这期继续说说统计这些事,泊松分布大家可能熟悉些,但是用它来做模型还是需要细细品味一下**。**
泊松回归,也被称为对数线性模型,当结果变量是一个计数(即数值型,但不像连续变量的范围那么大)时,使用泊松回归。研究中统计变量的例子包括一个人有多少次心脏病发作或中风,在过去的一个月中他服用了多少天(插入你最喜欢的非法药物),或者,在生存分析中,从爆发到感染有多少天。泊松分布是唯一的,因为它的均值和方差相等。这通常是由于零通胀。有时可能有两个过程在起作用:一个决定事件是否发生,另一个决定事件发生时发生了多少次。使用我们的计数变量,这可能是一个示例,其中包含个人有无心脏病:那些没有心脏病导致的数据过多的零和那些有心脏病减弱尾部向右与越来越多的心脏病发作。这就是为什么逻辑回归和泊松回归一起出现在研究中:在泊松分布中有一个固有的二分结果。但是,如果不进一步进行泊松回归,就无法理解逻辑问题中的命中点。
01****泊松回归的概念
———————
泊松回归适用于在给定时间内响应变量为事件发生数目的情况,它假设 Y 服从泊松分布,线性模型的拟合形式为
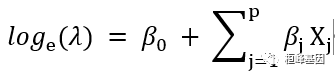
其中 λ 是 Y 的均值(也等于方差),此时,连接函数 log(λ),概率分布为泊松分布。
R中的泊松回归是一种回归分析模型,用于预测分析,其中有多个可能的结果是可数的。R语言提供了计算和评估泊松回归模型的内置函数 glm(),其中参数 family=poisson() 即为泊松回归,如下:
glm(Y ~ X1 + X2 + X3, family=poisson(),data=mydata)
下面举两个实例做模型,这两个例子都是参考R 包里面自带的数据,当我们使用时需要搞清自己的因变量是哪种类型,才能够选择准确的模型,上面已经说过,泊松回归因变量是有多个可数的结果,即结果是可以计算的,才能够选择泊松回归构建临床预测模型。
02 计数变量实例解析
—————————
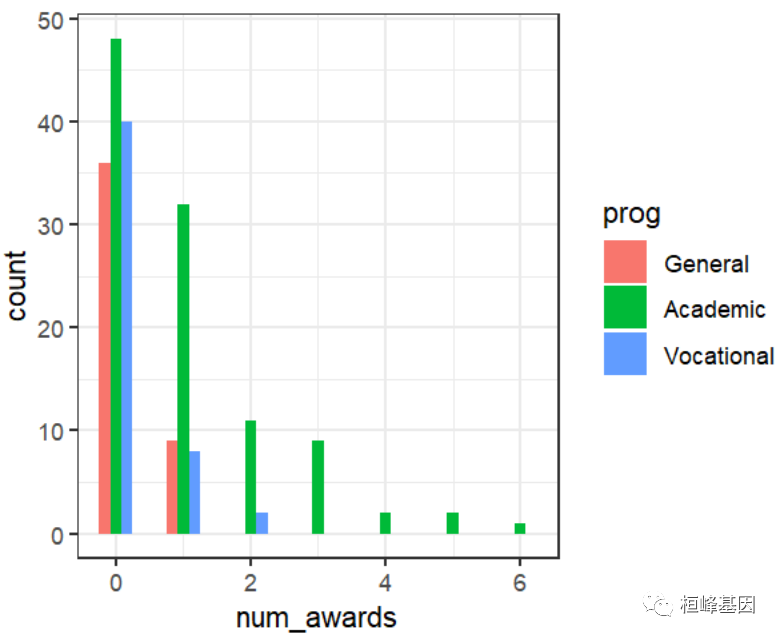
软件包安装及数据读取,并且对数据进行整理,利用网络上的例子:一所高中的学生获得的奖项数量。预测获奖人数的因素包括学生就读的课程类型(例如,职业课程、普通课程或学术课程)和他们的数学期末考试分数,数据分布情况如下:
install.packages("sandwich")
install.packages("msm")
require(ggplot2)
require(sandwich)
require(msm)
p <- read.csv("https://stats.idre.ucla.edu/stat/data/poisson_sim.csv")
p <- within(p, {
prog <- factor(prog, levels=1:3, labels=c("General", "Academic",
"Vocational"))
id <- factor(id)
})
summary(p)
id num_awards prog math
1 : 1 Min. :0.00 General : 45 Min. :33.00
2 : 1 1st Qu.:0.00 Academic :105 1st Qu.:45.00
3 : 1 Median :0.00 Vocational: 50 Median :52.00
4 : 1 Mean :0.63 Mean :52.65
5 : 1 3rd Qu.:1.00 3rd Qu.:59.00
6 : 1 Max. :6.00 Max. :75.00
(Other):194
ggplot(p, aes(num_awards, fill = prog)) +
geom_histogram(binwidth=.5, position="dodge")+
theme_bw()
过度离势
抽样于二项分布的数据的期望方差是 σ2 = nπ(1-π),n为观测数,π为属于Y=1组的概率。所谓过度离势,即观测到的响应变量的方差大于期望的二项分布的方差。过度离势会导致奇异的标准 误检验和不精确的显著性检验。检测过度离势的一种方法是比较二项分布模型的残差偏差与残差自由度,如下:

当其值大于1非常多时,则认为存在过度离势,同样的,也可以对其进行检验。
pchisq(summary(m1)$dispersion * fit$df.residual, fit$df.residual, lower = F)
[1] 0.4746369
利用上述数据拟合泊松回归模型,整个过程包括模型结果的数据整理,如下:
m1 <- glm(num_awards ~ prog + math, family="poisson", data=p)
summary(m1)
Call:
glm(formula = num_awards ~ prog + math, family = "poisson", data = p)
Deviance Residuals:
Min 1Q Median 3Q Max
-2.2043 -0.8436 -0.5106 0.2558 2.6796
Coefficients:
Estimate Std. Error z value Pr(>|z|)
(Intercept) -5.24712 0.65845 -7.969 1.60e-15 ***
progAcademic 1.08386 0.35825 3.025 0.00248 **
progVocational 0.36981 0.44107 0.838 0.40179
math 0.07015 0.01060 6.619 3.63e-11 ***
---
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
(Dispersion parameter for poisson family taken to be 1)
Null deviance: 287.67 on 199 degrees of freedom
Residual deviance: 189.45 on 196 degrees of freedom
AIC: 373.5
Number of Fisher Scoring iterations: 6
cov.m1 <- vcovHC(m1, type="HC0")
cov.m1
(Intercept) progAcademic progVocational math
(Intercept) 0.417313917 -0.0501798114 -9.053756e-02 -5.996339e-03
progAcademic -0.050179811 0.1030719195 8.710937e-02 -6.688459e-04
progVocational -0.090537557 0.0871093744 1.603340e-01 5.649134e-05
math -0.005996339 -0.0006688459 5.649134e-05 1.088927e-04
std.err <- sqrt(diag(cov.m1))
r.est <- cbind(Estimate= coef(m1), "Robust SE" = std.err,
"Pr(>|z|)" = 2 * pnorm(abs(coef(m1)/std.err), lower.tail=FALSE),
LL = coef(m1) - 1.96 * std.err,
UL = coef(m1) + 1.96 * std.err)
r.est
with(m1, cbind(res.deviance = deviance, df = df.residual,
p = pchisq(deviance, df.residual, lower.tail=FALSE)))
Estimate Robust SE Pr(>|z|) LL UL
(Intercept) -5.2471244 0.64599839 4.566630e-16 -6.51328124 -3.98096756
progAcademic 1.0838591 0.32104816 7.354745e-04 0.45460476 1.71311353
progVocational 0.3698092 0.40041731 3.557157e-01 -0.41500870 1.15462716
math 0.0701524 0.01043516 1.783975e-11 0.04969947 0.09060532
## update m1 model dropping prog
m2 <- update(m1, . ~ . - prog)
## test model differences with chi square test
anova(m2, m1, test="Chisq")
s <- deltamethod(list(~ exp(x1), ~ exp(x2), ~ exp(x3), ~ exp(x4)),
coef(m1), cov.m1)
## exponentiate old estimates dropping the p values
rexp.est <- exp(r.est[, -3])
## replace SEs with estimates for exponentiated coefficients
rexp.est[, "Robust SE"] <- s
rexp.est
(s1 <- data.frame(math = mean(p$math),
prog = factor(1:3, levels = 1:3, labels = levels(p$prog))))
predict(m1, s1, type="response", se.fit=TRUE)
## calculate and store predicted values
p$phat <- predict(m1, type="response")
## order by program and then by math
p <- p[with(p, order(prog, math)), ]
## create the plot
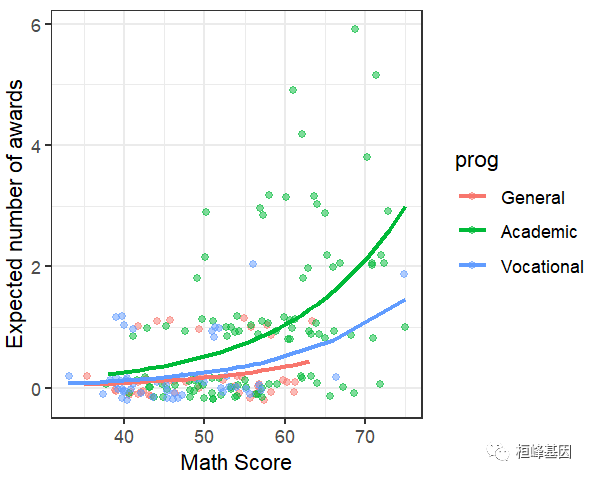
ggplot(p, aes(x = math, y = phat, colour = prog)) +
geom_point(aes(y = num_awards), alpha=.5, position=position_jitter(h=.2)) +
geom_line(size = 1) +
labs(x = "Math Score", y = "Expected number of awards")+theme_bw()
03 计数变量实例解析
————————
为阐述泊松回归模型的拟合过程,并探讨一些可能出现的问题,我们选择使用robust包中的breslow(癫痫数据)数据。安装R包及数据读取,并且解读数据的意义,从下面我们可以看出响应变量为:sumY(随机化后八周内癫痫发病数),是一个计算变量,再看自变量也就是预测变量为:
-
治疗条件(Trt),包括两种药物组和安慰剂组
-
年龄(Age);
-
前八周的基础癫痫发病数(Base)。
#########possion regression
install.packages("robust")
library(robust)
summary(breslow.dat)
ID Y1 Y2 Y3 Y4 Base
Min. :101.0 Min. : 0.000 Min. : 0.000 Min. : 0.000 Min. : 0.000 Min. : 6.00
1st Qu.:119.5 1st Qu.: 2.000 1st Qu.: 3.000 1st Qu.: 2.000 1st Qu.: 3.000 1st Qu.: 12.00
Median :147.0 Median : 4.000 Median : 5.000 Median : 4.000 Median : 4.000 Median : 22.00
Mean :168.4 Mean : 8.949 Mean : 8.356 Mean : 8.441 Mean : 7.305 Mean : 31.22
3rd Qu.:216.0 3rd Qu.: 10.500 3rd Qu.:11.500 3rd Qu.: 8.000 3rd Qu.: 8.000 3rd Qu.: 41.00
Max. :238.0 Max. :102.000 Max. :65.000 Max. :76.000 Max. :63.000 Max. :151.00
Age Trt Ysum sumY Age10 Base4
Min. :18.00 placebo :28 Min. : 0.00 Min. : 0.00 Min. :1.800 Min. : 1.500
1st Qu.:23.00 progabide:31 1st Qu.: 11.50 1st Qu.: 11.50 1st Qu.:2.300 1st Qu.: 3.000
Median :28.00 Median : 16.00 Median : 16.00 Median :2.800 Median : 5.500
Mean :28.34 Mean : 33.05 Mean : 33.05 Mean :2.834 Mean : 7.805
3rd Qu.:32.00 3rd Qu.: 36.00 3rd Qu.: 36.00 3rd Qu.:3.200 3rd Qu.:10.250
Max. :42.00 Max. :302.00 Max. :302.00 Max. :4.200 Max. :37.750
names(breslow.dat)
[1] "ID" "Y1" "Y2" "Y3" "Y4" "Base" "Age" "Trt" "Ysum" "sumY" "Age10" "Base4"
summary(breslow.dat[c(6, 7, 8, 10)]
Base Age Trt sumY
Min. : 6.00 Min. :18.00 placebo :28 Min. : 0.00
1st Qu.: 12.00 1st Qu.:23.00 progabide:31 1st Qu.: 11.50
Median : 22.00 Median :28.00 Median : 16.00
Mean : 31.22 Mean :28.34 Mean : 33.05
3rd Qu.: 41.00 3rd Qu.:32.00 3rd Qu.: 36.00
Max. :151.00 Max. :42.00 Max. :302.00
table(breslow.dat$sumY)
0 3 4 6 7 10 11 12 13 14 15 16 19 20 22 24 26 28 29 30 32 33 39 42 51 53 55 59 65
1 1 1 4 2 4 2 2 5 4 2 3 1 1 2 1 2 1 1 2 1 1 1 2 1 1 1 1 1
66 70 74 95 123 143 302
1 1 1 1 1 1 1
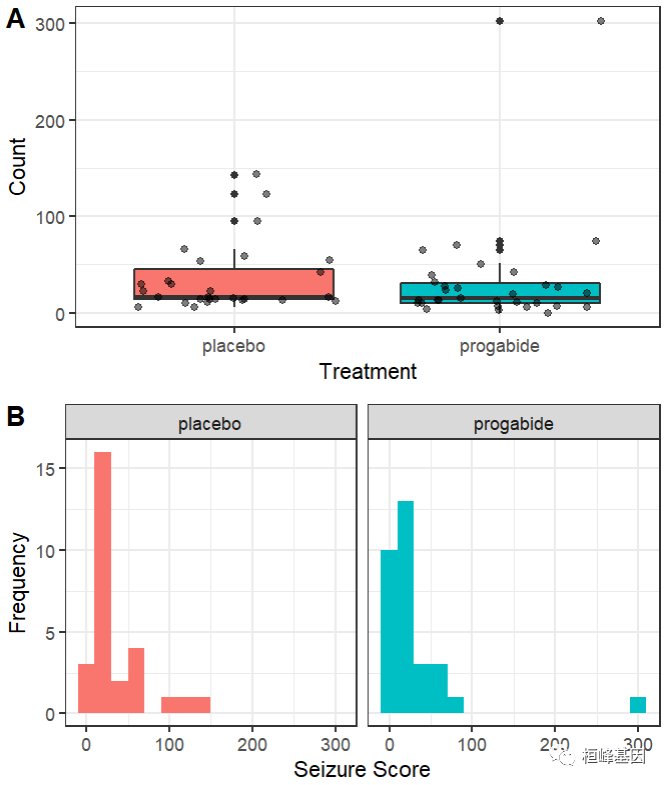
因变量的偏倚特性以及可能的离群点,初看图形时,药物治疗下癫痫发病数似乎变小,且方差也变小了(泊松分布中,较小的方差伴随着较小的均值)。 与标准最小二乘法回归不同,泊松回归并不关注方差异质性。
# plot distribution of post-treatment seizure counts
p1<-ggplot(breslow.dat, aes(Trt,sumY, fill = Trt))+
geom_boxplot()+
geom_point(aes(y = sumY), alpha=.5, position=position_jitter(h=.2))+
labs(x = "Treatment", y = "Count")+
guides(fill=FALSE)+
theme_bw()
p2<-ggplot(breslow.dat, aes(sumY, fill = Trt)) +
geom_histogram(binwidth=20, position="dodge")+
guides(fill=FALSE)+
theme_bw()+
labs(x = "Seizure Score", y = "Frequency")+
facet_grid(~Trt)
cowplot::plot_grid(p1, p2, nrow = 2, labels = LETTERS[1:2])
下面拟合泊松分布,结果我们发现Age、Base 和 Trtprogabide 都是显著的,需要进行过度离势检测,如下:
# fit regression
fit <- glm(sumY ~ Base + Age + Trt, data=breslow.dat, family=poisson())
summary(fit)
Call:
glm(formula = sumY ~ Base + Age + Trt, family = poisson(), data = breslow.dat)
Deviance Residuals:
Min 1Q Median 3Q Max
-6.0569 -2.0433 -0.9397 0.7929 11.0061
Coefficients:
Estimate Std. Error z value Pr(>|z|)
(Intercept) 1.9488259 0.1356191 14.370 < 2e-16 ***
Base 0.0226517 0.0005093 44.476 < 2e-16 ***
Age 0.0227401 0.0040240 5.651 1.59e-08 ***
Trtprogabide -0.1527009 0.0478051 -3.194 0.0014 **
---
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
(Dispersion parameter for poisson family taken to be 1)
Null deviance: 2122.73 on 58 degrees of freedom
Residual deviance: 559.44 on 55 degrees of freedom
AIC: 850.71
Number of Fisher Scoring iterations: 5
# interpret model parameters
coef(fit)
(Intercept) Base Age Trtprogabide
1.94882593 0.02265174 0.02274013 -0.15270095
exp(coef(fit))
(Intercept) Base Age Trtprogabide
7.0204403 1.0229102 1.0230007 0.8583864
当其值大于1非常多时,则认为存在过度离势,同样的,也可以对其进行检验,
# evaluate overdispersion
deviance(fit)/df.residual(fit)
10.1717
######
install.packages("qcc")
library(qcc)
qcc.overdispersion.test(breslow.dat$sumY, type="poisson")
Overdispersion test Obs.Var/Theor.Var Statistic p-value
poisson data 62.87013 3646.468 0
pchisq(summary(fit.od)$dispersion * fit$df.residual, fit$df.residual, lower = F)
[1] 5.844949e-102
对于泊松分布而言,当数据出现过度离势时,可使用 `family="quasipoisson"` 替换 `family="poisson""`的方法部分进行替换,此时,`glm()`结果依旧可用,如下:
#fit model with quasipoisson
fit.od <- glm(sumY ~ Base + Age + Trt, data=breslow.dat,
family=quasipoisson())
summary(fit.od)
Call:
glm(formula = sumY ~ Base + Age + Trt, family = quasipoisson(),
data = breslow.dat)
Deviance Residuals:
Min 1Q Median 3Q Max
-6.0569 -2.0433 -0.9397 0.7929 11.0061
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 1.948826 0.465091 4.190 0.000102 ***
Base 0.022652 0.001747 12.969 < 2e-16 ***
Age 0.022740 0.013800 1.648 0.105085
Trtprogabide -0.152701 0.163943 -0.931 0.355702
---
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
(Dispersion parameter for quasipoisson family taken to be 11.76075)
Null deviance: 2122.73 on 58 degrees of freedom
Residual deviance: 559.44 on 55 degrees of freedom
AIC: NA
Number of Fisher Scoring iterations: 5
04 关于结果解读
———————
在泊松回归中,年龄的回归参数为0.0227,表明保持其他预测变量不变,年龄增 加1岁,癫痫发病数的对数均值将相应增加0.03。截距项即当预测变量都为0时, 癫痫发病数的对数均值。由于不可能为0岁,且调查对象的基础癫痫发病数均不 为0,因此本例中截距项没有意义。通常在因变量的初始尺度(癫痫发病数而非发病数的对数)上解释回归系数比较容易。为此,需要指数化回归系数。
指数化后,保持其他变量不变,年龄增加1岁,期望的癫痫发病数将乘以1.023。这意味着年龄的增加与较高的癫痫发病数相关联。更为重要的是,1单位Trt的变 化(即从安慰剂到治疗组),期望的癫痫发病数将乘以0.86,也就是说,保持基础癫痫发病数和年龄不变,服药组相对于安慰剂组癫痫发病数降低了20%。
这期参考了几本基本资料的书,才搞清使用方法的选择,以及结果的解读,都很有意思,不是轻易能理解,这里我其实看了四五个例子,以及专业的视频教程学习,整理出来,有写的不对的地方,还请各位指正。
关注公众号,每日有更新!

Reference:
-
Robert I. Kabacoff 著, 《R语言实战 》(第2版), 人民邮电出版社, 2016
-
张铁军 陈兴栋 刘振球 著,《R语言与医学统计图形》, 人民卫生出版社, 2018
-
Cameron, A. C. and Trivedi, P. K. 2009. Microeconometrics Using Stata. College Station, TX: Stata Press.
-
Cameron, A. C. and Trivedi, P. K. 1998. Regression Analysis of Count Data. New York: Cambridge Press.
-
Cameron, A. C. Advances in Count Data Regression Talk for the Applied Statistics Workshop, March 28, 2009. http://cameron.econ.ucdavis.edu/racd/count.html .
-
Dupont, W. D. 2002. Statistical Modeling for Biomedical Researchers: A Simple Introduction to the Analysis of Complex Data. New York: Cambridge Press.
-
Long, J. S. 1997. Regression Models for Categorical and Limited Dependent Variables. Thousand Oaks, CA: Sage Publications.
-
Long, J. S. and Freese, J. 2006. Regression Models for Categorical Dependent Variables Using Stata, Second Edition. College Station, TX: Stata Press.