAdapter(HTTPAdapter):
def init_poolmanager(self, *args, **kwargs):
context = create_urllib3_context(ciphers='DEFAULT:@SECLEVEL=2')
kwargs['ssl_context'] = context
return super(CipherAdapter, self).init_poolmanager(*args, **kwargs)
def proxy_manager_for(self, *args, **kwargs):
context = create_urllib3_context(ciphers='DEFAULT:@SECLEVEL=2')
kwargs['ssl_context'] = context
return super(CipherAdapter, self).proxy_manager_for(*args, **kwargs)
def get_ac_sign(ac_nonce):
with open('_ac_signature.js', 'r', encoding='utf-8') as f:
b = f.read()
c = execjs.compile(b)
d = c.call('get_ac_signature',ac_nonce)
return d
def run(sec_user_id):
sess = requests.session()
sess.proxies = proxies
headers_base = {
"accept":"text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.7",
"accept-language":"zh-CN,zh;q=0.9",
"cache-control":"no-cache",
"pragma":"no-cache",
"sec-ch-ua":"\"Google Chrome\";v=\"111\", \"Not(A:Brand\";v=\"8\", \"Chromium\";v=\"111\"",
"sec-ch-ua-mobile":"?0",
"sec-ch-ua-platform":"\"Windows\"",
"sec-fetch-dest":"document",
"sec-fetch-mode":"navigate",
"sec-fetch-site":"none",
"sec-fetch-user":"?1",
"upgrade-insecure-requests":"1",
"user-agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/111.0.0.0 Safari/537.36"
}
sess.headers = headers_base
url = 'https://www.douyin.com'
sess.mount(url, CipherAdapter())
__ac_nonce = sess.get(url,headers=headers_base).cookies.get('__ac_nonce')
print(__ac_nonce)
__ac_signature = get_ac_sign(__ac_nonce)
headers = {
'authority': 'www.douyin.com',
'accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9',
'accept-language': 'zh-CN,zh;q=0.9,en-XA;q=0.8,en;q=0.7,zh-TW;q=0.6',
'cache-control': 'max-age=0',
'dnt': '1',
'sec-ch-ua': '".Not/A)Brand";v="99", "Google Chrome";v="103", "Chromium";v="103"',
'sec-ch-ua-mobile': '?0',
'sec-ch-ua-platform': '"Windows"',
'cookie': f'douyin.com; __ac_nonce={__ac_nonce}; __ac_signature={__ac_signature}; __ac_referer={url};',
'sec-fetch-dest': 'document',
'sec-fetch-mode': 'navigate',
'referer': f'https://www.douyin.com',
'sec-fetch-site': 'same-origin',
'sec-fetch-user': '?1',
'upgrade-insecure-requests': '1',
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/103.0.0.0 Safari/537.36'
}
response = sess.get(url,headers=headers)
ttwid = response.cookies.get('ttwid')
print(ttwid)
headers = {
'authority': 'www.douyin.com',
'accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9',
'accept-language': 'zh-CN,zh;q=0.9,en-XA;q=0.8,en;q=0.7,zh-TW;q=0.6',
'cache-control': 'max-age=0',
'dnt': '1',
'sec-ch-ua': '".Not/A)Brand";v="99", "Google Chrome";v="103", "Chromium";v="103"',
'sec-ch-ua-mobile': '?0',
'sec-ch-ua-platform': '"Windows"',
'cookie': f'douyin.com; __ac_nonce={__ac_nonce}; __ac_signature={__ac_signature}; ttwid={ttwid}; douyin.com; home_can_add_dy_2_desktop=%220%22; strategyABtestKey=%221685349310.836%22; passport_csrf_token=lxisgood7f517e5b9315589c38256f13; passport_csrf_token_default=lxisgood7f517e5b9315589c38256f13; s_v_web_id=verify_lxisgood_tskRru8j_t7Rk_4R4X_84w7_JNOTPvaLip42;',
'sec-fetch-dest': 'document',
'sec-fetch-mode': 'navigate',
'referer': f'https://www.douyin.com',
'sec-fetch-site': 'same-origin',
'sec-fetch-user': '?1',
'upgrade-insecure-requests': '1',
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/103.0.0.0 Safari/537.36'
}
user_url = f"https://www.douyin.com/user/MS4wLjABAAAA1_iC_Juo6ByvfBeN75UXmhP9zjqi7wsIchjuzv7tOsc?"
response = sess.get(user_url, headers=headers)
doc =re.findall('<script id="RENDER_DATA" type="application/json">(.*?)</script>', response.text, re.S)[0]
data = json.loads(parse.unquote(doc))
return data
if __name__ == '__main__':
proxies= {}
sec_user_id = "MS4wLjABAAAACV5Em110SiusElwKlIpUd-MRSi8rBYyg0NfpPrqZmykHY8wLPQ8O4pv3wPL6A-oz"
data = run(sec_user_id)
print(data)
# data['*']['user']: IP地址、年龄、粉丝信息等
# data['*']['post']: 作品列表、bitRateList