一、 概述
BP-GA算法的设计︰基于遗传算法的BP神经网络算法(以下简称BP-GA)就是在BP神经网络的学习过程中,将权重和阀值描述为染色体,并选取适宜的适应函数,然后进行GA迭代,直到某种意义上的收敛.与普通BP学习算法相比,算法 BP一GA的优势在于可以处理一些传统方法不能处理的例子,例如不可导的特性函数(传递函数)或者没有梯度信息存在的节点.该算法涉及到两个关键问题,分别是染色体位串与权系值的编码映射和评价函数。




二、运行结果
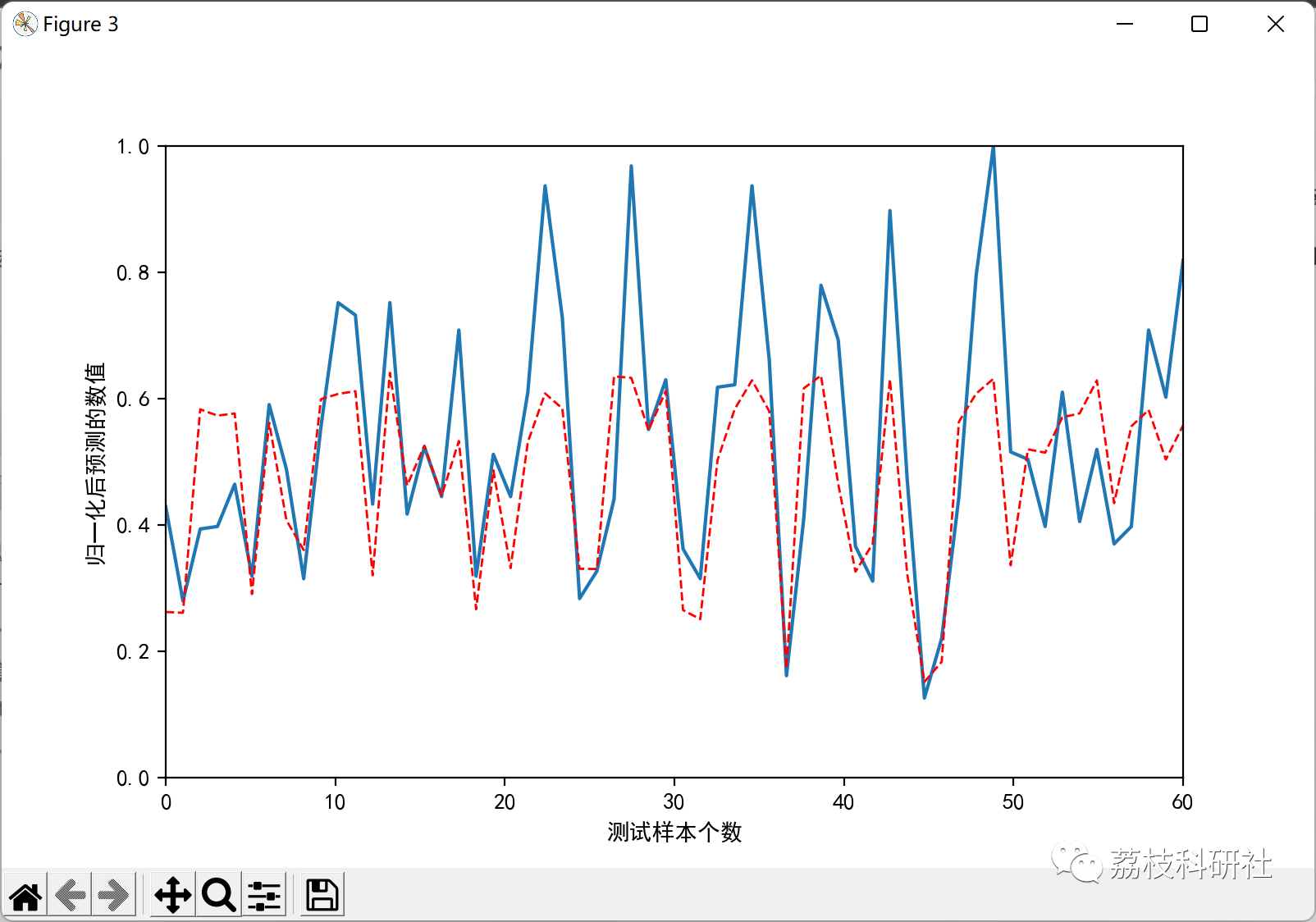
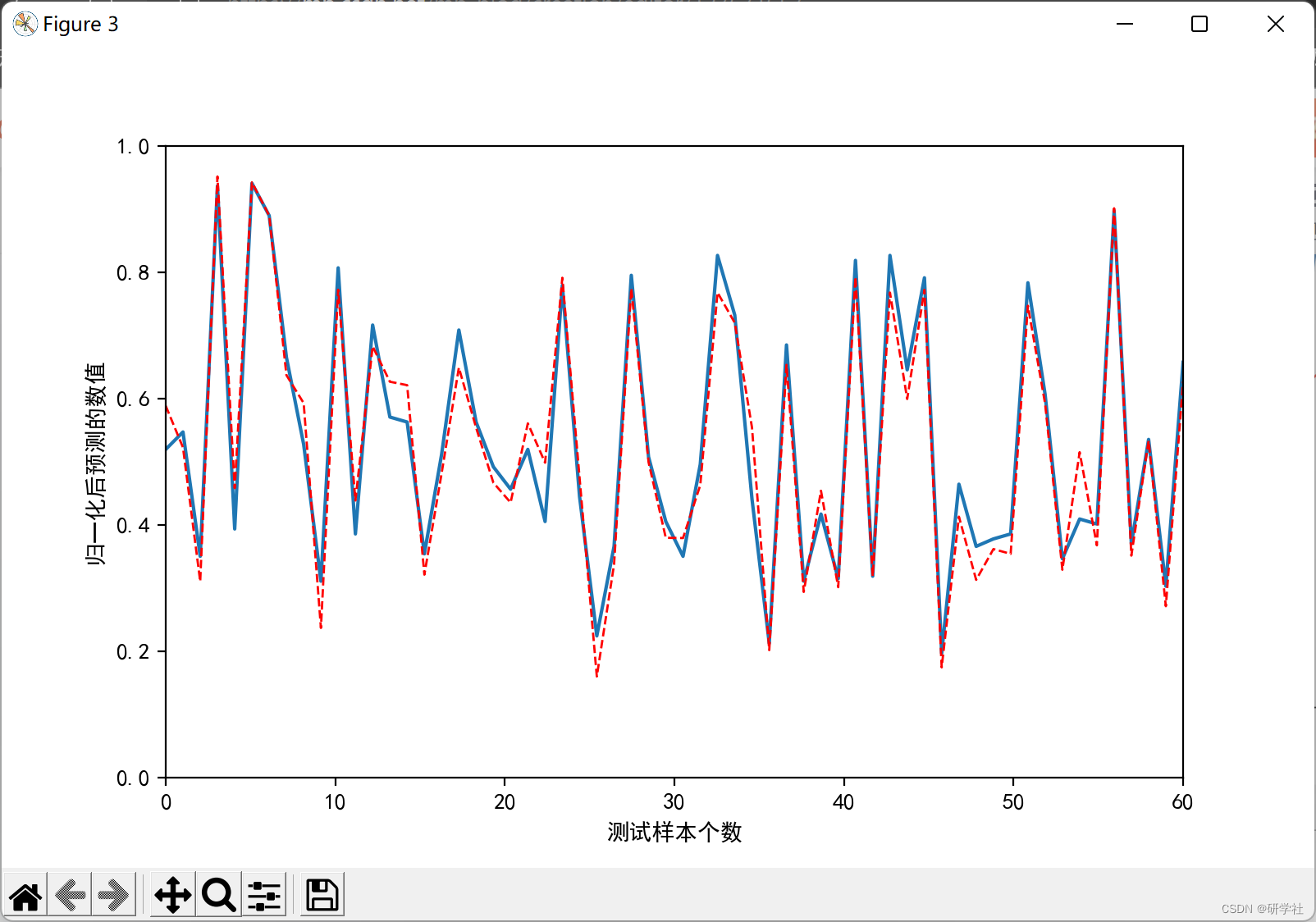
部分代码:
def load_data_wrapper(filename):
lineData = []
with open(filename) as txtData:
lines = txtData.readlines()
for line in lines:
linedata = line.strip().split(',')
lineData.append(linedata)
return lineData
# 提出特征和标签,特征做输入,标签为输出
def splitData(dataset):
Character= []
Label = []
for i in range(len(dataset)):
Character.append([float(tk) for tk in dataset[i][1:-1]])
Label.append(float(dataset[i][-1]))
return Character, Label
#输入特征数据归一化
def max_min_norm_x(dataset):
min_data = []
for i in range(len(dataset)):
min_data.append(min(dataset[i]))
new_min = min(min_data)
max_data = []
for i in range(len(dataset)):
max_data.append(max(dataset[i]))
new_max = max(max_data)
data = np.array(dataset)
data_x =[]
for x in np.nditer(data, op_flags=['readwrite']):
#x[...] = 2 * (x -new_min)/(new_max-new_min)-1
x[...] = (x - new_min) / (new_max - new_min)
#print('x[...]:',x[...])
data_x.append(x[...])
data_x3 = []
for index in range(0, len(data_x), 3):
data_x3.append([data_x[index], data_x[index+1], data_x[index+2]])
#print("data_x3:",data_x3)
return data_x3
def load_data_wrapper(filename):
lineData = []
with open(filename) as txtData:
lines = txtData.readlines()
for line in lines:
linedata = line.strip().split(',')
lineData.append(linedata)
return lineData
# 提出特征和标签,特征做输入,标签为输出
def splitData(dataset):
Character= []
Label = []
for i in range(len(dataset)):
Character.append([float(tk) for tk in dataset[i][1:-1]])
Label.append(float(dataset[i][-1]))
return Character, Label
#输入特征数据归一化
def max_min_norm_x(dataset):
min_data = []
for i in range(len(dataset)):
min_data.append(min(dataset[i]))
new_min = min(min_data)
max_data = []
for i in range(len(dataset)):
max_data.append(max(dataset[i]))
new_max = max(max_data)
data = np.array(dataset)
data_x =[]
for x in np.nditer(data, op_flags=['readwrite']):
#x[...] = 2 * (x -new_min)/(new_max-new_min)-1
x[...] = (x - new_min) / (new_max - new_min)
#print('x[...]:',x[...])
data_x.append(x[...])
data_x3 = []
for index in range(0, len(data_x), 3):
data_x3.append([data_x[index], data_x[index+1], data_x[index+2]])
#print("data_x3:",data_x3)
return data_x3
def load_data_wrapper(filename): lineData = [] with open(filename) as txtData: lines = txtData.readlines() for line in lines: linedata = line.strip().split(',') lineData.append(linedata) return lineData # 提出特征和标签,特征做输入,标签为输出 def splitData(dataset): Character= [] Label = [] for i in range(len(dataset)): Character.append([float(tk) for tk in dataset[i][1:-1]]) Label.append(float(dataset[i][-1])) return Character, Label #输入特征数据归一化 def max_min_norm_x(dataset): min_data = [] for i in range(len(dataset)): min_data.append(min(dataset[i])) new_min = min(min_data) max_data = [] for i in range(len(dataset)): max_data.append(max(dataset[i])) new_max = max(max_data) data = np.array(dataset) data_x =[] for x in np.nditer(data, op_flags=['readwrite']): #x[...] = 2 * (x -new_min)/(new_max-new_min)-1 x[...] = (x - new_min) / (new_max - new_min) #print('x[...]:',x[...]) data_x.append(x[...]) data_x3 = [] for index in range(0, len(data_x), 3): data_x3.append([data_x[index], data_x[index+1], data_x[index+2]]) #print("data_x3:",data_x3) return data_x3
def load_data_wrapper(filename): lineData = [] with open(filename) as txtData: lines = txtData.readlines() for line in lines: linedata = line.strip().split(',') lineData.append(linedata) return lineData # 提出特征和标签,特征做输入,标签为输出 def splitData(dataset): Character= [] Label = [] for i in range(len(dataset)): Character.append([float(tk) for tk in dataset[i][1:-1]]) Label.append(float(dataset[i][-1])) return Character, Label #输入特征数据归一化 def max_min_norm_x(dataset): min_data = [] for i in range(len(dataset)): min_data.append(min(dataset[i])) new_min = min(min_data) max_data = [] for i in range(len(dataset)): max_data.append(max(dataset[i])) new_max = max(max_data) data = np.array(dataset) data_x =[] for x in np.nditer(data, op_flags=['readwrite']): #x[...] = 2 * (x -new_min)/(new_max-new_min)-1 x[...] = (x - new_min) / (new_max - new_min) #print('x[...]:',x[...]) data_x.append(x[...]) data_x3 = [] for index in range(0, len(data_x), 3): data_x3.append([data_x[index], data_x[index+1], data_x[index+2]]) #print("data_x3:",data_x3) return data_x3
完整代码:回复关键字
三、 参考文献
[1]王崇骏,于汶滌,陈兆乾,谢俊元.一种基于遗传算法的BP神经网络算法及其应用[J].南京大学学报:自然科学版,2003,39(5):459-466
[2]潘昊,王晓勇,陈琼,黄少銮.基于遗传算法的BP神经网络技术的应用[J].计算机应用,2005,25(12):2777-2779
四、 Python代码实现