摘要
本章就开始进入SSD的学习,通过学习这些基础的目标检测算法更好的对比理解其它算法,多看几种代码的写法更容易找到适合自己书写的套路。
ssd网络的6个特征图
ssd采用的是vgg16的特征提取,在vgg16中提取二个特征图,之后又通过额外的增加卷积操作再次提取四个特征图,一种6个特征图。如下图
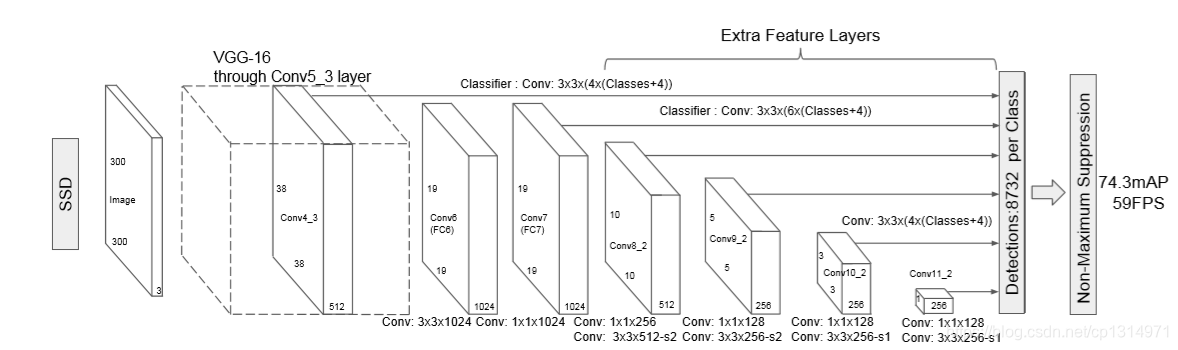
仔细看这里的特征图,第一个输出是(512,38,38)的特征图,这个是在vgg16中的第22层的输出(一共34层包含了relu()所以这么多),第二个输出是(1024,19,19)的特征图输出,这里是vgg最后一层的输出,这里有一个细节,所以先来看vgg的构造
import torch.nn.init as init
import torch
import torch.nn as nn
import torch.nn.functional as F
from torch.autograd import Variable
from math import sqrt as sqrt
from itertools import product as product
base = {
'300': [64, 64, 'M', 128, 128, 'M', 256, 256, 256, 'C', 512, 512, 512, 'M',
512, 512, 512],
'512': [],
}
def vgg(cfg, i, batch_norm=False):
layers = []
in_channels = i
for v in cfg:
if v == 'M':
layers += [nn.MaxPool2d(kernel_size=2, stride=2)]
elif v == 'C':
layers += [nn.MaxPool2d(kernel_size=2, stride=2, ceil_mode=True)]
else:
conv2d = nn.Conv2d(in_channels, v, kernel_size=3, padding=1)
if batch_norm:
layers += [conv2d, nn.BatchNorm2d(v), nn.ReLU(inplace=True)]
else:
layers += [conv2d, nn.ReLU(inplace=True)]
in_channels = v
pool5 = nn.MaxPool2d(kernel_size=3, stride=1, padding=1)
conv6 = nn.Conv2d(512, 1024, kernel_size=3, padding=6, dilation=6)
conv7 = nn.Conv2d(1024, 1024, kernel_size=1)
layers += [pool5, conv6,
nn.ReLU(inplace=True), conv7, nn.ReLU(inplace=True)]
return layers
layers=vgg(base[str(300)], 3)
print(nn.Sequential(*layers))
这部分代码很简单,主要是看下网络构造,网络结构如下
Sequential(
(0): Conv2d(3, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(1): ReLU(inplace)
(2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(3): ReLU(inplace)
(4): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(5): Conv2d(64, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(6): ReLU(inplace)
(7): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(8): ReLU(inplace)
(9): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(10): Conv2d(128, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(11): ReLU(inplace)
(12): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(13): ReLU(inplace)
(14): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(15): ReLU(inplace)
(16): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=True)
(17): Conv2d(256, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(18): ReLU(inplace)
(19): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(20): ReLU(inplace)
(21): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(22): ReLU(inplace)
(23): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(24): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(25): ReLU(inplace)
(26): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(27): ReLU(inplace)
(28): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(29): ReLU(inplace)
(30): MaxPool2d(kernel_size=3, stride=1, padding=1, dilation=1, ceil_mode=False)
(31): Conv2d(512, 1024, kernel_size=(3, 3), stride=(1, 1), padding=(6, 6), dilation=(6, 6))
(32): ReLU(inplace)
(33): Conv2d(1024, 1024, kernel_size=(1, 1), stride=(1, 1))
(34): ReLU(inplace)
)
第一次的特征图输出是在(22)处,一共经历3次池化,所以特征图大小是3838,之后用进行二次maxpool2d 特征图在最后输出应该是1010的大小,但最后一层的maxpool2d的stride=1所以特征图大小还是19在来看看通过增加额外的卷积来输出特征图,
extras = {
'300': [256, 'S', 512, 128, 'S', 256, 128, 256, 128, 256],
'512': [],
}
def add_extras(cfg, i, batch_norm=False):
# Extra layers added to VGG for feature scaling
layers = []
in_channels = i
flag = False
for k, v in enumerate(cfg):
if in_channels != 'S':
if v == 'S':
layers += [nn.Conv2d(in_channels, cfg[k + 1],
kernel_size=(1, 3)[flag], stride=2, padding=1)]
else:
layers += [nn.Conv2d(in_channels, v, kernel_size=(1, 3)[flag])]
flag = not flag
in_channels = v
return layers
add_layer = add_extras(extras[str(300)], 1024)
这部分代码也是直接对比输出理解
Sequential(
(0): Conv2d(1024, 256, kernel_size=(1, 1), stride=(1, 1))
(1): Conv2d(256, 512, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1))
(2): Conv2d(512, 128, kernel_size=(1, 1), stride=(1, 1))
(3): Conv2d(128, 256, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1))
(4): Conv2d(256, 128, kernel_size=(1, 1), stride=(1, 1))
(5): Conv2d(128, 256, kernel_size=(3, 3), stride=(1, 1))
(6): Conv2d(256, 128, kernel_size=(1, 1), stride=(1, 1))
(7): Conv2d(128, 256, kernel_size=(3, 3), stride=(1, 1))
)
构造了7个卷积,通过1,3,5,7卷积之后的特征图用来输出,所以这里提取了4个特征图,加在一起刚好对应图中的6个特征图部分。
6个特征图的代码
import torch.nn.init as init
import torch
import torch.nn as nn
import torch.nn.functional as F
from torch.autograd import Variable
from math import sqrt as sqrt
from itertools import product as product
sources = list()
base = {
'300': [64, 64, 'M', 128, 128, 'M', 256, 256, 256, 'C', 512, 512, 512, 'M',
512, 512, 512],
'512': [],
}
def vgg(cfg, i, batch_norm=False):
layers = []
in_channels = i
for v in cfg:
if v == 'M':
layers += [nn.MaxPool2d(kernel_size=2, stride=2)]
elif v == 'C':
layers += [nn.MaxPool2d(kernel_size=2, stride=2, ceil_mode=True)]
else:
conv2d = nn.Conv2d(in_channels, v, kernel_size=3, padding=1)
if batch_norm:
layers += [conv2d, nn.BatchNorm2d(v), nn.ReLU(inplace=True)]
else:
layers += [conv2d, nn.ReLU(inplace=True)]
in_channels = v
pool5 = nn.MaxPool2d(kernel_size=3, stride=1, padding=1)
conv6 = nn.Conv2d(512, 1024, kernel_size=3, padding=6, dilation=6)
conv7 = nn.Conv2d(1024, 1024, kernel_size=1)
layers += [pool5, conv6,
nn.ReLU(inplace=True), conv7, nn.ReLU(inplace=True)]
return layers
layers=vgg(base[str(300)], 3)
# print(nn.Sequential(*layers))
x=torch.rand(1,3,300,300)
for k in range(23):
x = layers[k](x)
sources.append(x)
print(x.shape)
extras = {
'300': [256, 'S', 512, 128, 'S', 256, 128, 256, 128, 256],
'512': [],
}
def add_extras(cfg, i, batch_norm=False):
# Extra layers added to VGG for feature scaling
layers = []
in_channels = i
flag = False
for k, v in enumerate(cfg):
if in_channels != 'S':
if v == 'S':
layers += [nn.Conv2d(in_channels, cfg[k + 1],
kernel_size=(1, 3)[flag], stride=2, padding=1)]
else:
layers += [nn.Conv2d(in_channels, v, kernel_size=(1, 3)[flag])]
flag = not flag
in_channels = v
return layers
add_layer = add_extras(extras[str(300)], 1024)
# print(nn.Sequential(*add_layer))
x = torch.rand(1,512,38,38)
for k in range(23, len(layers)):
x = layers[k](x)
sources.append(x)
print(x.shape)
x = torch.rand(1,1024,19,19)
for k, v in enumerate(add_layer):
x = F.relu(v(x), inplace=True)
if k % 2 == 1:
print(x.shape)
sources.append(x)
产生所有的框
SSD一共输出6个特征图,在每个特征图的特征值产生的框最少4个,最多6个,一共就产生了8732个框,下面代码是产生框的实现
import torch
from itertools import product as product
from math import sqrt as sqrt
feature_maps=[38, 19, 10, 5, 3, 1]
steps=[8, 16, 32, 64, 100, 300]
aspect_ratios=[[2], [2, 3], [2, 3], [2, 3], [2], [2]]
image_size=300
min_sizes=[30, 60, 111, 162, 213, 264]
max_sizes=[60, 111, 162, 213, 264, 315]
mean = []
for k, f in enumerate(feature_maps): # 6生成个特征图的全部框
for i, j in product(range(f), repeat=2): # 相当于二个for循环,遍历每一个特征图的点
f_k = image_size / steps[k]
# unit center x,y
cx = (j + 0.5) / f_k # 矩阵位置和现实世界的xy刚好相反
cy = (i + 0.5) / f_k
# aspect_ratio: 1
# rel size: min_size
s_k = min_sizes[k] / image_size
mean += [cx, cy, s_k, s_k] # 第一种大小的框产生
# aspect_ratio: 1
# rel size: sqrt(s_k * s_(k+1))
s_k_prime = sqrt(s_k * (max_sizes[k] / image_size))
mean += [cx, cy, s_k_prime, s_k_prime] # 第二种大小的框产生
# rest of aspect ratios
for ar in aspect_ratios[k]: # 这一步要么产生二种大小,要么是四种大小,刚好对应
mean += [cx, cy, s_k * sqrt(ar), s_k / sqrt(ar)]
mean += [cx, cy, s_k / sqrt(ar), s_k * sqrt(ar)]
# back to torch land
output = torch.Tensor(mean).view(-1, 4) #转化成tensor和变换形式一共8732
if 1:
output.clamp_(max=1, min=0)
print(output.shape)
不用太纠结每个框的高和框的大小,每个目标检测都有特有的计算方式,都是通过大量实验所得。