Paper name
BLIP-2: Bootstrapping Language-Image Pre-training with Frozen Image Encoders and Large Language Models
Paper Reading Note
URL: https://arxiv.org/pdf/2301.12597.pdf
TL;DR
- 2023 年 Salesforce 出的文章,提出了 BLIP-2,一种通用而有效的预训练策略,它从现成的冻结参数的图像编码器和冻结参数的大型语言模型中引导视觉语言预训练,在 Image Captioning、VQA、Image-Text Retrieval 任务的多个数据集上取得 SOTA
Introduction
背景
- 由于大规模模型的端到端训练,视觉和语言预训练的成本变得越来越高
- 为了降低计算成本并抵消灾难性遗忘的问题,希望在 Vision-language pre-training (VLP) 中固定视觉模型参数与语言模型参数。然而,由于语言模型在其单模态预训练期间没有看到图像,因此冻结它们使得视觉语言对齐尤其具有挑战性
本文方案
-
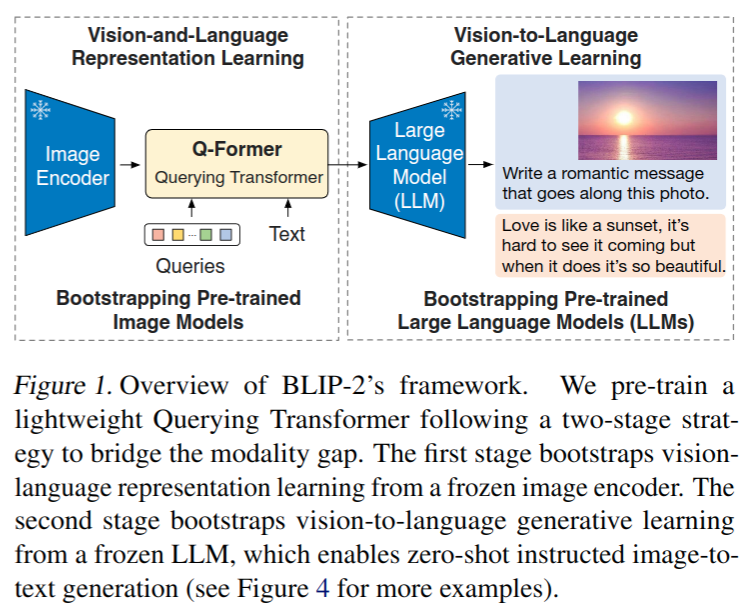
本文提出了BLIP-2,这是一种通用而有效的预训练策略,它从现成的冻结预训练图像编码器和冻结的大型语言模型中引导视觉语言预训练
-
BLIP-2通过一个轻量级的 Querying Transformer (Q-Former是一个轻量级的 transformer,它使用一组可学习的查询向量来从冻结图像编码器中提取视觉特征,为LLM提供最有用的视觉特征,以输出所需的文本) 弥补了模态 gap,该 Transformer 分两个阶段进行预训练
- 第一阶段从冻结图像编码器引导视觉-语言表示学习,强制 Q-Former 学习与文本最相关的视觉表示
- 第二阶段基于冻结的语言模型引导从视觉到语言的生成学习,将Q-Former的输出连接到冻结的LLM,并对Q-Former进行训练,使其输出视觉表示能够被LLM解释
-
BLIP2 优势
- 2stage 训练(表征学习阶段和生成学习阶段)有效利用冻结的预训练图像模型和语言模型,视觉问答、图像字幕和图像文本检索三个任务上取得了 SOTA
- 由 LLM (如 OPT、FlanT5) 提供支持,BLIP-2 可以被提示执行遵循自然语言指令的 zero-shot 图像到文本生成,这实现了诸如视觉知识推理、视觉对话等新兴功能
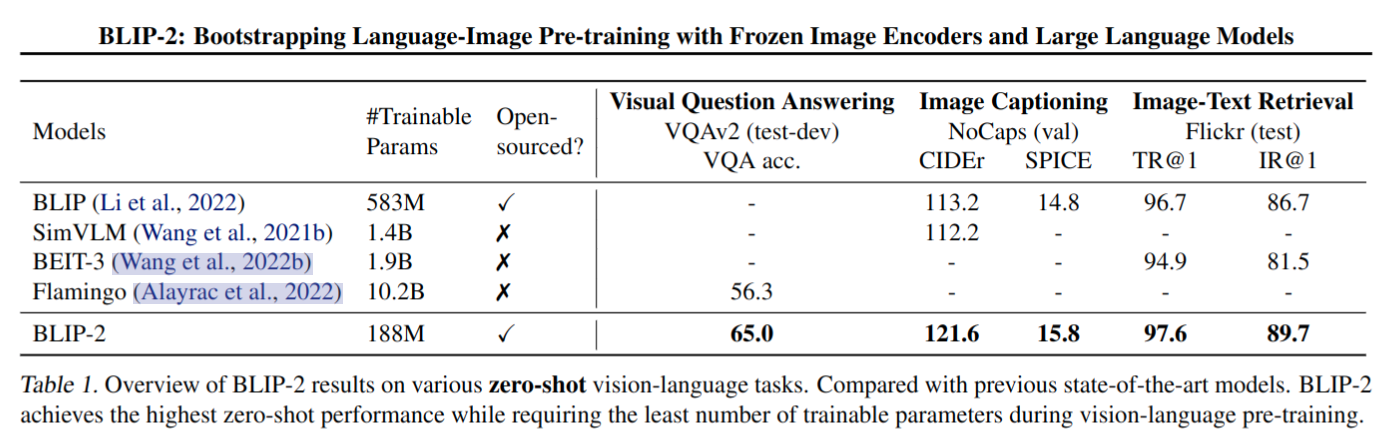
- 由于使用了冻结的单模态模型和轻量级的Q-Former,BLIP-2比现有技术的计算效率更高。比如,BLIP-2 在 zero-shot VQAv2 上比 Flamingo 高 8.7%,可训练参数减少了 54 倍
Dataset/Algorithm/Model/Experiment Detail
实现方式
模型架构
- 提出Q-Former作为可训练模块,以弥合冻结图像编码器和冻结LLM之间的差距。它从图像编码器中提取固定数量的输出特征,与输入图像分辨率无关
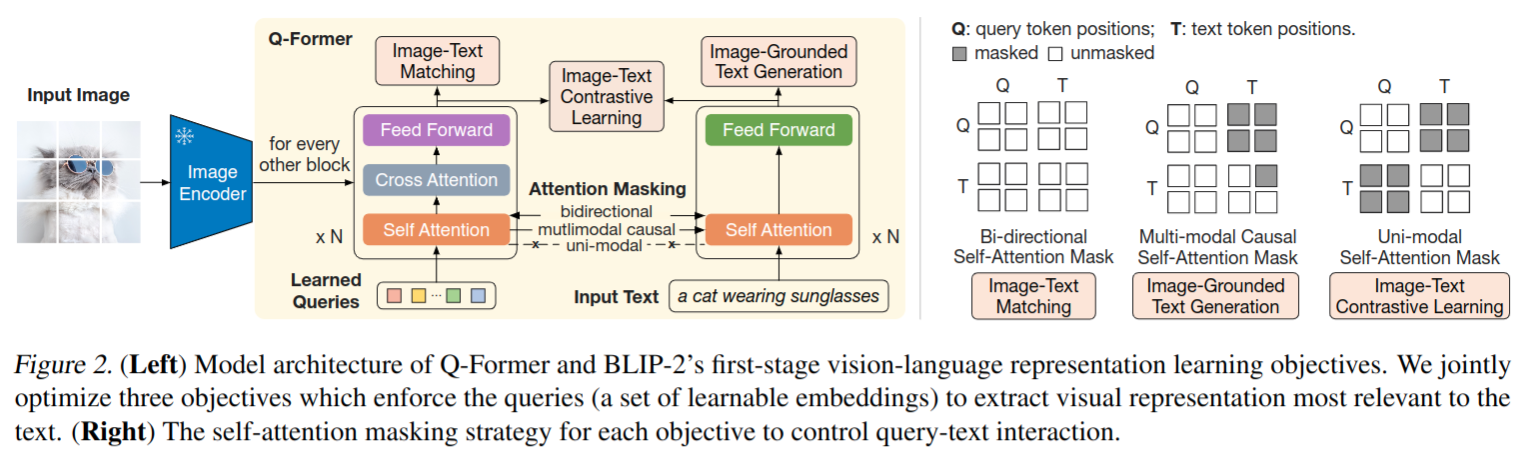
- Q-Former 包含两个共享 self-attention 层的 transformer 模块
- 一种与冻结图像编码器交互的图像 transformer,用于视觉特征提取
- 一种既可以充当文本编码器又可以充当文本解码器的文本转换器
- 通过自关注层相互交互,并通过交叉关注层与冻结图像特征交互,还可以通过相同的 self-attention 层与文本交互。根据预训练任务,应用不同的 self-attention 掩码来控制查询文本交互
- Q-Former 包含 188M 参数,导入 BERTbase pretrain 参数,cross-attention layers 随机初始化,query 维度 32×768 (明显小于图像编码器输出特征维度 257 × 1024)
Bootstrap Vision-Language Representation Learning from a Frozen Image Encoder
- 参考 BLIP,联合优化共享相同输入格式和模型参数的三个预训练目标。每个目标在查询和文本之间采用不同的注意力掩蔽策略来控制它们的交互
- Image-Text Contrastive Learning (ITC)
- 学习对齐图像表示和文本表示,以使它们的相互信息最大化。通过对比正负对的图像-文本相似性来实现这一点
- 为了避免信息泄漏,采用了 unimodal self-attention 掩码,不允许 query 和文本相互查看
- Image-grounded Text Generation (ITG)
- 训练 Q-Former 生成文本,将输入图像作为条件
- 由于 Q-Former 的架构不允许冻结图像编码器和文本 tokens 之间的直接交互,因此生成文本所需的信息必须首先由 query 提取,然后通过 self-attention 传递给文本 tokens。因此,query 被迫提取包含文本所有信息的视觉特征
- 使用 multimodal causal self-attention 掩码来控制 query 与文本交互。query 可以相互关注,但不能关注文本 tokens。每个文本 tokens 都可以处理所有 query 及其以前的文本标记
- Image-Text Matching (ITM)
- 旨在学习图像和文本表示之间的细粒度对齐
- 这是一个二进制分类任务,要求模型预测图像文本对是正(匹配)还是负(不匹配)
- 使用 bi-directional self-attention 掩码,所有查询和文本都可以相互关注。因此,输出的 query embedding 捕获多模态信息
Bootstrap Vision-to-Language Generative Learning from a Frozen LLM
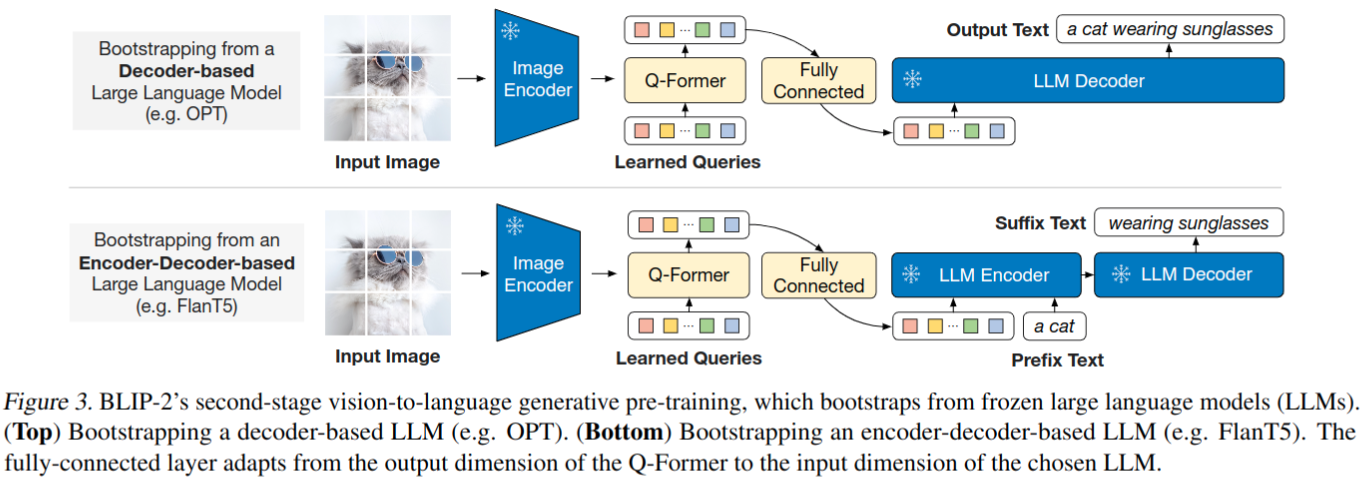
- 在生成预训练阶段,将 QFormer(附带冻结图像编码器)连接到冻结 LLM,以获取LLM 的生成语言能力
- 使用 FC 层将QFormer 输出的 query embedding 线性投影到与 LLM 的文本 embedding 相同的维度。将投影的 query embedding 附加到输入文本 embedding
- 它们用作 soft visual prompts,以 Q-Former 提取的视觉表示为 LLM 提供条件
- 由于 Q-Former 已经有预训练以提取富含语言信息性的视觉表示,因此它有效地充当了一个信息 bottleneck,将最有用的信息提供给 LLM,同时去除不相关的视觉信息,减轻了 LLM 学习视觉语言对齐的负担,从而减轻了灾难性遗忘问题
- 实验两种类型的LLM:基于解码器的LLM和基于编码器-解码器的LLMs
- 对于基于解码的LLM,对语言建模损失进行预训练,其中冻结的LLM的任务是生成基于Q-Former视觉表示的文本
- 对于基于编码器-解码器的LLM,使用前缀语言建模损失进行预训练,将文本分成两部分。前缀文本与视觉表示连接,作为LLM编码器的输入。后缀文本用作LLM解码器编码器的生成目标
模型训练
- pretrain 数据和 BLIP 一样
- 总共 129M 图片,来源于
- COCO
- Visual Genome
- CC3M
- CC12M
- SBU
- LAION400M (115M图片)
- 使用 CapFilt 方法为网络图片合成 caption,也即基于 BLIPlarge 为每张图生成 10 个 captions。基于 CLIP ViT-L/14 模型产生的图像文本相似性,将合成 caption 与原始网络 caption 一起排序。保持每个图像的前两个 caption 作为训练数据,并在每个预训练步骤中随机抽取一个 caption
- Pre-trained image encoder and LLM
- vision transformer:将最后一层删除,使用倒数第二层特征
- ViT-L/14 from CLIP
- ViT-G/14 from EVA-CLIP
- frozen language model
- decoder-based LLMs: unsupervised-trained OPT
- encoder-decoder-based LLMs:instruction-trained FlanT5
- Pre-training settings
- 一阶段训练 250k steps,二阶段训练 80k steps
- 第一阶段对ViT-L/ViT-G使用2320/1680的 batchsize,在第二阶段对OPT/FlanT5使用1920/1520的 batchsize
- 在预训练期间,将冻结的ViTs和LLM参数转换为FP16,但FlanT5除外,使用BFloat16。与 32 bit 模型相比没有精度损失
- 使用一台16-A100(40G)机器,最大型号ViT-G和FlanT5 XXL第一阶段需要不到6天,第二阶段需要不超过3天
实验结果
- 在不同任务上和其他 SOTA 方法对比,开源看起来也是很大优势
Instructed Zero-shot Image-to-Text Generation
- BLIP2 支持通过指令控制图像到文本的生成,只需在视觉提示后附加文本提示作为LLM的输入。下图展示了各种各样的 zero-shot 图像到文本生成功能的示例,包括视觉知识推理、视觉注释推理、视觉对话、个性化图像到文本生成


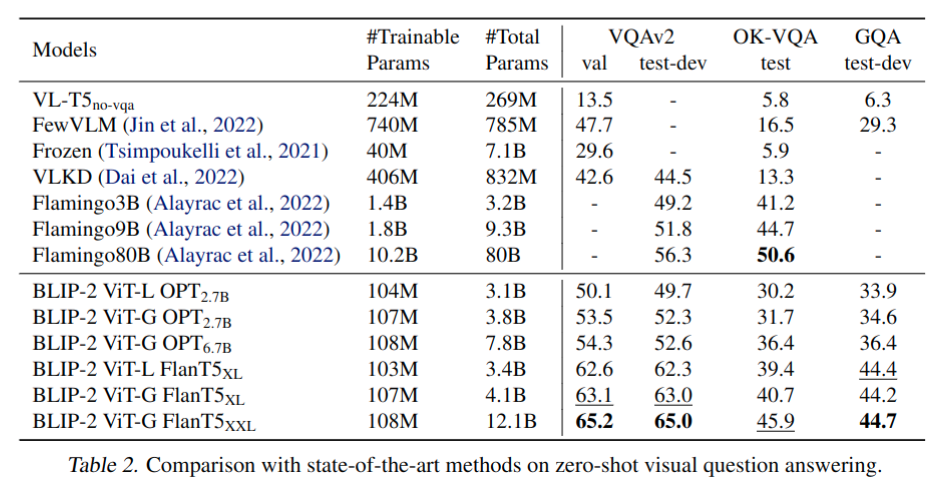
Zero-shot VQA
- 测试方法:
- 对于 OPT 模型,prompt 为 “Question: {} Answer:”;对于 FlanT5 模型,prompt 为 “Question: {} Short answer:”
- 还将长度惩罚设置为-1,这鼓励更短的答案与人类注释更一致
- BLIP2 在 VQAv2 和 GQA 上取得 SOTA 结果,在 OK-VQA 上差于 Flamingo,原因可能是 OK-VQA 更关注开放世界知识,而不是视觉理解,Flamingo80B 中的 70B Chinchilla 语言模型拥有比11B FlanT5XXL 更多的知识。更强的图像编码器或更强的LLM都会带来更好的性能
Vision-Language Representation Learning 的有效性
- 没有一阶段训练明显精度更低,同时 OPT 遭受灾难性遗忘问题,随着训练的进行,性能急剧下降
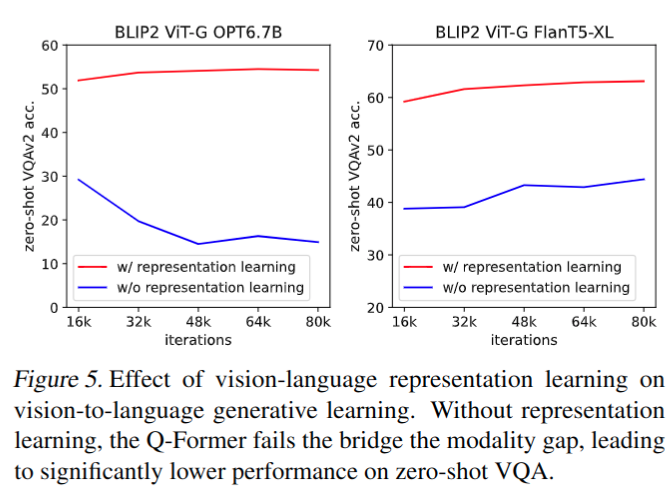
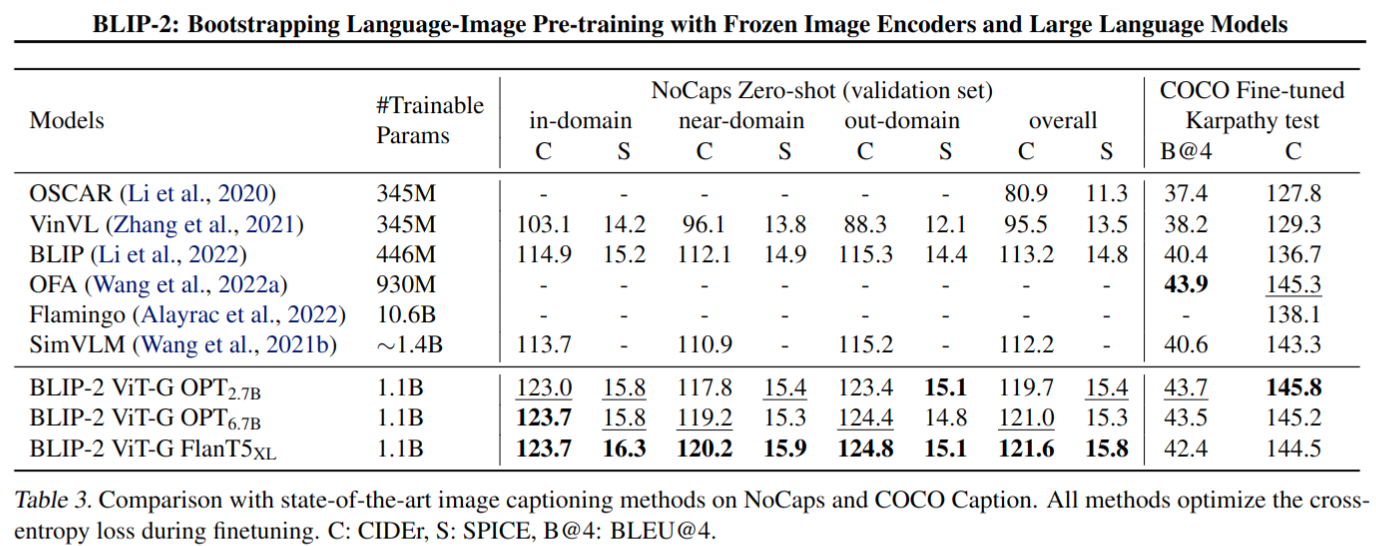
Image Captioning finetune 实验
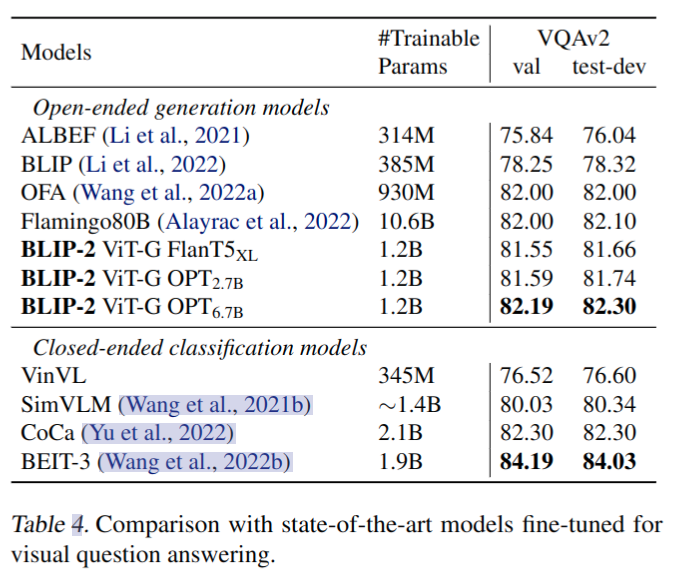
VQA finetune 实验
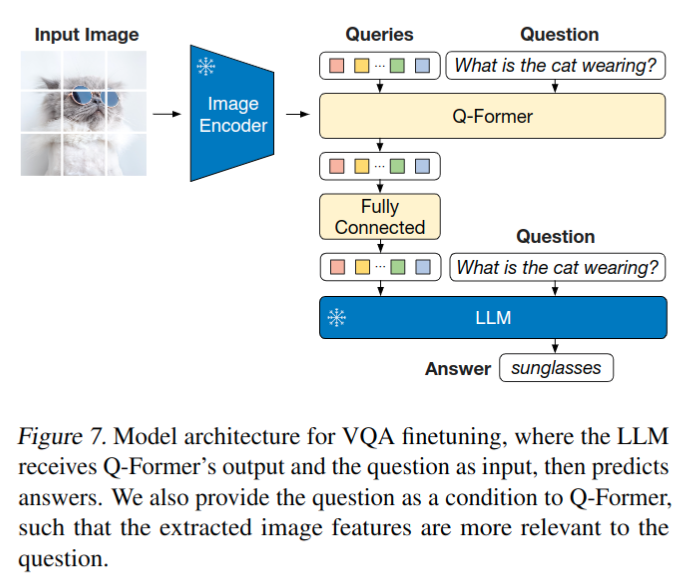
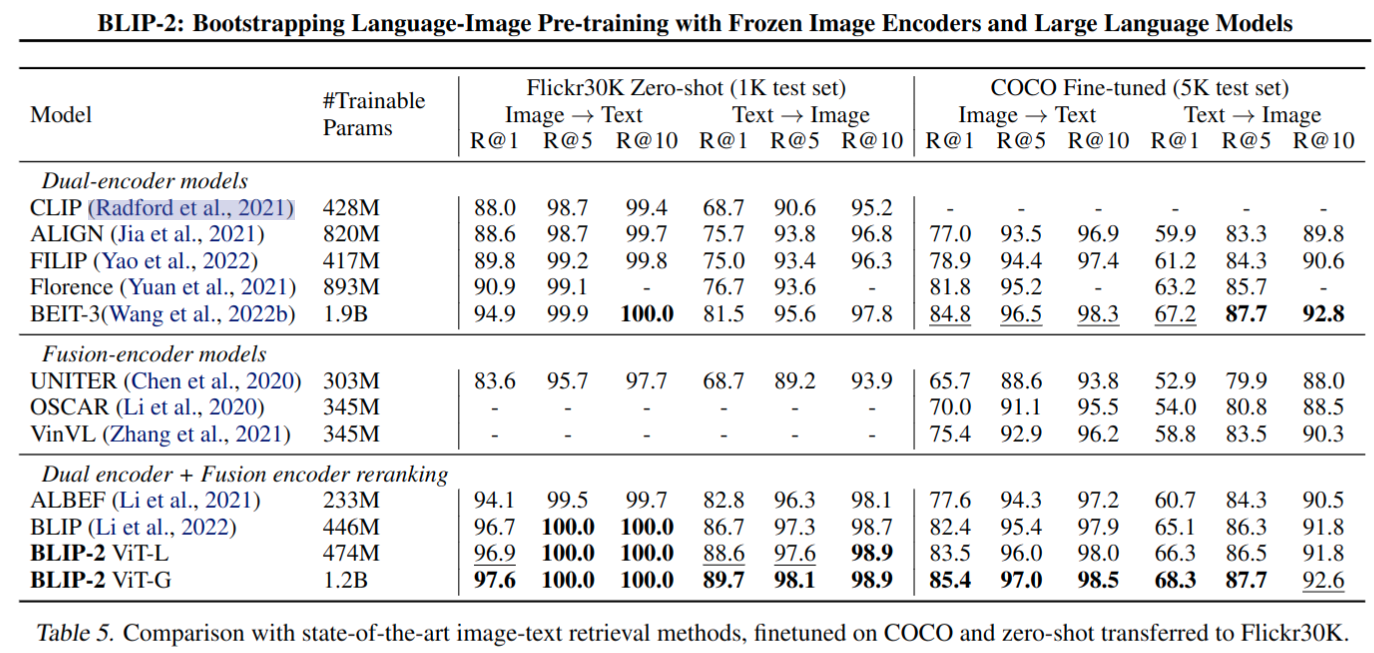
Image-Text Retrieval
- 大部分指标达到 SOTA
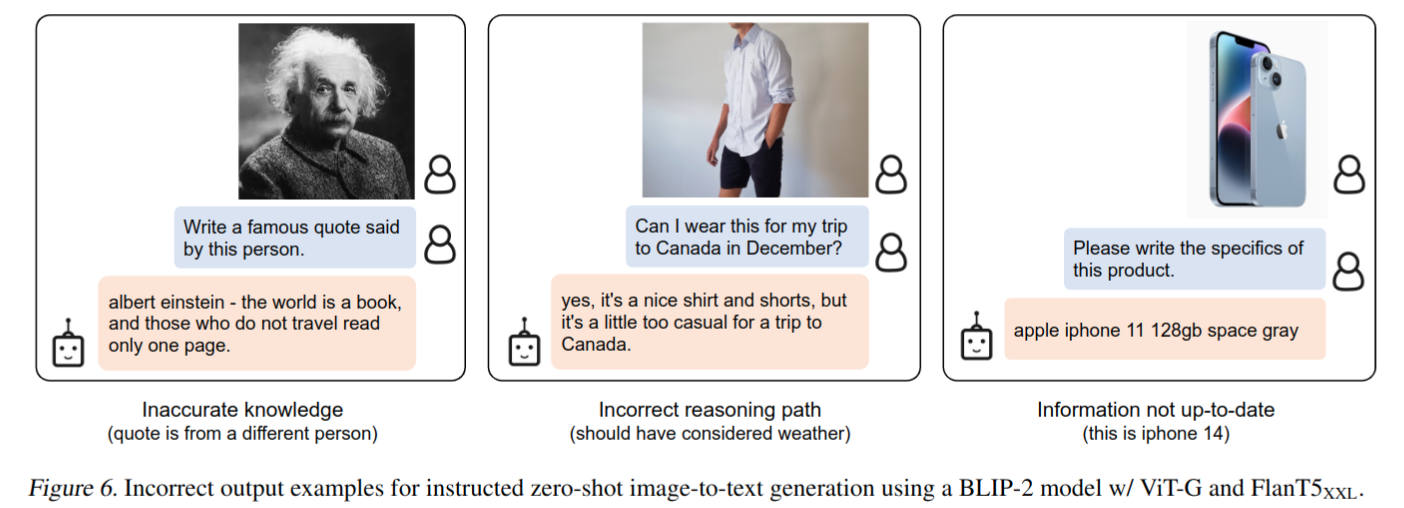
failure cases
Thoughts
- 基于 Q-former 来作为视觉和文本模态的连接模块看起来很合理,有效降低训练的资源消耗
- 文章的 Limitation 中提到,BLIP2 在 VQA 任务中的 in-context learning 效果一般,作者将缺乏上下文学习能力归因于文章使用的预训练数据集:每个样本只包含一个图像-文本对。导致 LLM 无法从中学习单个序列中多个图像文本对之间的相关性。
- Flamingo 为了解决这个问题,使用一个 close-sourced 的交错图像和文本数据集(M3W),每个序列有多个图像-文本对