1.简介
FP-growth算法主要用于挖掘频繁项集,它只需要遍历两次数据库,因此在大数据集上的速度优于Apriori,通常性能要好两个数量级以上。其发现频繁项集的基本过程如下:
(1)构建FP树
(2)从FP树中挖掘频繁项集
2.构建FP树
2.1.FP树简介
FP是Frequent Pattern的缩写。FP树根节点是空集,每个结点保存单个元素和它在数据集中的出现次数,出现次数越多越接近根节点。相同元素之间又会通过链表连接,方便后续的追溯步骤。
2.2.FP树的构建步骤:
- 扫描数据集,对所有元素项的出现次数进行计数,去掉不满足最小支持度的元素项;
- 对每个集合进行过滤和排序,过滤是去掉不满足最小支持度的元素项,排序基于元素项的绝对出现频率来进行;
- 创建只包含空集合的根节点,将过滤和排序后的每个项集依次添加到树中,如果树中已经存在该路径,则增加对应元素上的值。如果该路径不存在,则创建一条新路径。
2.3.FP树的构建实例
数据集如下:其中每一行是一次记录
| instance id |
elements |
| 1 |
r,z,h,j,p |
| 2 |
z,y,x,w,v,u,t,s |
| 3 |
z |
| 4 |
r,x,n,o,s |
| 5 |
y,r,x,z,q,t,p |
| 6 |
y,z,x,e,q,s,t,m |
step1: 扫描数据集,对所有元素项的出现次数进行计数
| elements |
times |
| r |
3 |
| z |
5 |
| h |
1 |
| j |
1 |
| p |
2 |
| y |
3 |
| x |
4 |
| w |
1 |
| v |
1 |
| u |
1 |
| t |
3 |
| s |
3 |
| n |
1 |
| o |
1 |
| q |
2 |
| e |
1 |
| m |
1 |
step2:去掉不满足最小支持度的元素项
令最小支持度为 0.5,那么将出现次数小于 3 的元素项过滤。
| elements |
times |
| r |
3 |
| z |
5 |
h |
1 |
j |
1 |
p |
2 |
| y |
3 |
| x |
4 |
w |
1 |
v |
1 |
u |
1 |
| t |
3 |
| s |
3 |
n |
1 |
o |
1 |
q |
2 |
e |
1 |
m |
1 |
删除后的结果为
| elements |
times |
| r |
3 |
| z |
5 |
| y |
3 |
| x |
4 |
| t |
3 |
| s |
3 |
step3:降序排列step2所得结果
| elements |
times |
| z |
5 |
| x |
4 |
| y |
3 |
| r |
3 |
| s |
3 |
| t |
3 |
step4:将原数据集过滤支持度过小的元素并按出现次数降序排列
| instance id |
elements |
filter&sort |
| 1 |
r,z,h,j,p
|
z,r |
| 2 |
z,y,x,w,v,u ,t,s |
z,x,y,s,t |
| 3 |
z |
z |
| 4 |
r,x,n,o ,s |
x,s,r |
| 5 |
y,r,x,z,q ,t,p
|
z,x,y,r,t |
| 6 |
y,z,x,e,q ,s,t,m
|
z,x,y,s,t |
step5:每条instance依次添加到FP树中
头结点是空结点,然后每条instance依次添加元素到FP树中,
- 若结点已经存在,频数+1
- 若结点不存在,另辟一条分支,添加该结点,并把频数记为1
例如,
- 从根节点(空集)开始,读入项集 {z, r},为根节点增加一个子节点 z,然后给 z 节点创建一个子节点 r,形成一条 z->r 的路径。
- 接着读入项集 {z, x, y, s, t},z 节点已经存在,那么就从根节点走到 z 节点,然而 z 节点不存在子节点 x,于是创建子节点 x,重复上述过程,直到创建一条 z->x->y->s->t 的路径。
- 接着读入项集 {z},当前项集有存在的路径,于是就不需要创建新路径。
需要注意的是,在遍历路径的过程中,如果现有元素存在,则增加现有元素的值。例如项集 {z, r} 创建 z 节点,并将 z 节点的 频数 设置为 1,接着读入项集 {z, x, y, s, t},由于 z 节点已经存在,那么就为 z 节点的 频数加 1。
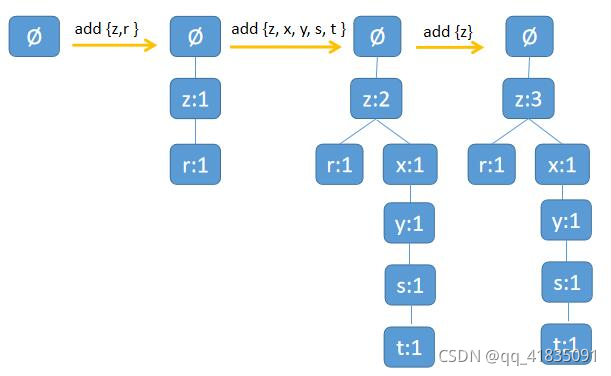
并且从头结点表依次链接
最终构建得到如下的FP树
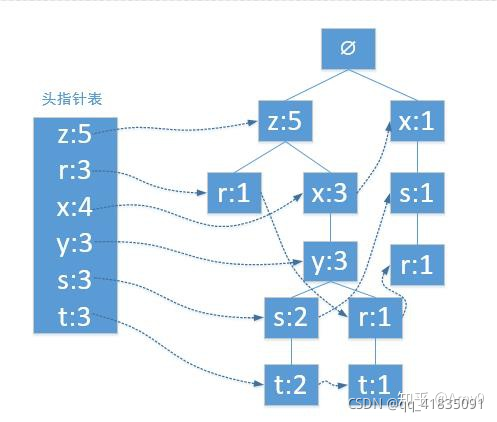
3.从FP树挖掘频繁项集
有了FP树之后,我们就可以来挖掘频繁项集了。这里的思路和Apriori算法大致类似,首先从单元素项集合开始,然后在此基础上逐步构建更大的集合。当然,这里使用的是FP树而不是原始数据集。
条件模式基: 头部链表中的某一点的前缀路径组合就是条件模式基,条件模式基的值取决于末尾节点的值。即条件模式基是以所查找元素项为结尾的路径集合。
3.1.从FP树中挖掘频繁项集的步骤:
- 从FP树中获得条件模式基;
- 利用条件模式基,构建一个条件FP树;
- 迭代:重复上述两个步骤,知道树包含一个元素项为止。
3.2. 1-频繁项集的前缀路径
例如我们要查找元素项 t的前缀路径,头结点链表t追溯到 <t:2>
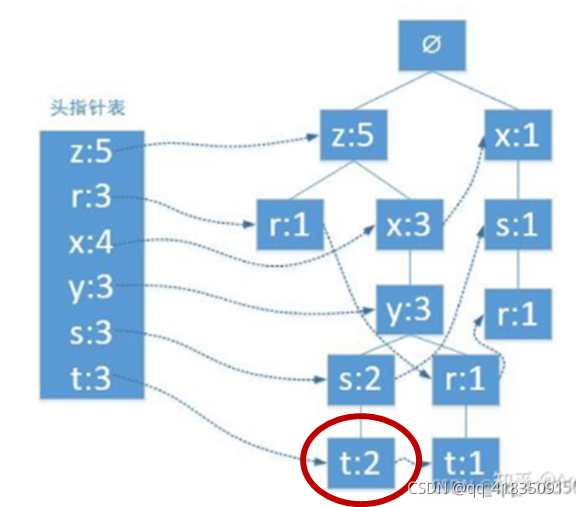
然后继续沿着树向前追溯,即得前缀路径为{z, x, y, s}2,其中2就是当前结点t的值。因为t的出现次数最一个频繁项集的支持度由支持度最小的项决定。所以t节点的条件模式基的值可以理解为对于以t节点为末尾的前缀路径出现次数。
回顾之前统计的频数:
| elements |
times |
| r |
3 |
| z |
5 |
| y |
3 |
| x |
4 |
| t |
3 |
| s |
3 |
下表为1-频繁项的前缀路径
| 频繁项 |
前缀路径 |
| z |
{}5 |
| r |
{x, s}1, {z, x, yy}1, {z}1 |
| x |
{z}3, {}1 |
| y |
{z, x}3 |
| s |
{z, x, y}2, {x}1 |
| t |
{z, x, y, s}2, {z, x, y, r}1 |
3.3. 创建条件FP树
-
条件FP树:以条件模式基作为数据集构造的FP树叫做条件FP树。
对于每一个频繁项,都要创建一棵条件 FP 树。可以使用上一步发现的条件模式基作为输入数据,并通过相同的构建 FP 树的相同的步骤来构建条件 FP 树。然后,我们会递归地发现频繁项、发现条件模式基,以及发现另外的条件树。递归遍历头部链表生成FP树的过程,递归截止条件是生成的FP树的头部链表为空。
假定为频繁项 t 创建一个条件 FP 树,最小支持度为0.5(频数为 3)。根据3.2.得到的 1-频繁项的前缀路径,可知 t 的前缀路径为 {z, x, y, s}2, {z, x, y, r}1。
- 因为最小支持度的频数为 3,所以 {z, x, y, s} 和 {z, x, y, r} 都不满足条件,分别去掉 s 和 r。(因为s只出现在第一个前缀路径中,故频数为2,2<3 去掉;同理r只出现在第二个条件模式基中,频数为1,1<3 去掉;而z x y均出现在两个条件模式基中,频数为1+2=3,故保留)
- 去掉 s 和 r 后发现,这两条前缀路径重合了,{z, x, y} 的计数值变为 3,即满足条件。根据 Apriori 原理,频繁项集的超集自然也是频繁项集。
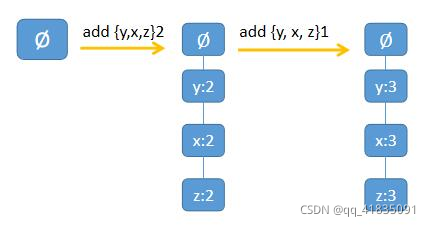
链接头结点表:
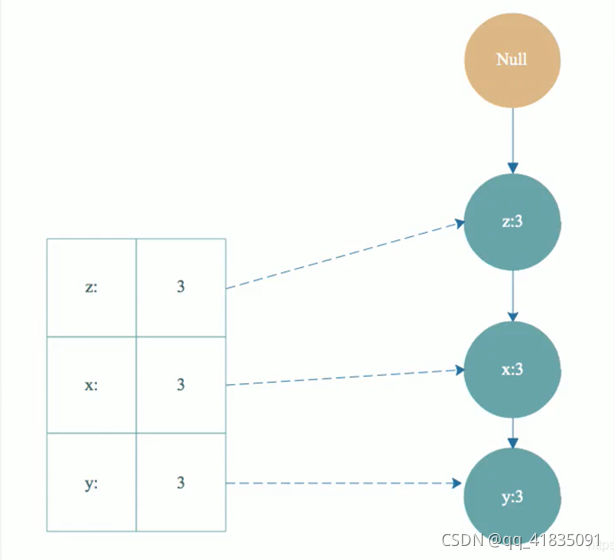
然后根据t-条件FP树的头部链表进行遍历,从y开始。得到频繁项集ty。然后又得到y的条件模式基{z, x}3,构造出ty的条件FP树,即ty-条件FP树。

继续遍历ty-条件FP树的头部链表,得到频繁项集tyx,然后又得到频繁项集tyxz. 最后得到构造tyxz条件FP树的头部链表是空的,终止遍历。我们得到的频繁项集有t->ty->tyz->tyzx,这只是一小部分。
依次类推(t的条件模式基重复上述步骤,s的条件模式基重复上述步骤,y的条件模式基重复上述步骤……)
关于条件模式基的生成和频繁项集挖掘的具体操作,见:
传送门

最终得到所有的频繁项集:
[{‘r’},
{‘s’}, {‘x’, ‘s’},
{‘y’}, {‘y’, ‘z’}, {‘y’, ‘z’, ‘x’}, {‘y’, ‘x’},
{‘t’},{‘y’, ‘t’},{‘y’, ‘z’, ‘t’},{‘y’, ‘z’, ‘x’, ‘t’},
\space
\space
\space
{‘x’, ‘t’}, {‘y’, ‘x’, ‘t’}, {‘z’, ‘t’}, {‘z’, ‘x’, ‘t’},
{‘x’}, {‘z’, ‘x’},
{‘z’}]
参考文献
- 《机器学习实战》Peter Harrington著
- https://blog.csdn.net/qs17809259715/article/details/100023061
- https://blog.csdn.net/weixin_43378396/article/details/89606982
- https://zhuanlan.zhihu.com/p/117598874
- https://blog.csdn.net/huagong_adu/article/details/17739247?ops_request_misc=%257B%2522request%255Fid%2522%253A%2522163150089916780357212252%2522%252C%2522scm%2522%253A%252220140713.130102334.pc%255Fall.%2522%257D&request_id=163150089916780357212252&biz_id=0&utm_medium=distribute.pc_search_result.none-task-blog-2allfirst_rank_ecpm_v1~hot_rank-3-17739247.first_rank_v2_pc_rank_v29&utm_term=fp+growth&spm=1018.2226.3001.4187
- https://www.cnblogs.com/pinard/p/6307064.html