xml格式可视化
这里分了两类
(1)目标被标注为正矩形,即(xmin,ymin),(xmax,ymax),一般的voc数据类型都是这种标注形式
(2)目标被标注为具有一定旋转角度的矩形,即(x1,y1),(x2,y2),(x3,y3),(x4,y4),DOTA数据集就是这样的标注形式
import cv2
import os
import numpy as np
import xml.dom.minidom
from xml.dom.minidom import Document
import sys
stdi, stdo, stde = sys.stdin, sys.stdout, sys.stderr
reload(sys)
sys.setdefaultencoding('utf-8')
sys.stdin, sys.stdout, sys.stderr = stdi, stdo, stde
def custombasename(fullname):
return os.path.basename(os.path.splitext(fullname)[0])
def GetFileFromThisRootDir(dir,ext = None):
allfiles = []
needExtFilter = (ext != None)
for root,dirs,files in os.walk(dir):
for filespath in files:
filepath = os.path.join(root, filespath)
extension = os.path.splitext(filepath)[1][1:]
if needExtFilter and extension in ext:
allfiles.append(filepath)
elif not needExtFilter:
allfiles.append(filepath)
return allfiles
def readXml(xmlfile, hbb = True):
DomTree = xml.dom.minidom.parse(xmlfile)
annotation = DomTree.documentElement
imgnamelist = annotation.getElementsByTagName('filename')
img_name = imgnamelist[0].childNodes[0].data #图片的名称
sizelist = annotation.getElementsByTagName('size') #[<DOM Element: filename at 0x381f788>]
heights = sizelist[0].getElementsByTagName('height')
height = int(heights[0].childNodes[0].data)
widths =sizelist[0].getElementsByTagName('width')
width = int(widths[0].childNodes[0].data)
depths = sizelist[0].getElementsByTagName('depth')
depth = int(depths[0].childNodes[0].data)
objectlist = annotation.getElementsByTagName('object')
bboxes = []
for objects in objectlist:
namelist = objects.getElementsByTagName('name')
class_label = namelist[0].childNodes[0].data
bndbox = objects.getElementsByTagName('bndbox')[0]
if hbb:
xmin_list = bndbox.getElementsByTagName('xmin')
xmin = int(float(xmin_list[0].childNodes[0].data))
ymin_list = bndbox.getElementsByTagName('ymin')
ymin = int(float(ymin_list[0].childNodes[0].data))
xmax_list = bndbox.getElementsByTagName('xmax')
xmax = int(float(xmax_list[0].childNodes[0].data))
ymax_list = bndbox.getElementsByTagName('ymax')
ymax = int(float(ymax_list[0].childNodes[0].data))
bbox = [xmin, ymin, xmax, ymax,class_label]
bboxes.append(bbox)
else:
x0_list = bndbox.getElementsByTagName('x0')
x0 = int(float(x0_list[0].childNodes[0].data))
y0_list = bndbox.getElementsByTagName('y0')
y0 = int(float(y0_list[0].childNodes[0].data))
x1_list = bndbox.getElementsByTagName('x1')
x1 = int(float(x1_list[0].childNodes[0].data))
y1_list = bndbox.getElementsByTagName('y1')
y1 = int(float(y1_list[0].childNodes[0].data))
x2_list = bndbox.getElementsByTagName('x2')
x2 = int(float(x2_list[0].childNodes[0].data))
y2_list = bndbox.getElementsByTagName('y2')
y2 = int(float(y2_list[0].childNodes[0].data))
x3_list = bndbox.getElementsByTagName('x3')
x3 = int(float(x3_list[0].childNodes[0].data))
y3_list = bndbox.getElementsByTagName('y3')
y3 = int(float(y3_list[0].childNodes[0].data))
bbox = [x0,y0,x1,y1,x2,y2,x3,y3,class_label]
bboxes.append(bbox)
return bboxes,width,height,depth,img_name
def visualise_gt(label_path, pic_path, newpic_path, hbb = True):
results = GetFileFromThisRootDir(label_path)
font = cv2.FONT_HERSHEY_SIMPLEX #字体
for result in results:
[boxes, w, h, d, imgname] = readXml(result, hbb)
filepath=os.path.join(pic_path, imgname)
im=cv2.imread(filepath)
for i in range(len(boxes)):
if hbb:
cv2.rectangle(im,(boxes[i][0],boxes[i][1]),(boxes[i][2],boxes[i][3]), (0,255,255), 2)
else:
box =np.array( [[boxes[i][0],boxes[i][1]],[boxes[i][2],boxes[i][3]], \
[boxes[i][4],boxes[i][5]],[boxes[i][6],boxes[i][7]]],np.int32)
cv2.polylines(im,[box], True, (0,255,255),2) #true表示闭合
#书写标签
cv2.rectangle(im, (boxes[i][0], boxes[i][1]-15), (boxes[i][0] +65 ,boxes[i][1] -2), (255, 0, 0), thickness=-1) # thickness表示线的粗细,等于-1表示填充,颜色为(255, 0, 0)
cv2.putText(im, boxes[i][-1], (boxes[i][0], boxes[i][1]-2), font, 0.7, (255, 255, 255), 1) #0.5是字体大小,2是字体的粗细
cv2.imwrite(os.path.join(newpic_path,imgname),im)
print('已完成',result)
if __name__ == '__main__':
root='/home/yantianwang/clone/haha'
pic_path = os.path.join(root, 'images') #样本图片路径
label_path = os.path.join(root, 'xml') #xml文件所在路径
newpic_path=os.path.join(root,'visgt') #可视化结果的保存路径
if not os.path.isdir(newpic_path):
os.makedirs(newpic_path)
visualise_gt(label_path, pic_path, newpic_path, hbb = True) #默认是hbb
可视化结果:
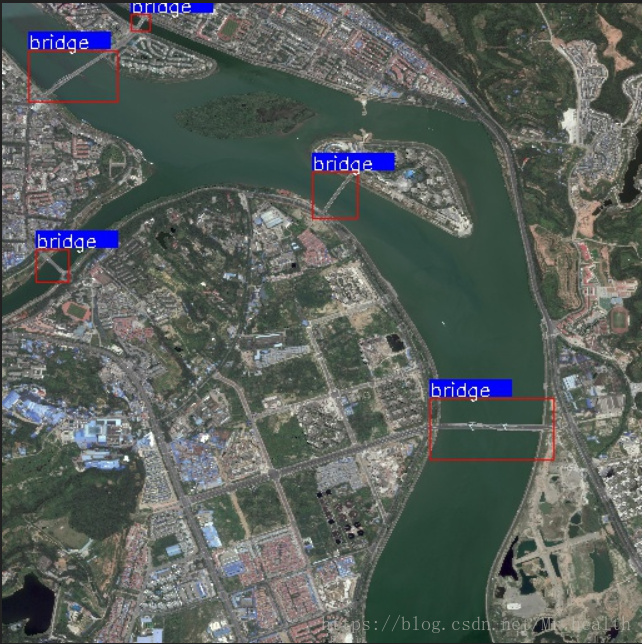
DOTA数据格式可视化
import cv2
import os
import numpy as np
thr=0.95
def custombasename(fullname):
return os.path.basename(os.path.splitext(fullname)[0])
def GetFileFromThisRootDir(dir,ext = None):
allfiles = []
needExtFilter = (ext != None)
for root,dirs,files in os.walk(dir):
for filespath in files:
filepath = os.path.join(root, filespath)
extension = os.path.splitext(filepath)[1][1:]
if needExtFilter and extension in ext:
allfiles.append(filepath)
elif not needExtFilter:
allfiles.append(filepath)
return allfiles
def visualise_gt(label_path, pic_path, newpic_path):
results = GetFileFromThisRootDir(label_path)
for result in results:
f = open(result,'r')
lines = f.readlines()
if len(lines)==0: #如果为空
print('文件为空',result)
continue
boxes = []
for i,line in enumerate(lines):
#score = float(line.strip().split(' ')[8])
if i in [0,1]: #前两行不需要
continue
name = result.split('/')[-1]
box=line.strip().split(' ')[0:8]
box = np.array(box,dtype = np.float)
#if float(score)>thr:
boxes.append(box)
boxes = np.array(boxes,np.float)
f.close()
filepath=os.path.join(pic_path, name.split('.')[0]+'.tif')
im=cv2.imread(filepath)
#print line3
for i in range(boxes.shape[0]):
box =np.array( [[boxes[i][0],boxes[i][1]],[boxes[i][2],boxes[i][3]], \
[boxes[i][4],boxes[i][5]],[boxes[i][6],boxes[i][7]]],np.int32)
box = box.reshape((-1,1,2))
cv2.polylines(im,[box],True,(0,255,255),2)
cv2.imwrite(os.path.join(newpic_path,result.split('/')[-1].split('.')[0]+'.tif'),im)
#下面是有score的
# x,y,w,h,score=box.split('_')#
# score=float(score)
# cv2.rectangle(im,(int(x),int(y)),(int(x)+int(w),int(y)+int(h)),(0,0,255),1)
# cv2.putText(im,'%3f'%score, (int(x)+int(w),int(y)+int(h)+5),cv2.FONT_HERSHEY_SIMPLEX,0.5,(0,255,0),1)
# cv2.imwrite(newpic_path+filename,im)
if __name__ == '__main__':
root='/home/yantianwang/lala/ship/train/'
pic_path = os.path.join(root, 'images') #样本图片路径
label_path = os.path.join(root, 'labelTxt') #DOTA标签的所在路径
newpic_path=os.path.join(root,'hbbshow') #可视化保存路径
if not os.path.isdir(newpic_path):
os.makedirs(newpic_path)
visualise_gt(label_path, pic_path, newpic_path)