摘要
目前最先进的GNN的自监督学习方法是基于对比学习的,它们严重依赖于图增强和负例。例如,在标准的PPI基准上,增加负对的数量可以提高性能,因此需要的计算和内存成本是节点数量的二次方,这样才能实现最高性能。受BYOL(一种最近引入的不需要负对的自监督学习方法)的启发,我们提出了BGRL,一种自监督图表示方法,可以消除这种潜在的二次瓶颈。BGRL在几个已建立的基准数据集上优于或匹配之前的无监督的最先进的结果。此外,它能够有效地使用图注意力(GAT)编码器,使我们能够进一步提高该技术的技术水平。特别是在PPI数据集上,使用GAT作为编码器,我们使用线性评估协议实现了最先进的70.49%的Micro-F1。在所有考虑的其他数据集上,我们的模型与等价监督GNN结果相比,经常超过它们。
1 引言
BGRL通过使用两个不同的图编码器,一个在线编码器和一个目标编码器,来编码图的两个增强版本,以学习节点表示。在线编码器通过目标编码器的表示的预测来进行训练,而目标编码器被更新为在线网络的指数移动平均值。
主要贡献:
- 时间和空间复杂度最多是线性的边的数量。
- 图的对比方法需要大量的负值才能很好地工作。为了减少时间和存储的复杂性,减少负例数量也会降低一些性能。这意味着对比方法可能需要二次方节点数的时间和空间来达到峰值性能。BGRL通过完全消除负例的需要来避免这些问题。
- 更长的训练时间和归一化层显著提高了自监督学习性能,并提供了许多图数据集的整体性能提高。特别是,我们是第一个在ogbn-arXiv数据集中报告自监督GNN表示结果的人。
2 Bootstrapped Graph Latents (BGRL)
为了在不使用对比目标的情况下实现自监督图表示学习,我们将BYOL适应于图域,并提出了Bootstrapped Graph Latents(BGRL)。就像在BYOL中一样,BGRL通过引导它自己的编码器的延迟版本的输出来学习表示,而不需要定义任何负例。与BYOL处理独立数据点的数据集不同,我们遵循过去的图表示学习方法,并利用图中固有的拓扑结构。
2.1 BGRL组件
形式上,BGRL维持两个图编码器,一个在线编码器
E
θ
\mathcal{E}_θ
Eθ和一个目标编码器
E
ϕ
\mathcal{E}_\phi
Eϕ,其中
θ
θ
θ和
ϕ
\phi
ϕ表示两组不同的参数。
我们考虑了一个图
G
=
(
X
,
A
)
\pmb{G}=(\pmb{X},\pmb{A})
GGG=(XXX,AAA),其节点特征为
X
∈
R
N
×
F
\pmb{X}∈\mathbb{R}^{N×F}
XXX∈RN×F,邻接矩阵为
A
∈
R
N
×
N
A∈\mathbb{R}^{N×N}
A∈RN×N。这里
N
N
N表示图中的节点数,
F
F
F表示特征数。
BGRL首先通过分别应用随机图增强函数
A
1
\mathcal{A}_1
A1和
A
2
\mathcal{A}_2
A2,生成
G
\pmb{G}
GGG的两个备选视图:
G
1
=
(
X
~
1
,
A
~
1
)
\pmb{G}_1=(\tilde{\pmb{X}}_1,\tilde{\pmb{A}}_1)
GGG1=(XXX~1,AAA~1)和
G
2
=
(
X
~
2
,
A
~
2
)
\pmb{G}_2=(\tilde{\pmb{X}}_2,\tilde{\pmb{A}}_2)
GGG2=(XXX~2,AAA~2)。在线编码器从第一个增广图生成一个在线表示,
H
~
1
:
=
E
θ
(
X
~
1
,
A
~
1
)
\tilde{\pmb{H}}_1:=\mathcal{E}_θ(\tilde{\pmb{X}}_1,\tilde{\pmb{A}}_1)
HHH~1:=Eθ(XXX~1,AAA~1);同样,目标编码器生成第二个增广图的目标表示,
H
~
2
:
=
E
ϕ
(
X
~
2
,
A
~
2
)
\tilde{\pmb{H}}_2:=\mathcal{E}_\phi(\tilde{\pmb{X}}_2,\tilde{\pmb{A}}_2)
HHH~2:=Eϕ(XXX~2,AAA~2)。
在线表示被输入一个预测器
p
θ
p_θ
pθ,该
p
θ
p_θ
pθ输出目标表示的预测,
Z
~
1
:
=
p
θ
(
H
~
1
,
A
~
1
)
\tilde{\pmb{Z}}_1:=p_θ(\tilde{\pmb{H}}_1,\tilde{\pmb{A}}_1)
ZZZ~1:=pθ(HHH~1,AAA~1)。除非另有说明,预测器在节点级别工作,而不考虑图信息(即尽在
H
~
1
\tilde{\pmb{H}}_1
HHH~1上操作,而不是
A
~
1
\tilde{\pmb{A}}_1
AAA~1)。
BGRL与BYOL(和其他方法)的不同之处在于,在预测之前,它不使用投影网络将表示投影到更小的空间。BYOL依赖这一点来简化预测器
p
θ
p_θ
pθ的任务,因为直接预测非常高维的嵌入具有挑战性。然而,我们根据经验发现,在常用的图数据集的规模上,这是不需要的,在大多数情况下,由于提供了更间接的学习信号,实际上使学习减慢。
2.2 BGRL更新步骤
2.2.1 更新
θ
θ
θ
在线参数
θ
θ
θ(而非
ϕ
\phi
ϕ)通过遵循余弦相似性的梯度进行更新,以使预测的目标表示
Z
~
1
\tilde{\pmb{Z}}_1
ZZZ~1更接近每个节点的真实目标表示
H
~
2
\tilde{\pmb{H}}_2
HHH~2:
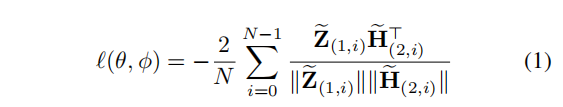
关于
θ
θ
θ,即
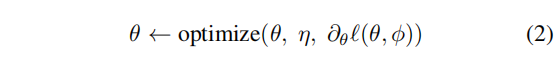
其中,
η
η
η是学习速率,最终的更新是根据目标对
θ
θ
θ的梯度计算出来的,使用SGD或Adam等优化方法。在实践中,我们也通过使用第二个视图的在线表示来预测第一个视图的目标表示来对称化训练。
2.2.2 更新
ϕ
\phi
ϕ
目标参数
ϕ
\phi
ϕ被更新为在线参数
θ
θ
θ的指数移动平均数,即:
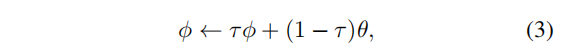
其中
τ
τ
τ是控制
ϕ
\phi
ϕ与
θ
θ
θ保持的距离的衰减速率。
图1直观地总结了BGRL的架构。

2.3 完全非对比的目标
对比方法鼓励不同节点对
(
i
,
j
)
(i,j)
(i,j)的
Z
~
(
1
,
i
)
\tilde{\pmb{Z}}_{(1,i)}
ZZZ~(1,i)和
H
~
(
2
,
j
)
\tilde{\pmb{H}}_{(2,j)}
HHH~(2,j)相距很远。然而,选择这种不同的节点对需要领域知识,而且可能不容易定义。在缺乏选择负例的原则方法时,简单地对比所有对
{
(
i
,
j
)
∣
i
≠
j
}
\{(i,j)|i≠j\}
{(i,j)∣i=j}(如GRACE和GCA所做的),很快会在实际大小的图上遇到内存问题,并且随机采样负例会恶化性能。
由于BGRL完全是非对比性的,它不需要任何负例。表示可以通过预测图中每个节点的表示来直接学习,使用另一个视图中同一节点的表示。BGRL的计算和内存复杂度与边的数量呈线性,而不是像对比方法那样与节点的数量成二次方。此外,与硬挖掘的对比方法相反,BGRL不需要选择哪个节点作为每个节点的负例。
2.4 图增强函数
我们使用术语“增强”,而不是“腐败”,因为我们的目的是产生两个语义上相似的视图。这不同于,例如DGI,它构建了语义上不同的视图,并用来与原始的视图进行对比。
我们考虑了两个简单的图增强函数——节点特征掩蔽和边缘掩蔽。这些增强是图方面的:它们不在每个节点上独立操作,并通过边缘掩蔽利用图的拓扑信息。这与BYOL中使用的转换形成了对比,后者对每个图像独立操作。
首先,我们生成一个大小为
F
F
F的随机二进制掩码,其中每个元素遵循一个伯努利分布
B
(
1
−
p
f
)
\mathcal{B}(1-p_f)
B(1−pf),并使用它来掩蔽图中所有节点的特征(也就是说,所有节点都是相同的特征维度被掩蔽)。
除了这种节点级属性转换之外,我们还计算了一个大小为
E
E
E的二进制掩码(
E
E
E是原始图中的边数),其中每个元素遵循一个伯努利分布
B
(
1
−
p
e
)
\mathcal{B}(1-p_e)
B(1−pe),并使用它来掩蔽增广图中的边。
计算最终的增广图时,每个图的两个增强函数具有不同的超参数,即
p
f
1
p_{f_1}
pf1、
p
e
1
p_{e_1}
pe1为第一个视图,
p
f
2
p_{f_2}
pf2、
p
e
2
p_{e_2}
pe2为第二个视图。
之前的一些工作也研究了自适应增强,使用节点中心性或PageRank中心性等方法来以不同概率掩盖不同边缘。这通过帮助这些转换保持语义相似性,从而提高了增强图的质量。我们只考虑简单的、标准的增强,以便隔离和研究BGRL作为表示学习方法的效果,因为已知更强的增强可以对所学表示的质量产生很大的影响。然而,实验部分显示,我们的方法与使用自适应增强的基线具有竞争力。
3 实验



