一、综述
由于工作中很长一段时间都是在做语义分割系列的工作,所以这篇文章主要对自己用到的一些方法做个简单的总结,包括其优缺点等,以便日后能够及时复习查看。
目前语义分割的方法主要集中在两个大的结构上:1、encode-decode的结构:图像通过encode阶段进行特征抽取,decode则负责将抽取到的信息进行对应的分类复位;2、dialted convolutional结构,这种结构抛弃了pool层而采用了空洞卷积(dilated convolutional layers)进行代替,能够起到增加感受野的作用。
所以本文将会按照时间顺序来分别对FCN、SetNet、U-Net、DeepLab V1 (and V2)、RefineNet、PSPNet、DeepLab V3、DeepLab V3+等这几个典型的网络结构作分析。
二、 网络结构
1)FCN
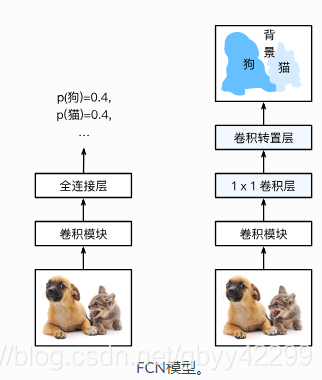
分类网络的分类层通常会在最后连接全连接层,它会将前面层卷积提取到的二维特征的矩阵压缩成一维的,从而丢失了空间信息,最后训练输出一个标量,用来分类。而FCN 的核心思想是将一个卷积网络的最后全连接输出层替换成转置卷积层来获取对每个输入像素的预测。具体来说,它去掉了过于损失空间信息的全局池化层,并将最后的全连接层替换成输出通道是原全连接层输出大小的 1×1 卷积层,最后接上转置卷积层来得到需要形状的输出。
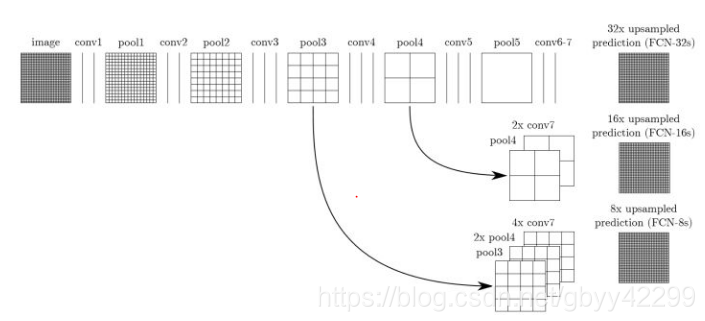
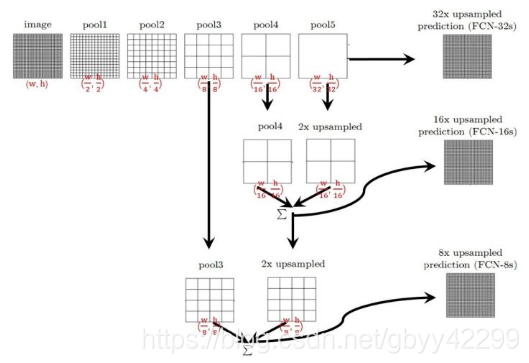
如上图所示,即为FCN的网络结构图,为了便于理解,我在mxnet的网站找了一张比较形象的图来解释一下这个网络结构,如下图:
FCN的结构就是将VGG16中的fc6和fc7都换成卷积,然后经过conv_transpose进行还原扩大,而FCN-8s和FCN-16s则是结合了前面pooling层的输出,然后进行element wise(对应值相加),然后输出。
- FCN-32s:直接对pool5 feature进行32倍上采样获得32x upsampled feature,再对32x upsampled feature每个点做softmax prediction获得32x upsampled feature prediction(即分割图)。
- FCN-16s:首先对pool5 feature进行2倍上采样获得2x upsampled feature,再把pool4 feature和2x upsampled feature逐点相加,然后对相加的feature进行16倍上采样,并softmax prediction,获得16x upsampled feature prediction。
- FCN-8s,首先进行pool4+2x upsampled feature逐点相加,然后又进行pool3+2x upsampled逐点相加,即进行更多次特征融合。具体过程与16s类似.
根据上面三种不同的connect对比可知:使用多层feature融合有利于提高分割准确性。即:准确率FCN-32s < FCN-16s < FCN-8。
难点:作者开源了代码,但是细细度过后就会发现有几个比较奇怪的难以理解的点,我写出来如下:
1、作者在conv1_1中采用的padding=100,为什么呢?

为什么需要padding=100呢?
因为作者为了保证输出的尺寸不至于太小,所以对第一层进行了padding。当然了还有的做法就是可以减少池化的层,但是这样做会带来的问题就是原先的网络结构不可用了,也就没办法fine-tune了。当然了还有一种比较好的办法就是想deeplab那样,将pooling的stride改为1,padding=1,这样之后池化并没有带来图片尺寸的减少。
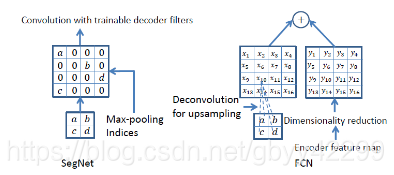
2)SegNet
网络结构如下:

segnet是个典型的encode-decode结构,和FCN的思路很像。segnet采用的是vgg16全连接层前面的网络结构。
这个网络结构比较特殊的地方在于将池化层结果应用到译码过程。引入了更多的编码信息。使用的是pooling indices而不是直接复制特征,只是将编码过程中 pool 的位置记下来,在 uppooling 是使用该信息进行 pooling 。
Upsamping就是Pooling的逆过程(index在Upsampling过程中发挥作用),Upsamping使得图片变大2倍。我们清楚的知道Pooling之后,每个filter会丢失了3个权重,这些权重是无法复原的,但是在Upsamping层中可以得到在Pooling中相对Pooling filter的位置。所以Upsampling中先对输入的特征图放大两倍,然后把输入特征图的数据根据Pooling indices放入,下图所示,Unpooling对应上述的Upsampling,switch variables对应Pooling indices。
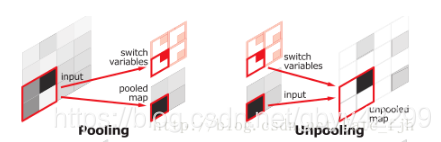
对比FCN可以发现SegNet在Unpooling时用index信息,直接将数据放回对应位置,后面再接Conv训练学习。这个上采样不需要训练学习(只是占用了一些存储空间)。反观FCN则是用transposed convolution策略,即将feature 反卷积后得到upsampling,这一过程需要学习,同时将encoder阶段对应的feature做通道降维,使得通道维度和upsampling相同,这样就能做像素相加得到最终的decoder输出.
对于这个paper中对于类别不平衡的问题也进行了相应的加权,计算方法如下:
f(class) = frequency(class) / (image_count(class) * w * h)
weight(class) = median of f(class)) / f(class)
其中frequency(class)的意思是该类别的training set的总像素的个数;比如在我的数据集合中training set的数量为500张图片,房屋像素的个数总和为30000个像素;
image_count(class)的意思是在training set中含有该类别的像素的图片的数量;比如含有房屋的图片的个数位467张
,w*h为图片的尺寸;median of f(class))为计算出的f(class) 的中位数;
附我实现的代码如下:https://github.com/gbyy422990/segnet_tf/blob/master/median_frequency_balancing.py
另外一种Bayesian SegNet模型我后面再补充。
3)U-Net
这个网络结构由于比较简单,在这里就不再赘述了,结构图如下:
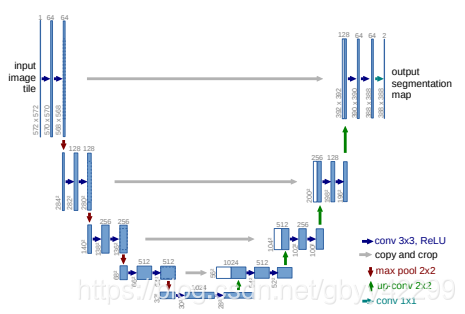
依然使用Vgg16进行特征抽取,然后上采样的时候结合前面的同等大小的采样过程中的特征进行channel维度上的拼接。
U-Net采用了与FCN完全不同的特征融合方式:拼接!即:与FCN的逐点相加不同,Unet采用的是特征在channel维度上拼接在一起,形成更“厚”的特征。
4)DeepLab V1
CNN在处理分割问题是会出现的问题:1.下采样(downsampling,如max pooling)导致的细节信息丢失(使用带孔卷积解决下采样问题);2.CNN的空间不变性(spatial insensitivity/invariance)(使用Dense CRF解决空间不变形问题)。
模型结构:
主要是对原有VGG网络进行了一些变换:
将原先的全连接层通过卷基层来实现。
VGG网络中原有5个max pooling,先将后两个max pooling的stride从2变为1,相当于只进行了8倍下采样。
将后两个max pooling后的普通卷基层,改为使用带孔卷积。
为了控制视野域(同时减少计算量),对于VGG中的第一个fully connected convlution layer,即77的卷基层,使用33或4*4的卷积来替代。
损失函数:交叉熵之和。
训练数据label:对原始Ground Truth进行下采样8倍,得到训练label。
预测数据label:对预测结果进行双线性上采样8倍,得到预测结果。
5)DeepLab V2
本文为使用深度学习的语义分割任务,做出了三个主要贡献:
首先,强调使用空洞卷积,作为密集预测任务的强大工具。空洞卷积能够明确地控制DCNN内计算特征响应的分辨率,即可以有效的扩大感受野,在不增加参数量和计算量的同时获取更多的上下文。
其次,我们提出了空洞空间卷积池化金字塔(atrous spatial pyramid pooling (ASPP)),以多尺度的信息得到更强健的分割结果。ASPP并行的采用多个采样率的空洞卷积层来探测,以多个比例捕捉对象以及图像上下文。
最后,通过组合DCNN和概率图模型,改进分割边界结果。在DCNN中最大池化和下采样组合实现可平移不变性,但这对精度是有影响的。通过将最终的DCNN层响应与全连接的CRF结合来克服这个问题。
将DCNN应用在语义分割任务上,我们着重以下三个问题:
降低特征分辨率
多个尺度上存在对象
由于DCNN的内在不变性,定位精度底
接下来我们讨论并解决这些问题。
第一个挑战是因为:DCNN连续的最大池化和下采样组合引起的空间分辨率下降,为了解决这个问题,DeepLabv2在最后几个最大池化层中去除下采样,取而代之的是使用空洞卷积,以更高的采样密度计算特征映射。
第二个挑战是因为:在多尺度上存在物体。解决这一问题有一个标准方法是将一张图片缩放不同版本,汇总特征或最终预测得到结果,实验表明能提高系统的性能,但这个增加了计算特征响应,需要大量的存储空间。我们受到spatial pyramid pooling(SPP)的启发,提出了一个类似的结构,在给定的输入上以不同采样率的空洞卷积并行采样,相当于以多个比例捕捉图像的上下文,称为ASPP(atrous spatial pyramid pooling)模块。

第三个挑战涉及到以下情况:对象分类要求空间变换不变性,而这影响了DCNN的空间定位精度。解决这一问题的一个做法是在计算最终分类结果时,使用跳跃层,将前面的特征融合到一起**。DeepLabv2是采样全连接的CRF在增强模型捕捉细节的能力。
整个网络的总体步骤如下:
总体步骤如下:

1.输入经过改进的DCNN(带空洞卷积和ASPP模块)得到粗略预测结果,即Aeroplane Coarse Score map ----> 2.通过双线性插值扩大到原本大小,即Bi-linear Interpolation ---->3.再通过全连接的CRF细化预测结果,得到最终输出Final Output
ps:这部分比较简单,所以我就在这里贴一个我觉得写的比较好的博客https://blog.csdn.net/u011974639/article/details/79138653
6)DeepLab V3
首先还是再总结一下空洞卷积的好处:
允许调整卷积核的感受野,获得不同尺度的信息,且不增加参数,且不减小分辨率
允许显式的控制特征提取的密度。空洞卷积rate越大,会让输出的feature map提取到的特征越密集。(feature map中很多grid cell都能提取到相同部分的特征)
然后是v3的改进,新的ASPP,网络结构如下图:

新的ASPP增加了一个1x1的卷积核,以及一个global ave pooling。最后concat,再经过一个1x1卷积输出。(对了,这块还引入了normalization)
关于引入global ave pooling,文中是这样解释的:
(1) 当空洞rate越大(eg: 卷积核的感受野和feature map一样大),越来越多的kernel实际卷积到的是padded zero。当卷积核变得和feature map一样大时,相当于卷积核退化成了1x1,因为padded feature map只有最中心的部分才是有效的。
(2) 为了解决上面的问题,同时为了加入全局信息。直接用global ave pooling。
7)DeepLab V3+
V3+主要做了三个方面的改进:
1、将空洞卷积和depthwise convolution、pointwise convolution 做了结合;
2、全新的网络结构;如下:其中decoder部分和deeplab v3一样。

3、新的xception结构,如下图:

max pooling被separable convolution with stride替换了。
8)RefineNet
作者的出发点:直接在CNN 网络中加上VGG,ResNet 用于语义分割存在的问题是CNN 卷积池化得到的特征图是降采样的32 倍,很多细节信息都丢失了,这样的分割结果是比较粗糙的。当前解决该问题的研究方法主要有:
使用反卷积作为上采样的操作,但是反卷积不能恢复低层的特征,毕竟这是已经丢失了的,是不可能找回来的。
Atrous Convolution:带孔卷积的提出就是为了生成高分辨率的特征图,但是需要消耗巨大的计算和存储资源。
利用中间层信息:FCN-8s 就是这样做的,但是还是缺少较强的空间信息。作者一直在强调各层的信息所表示的意义,高层提取的是粗糙的全局信息,低层提取的是高分辨率的细节信息,但是中间层的信息如何使用是作者在论文中反复提到的问题。作者认为各层的特征都是有用的,高层特征有助于类别识别,低层特征有助于生成精细的边界。将这些特征全部融合对于提升分割的准确率是有帮助的。
整体的网络结构如下:

RefineNet block 的作用就是把不同分辨率的特征图进行融合。最左边一栏使用的是ResNet,先把pretrained ResNet 按特征图的分辨率分成四个ResNet blocks,然后向右把四个blocks 分别作为4 个path 通过RefineNet block 进行融合,最后得到一个refined feature map(接softmax 层,再双线性插值输出)。除了RefineNet-4,所有的RefineNet block 都是二输入的,用于融合不同level 做refine,而单输入的RefineNet-4 可以看作是先对ResNet 的一个task adaptation。
RefineBlock
其中redine block的结构如下:

- RCU:是从残差网络中提取出来的单元结构
- Multi-resolution fusion:是先对多输入的特征图都用一个卷积层进行自适应(都化到最小的特征图的尺寸大小),再上采样,最后做element-wise 的相加。如果是像RefineNet-4 的单输入block 这一部分就不用了。
- Chained residual pooling:卷积层作为之后加权求和的权重,relu 对接下来池化的有效性很重要,而且使得模型对学习率的变化没这么敏感。这个链式结构能从很大范围区域上获取背景context。另外,这个结构中大量使用了identity mapping 这样的连接,无论长距离或者短距离的,这样的结构允许梯度从一个block 直接向其他任一block 传播。
- Output convolutions:输出前再加一个RCU。
9)PSPNet
复杂场景会出现的问题:
1、Mismatched Relationship 关系不匹配
复杂场景理解中,上下文关系是很普遍且重要的,物体间存在的共生(co-occurrent)的视觉属性. 如,飞机可能在跑道上或者飞在空中,而不是在公路上. 如 Figure2 的第一行,FCN 基于外形将黄色框中的 boat 错误预测成 car. 但从常识来说,car 很少在河流上. 因此,缺少完整的上下文间信息导致容易出现误分类.
2、Confusion Categories 类别易混淆
物体类别标签容易混淆,比如 field 和 earth、mountain 和 hill、wall 和 house 和 building 和 skyscraper. 如 Figure2 的第二行,FCN 将方框中的内容预测分别为 skyscraper 和 building 的一部分. 而实际上,结果应该全部是两者中的一个,而不是都有. 通过利用类别间的关系能够纠正该问题.
3、Inconspicuous Classes 类别不显著
场景中包含任意大小的物体,一些小尺寸、不显著(Inconspicuous)的物体很难被发现,比如路灯和信号牌等,但这些小物体的作用却很大. 而,大尺寸的物体超出了FCN的接受野,导致预测结果不连续(discontinuous). 如 FIgure2 的第三行,pillow(枕头) 和 sheet(床单) 外形比较相似,俯瞰全局场景类别可能忽略掉 pillow. 因此,为了能较好的考虑不同尺寸大小的物体,需要注意包含不显著物体的不同子区域.

网络结构如下:

基于以上三类问题, 提出 Pyramid Pooling Module 来有效获取全局上下文信息.
- 深度网络中的接受野大小可以粗略的估计获取的上下文信息的多少.
- 理论上,ResNet 的接受野大于输入图像;但实际上,CNN的接受野是比理论上要小的,尤其是在网络的 high-level 层.
- Global average pooling(全局平均池化) 是一种较好获取全局上下文信息的方法
- Spatial pyramid pooling in deep convolutional networks for visual recognition 中,采用 pyramid pooling 得到的不同 levels 的 feature maps 转化为固定长度的一维特征表示,输入到全连接层,以进行分类任务. 该一维全局先验信息去除了CNN的固定尺寸约束.
- 为了减少不同子区域的上下文信息损失,这里提出分层全局先验,包含了不同尺度和不同子区域的信息,即 pyramid pooling module,添加在深度网络的最后输出层的 feature maps. 如 Figure3©.
pyramid pooling module 进行了四种不同的 pyramid scales,再进行特征融合
红色部分是 global pooling 生成一个单元格输出;
pyramid level 将 feature map 分成不同的子区域,并得到不同位置的 pooled 特征表示.
不同 levels 的输出包含了不同尺寸的 feature map; 四个 level 的单元格大小分别为 1×11×1、 2×22×2、3×33×3 和 6∗66∗6;
在各 pyramid level 后采用 1×11×1 卷积层对上下文特征进行降维,保持全局特征的权重,如果 pyramid 的 level 大小为 NN,则卷积层后变为 1N1N;
对低维 feature maps 进行双线性差值(bilinear interpolation)的 upsample 操作,以得到与原始 feature maps 一样的尺寸大小;
连接不同 levels 的 features,即可得到最终的 pyramid pooling global feature.
- 给定输入图片,采用 dilated 化的预训练的 ResNet 模型提取 feature map,得到的 feature map 的尺寸是输入图片的 1/81/8,如 Figure3(b);
- 采用 pyramid pooling module 对提取的 feature map 进行处理,以收集上下文信息;
- 4-level pyramid module 采用的 pooling kernel 分别覆盖了图片的整个区域、半个区域以及更小的区域,并进行特征融合.
- 采用一个卷积层输出最终的预测结果,如 Figure3(d)。
ps:写的比较好的一个博客:https://blog.csdn.net/zziahgf/article/details/73294753
10)ICNet
先放一张inference的速度图:

提出的模型利用了低分辨率图片的高效处理和高分辨率图片的高推断质量两种优点。主要思想是:让低分辨率图像经过整个语义网络输出一个粗糙的预测,然后利用文中提出的cascade fusion unit来引入中分辨率和高分辨率图像的特征,从而逐渐提高精度。整个网络结构如下:

其中CFF结构如下:

其中F1为低分辨率的输入,F2为高分辨率的输入。将低分辨率的图片上采样后使用空洞卷积(dilated conv),扩大上采样结果的感受野范围。
根据1/2,1/4,1/8三个分支进行训练具体细节如下:

ps:一个写的比较好的博客:https://blog.csdn.net/u011974639/article/details/79007588
11)BiSeNet
旷视出品的文章,为了加速语义分割而做的工作。作者指出目前语义分割的加速主要是在如下的方面:
1、通过剪裁或 resize 来限定输入大小,以降低计算复杂度。尽管这种方法简单而有效,空间细节的损失还是让预测打了折扣,尤其是边界部分,导致度量和可视化的精度下降;
2、通过减少网络通道数量加快处理速度,尤其是在骨干模型的早期阶段,但是这会弱化空间信息。
3、为追求极其紧凑的框架而丢弃模型的最后阶段(比如ENet)。该方法的缺点也很明显:由于 ENet 抛弃了最后阶段的下采样,模型的感受野不足以涵盖大物体,导致判别能力较差。
总之,上述三个方法都是折中精度以求速度,难以付诸实践。图 1(a) 是其图示。为解决上述空间信息缺失问题,研究者普遍采用 U 形结构。通过融合 backbone 网络不同层级的特征,U 形结构逐渐增加了空间分辨率,并填补了一些遗失的细节。

但是,这一技术有两个弱点:1)由于高分辨率特征图上额外计算量的引入,完整的 U 形结构拖慢了模型的速度。2)更重要的是,如图 1(b) 所示,绝大多数由于裁剪输入或者减少网络通道而丢失的空间信息无法通过引入浅层而轻易复原。换言之,U 形结构顶多是一个备选方法,而不是最终的解决方案。
所以本文提出了双向分割网络(Bilateral Segmentation Network/BiseNet),它包含两个部分:Spatial Path (SP) 和 Context Path (CP),先上整体的网络结构图如下:其中SP解决空间信息缺失,而CP为了感受野缩小的问题

SP模块
SP包含三层,每层包含一个步幅(stride)为 2 的卷积,随后是批归一化和 ReLU。因此,该路网络提取相当于原图像 1/8 的输出特征图。由于它利用了较大尺度的特征图,所以可以编码比较丰富的空间信息。
CP模块
为增大感受野,一些方法利用金字塔池化模块,金字塔型空洞池化(ASPP)或者 “large kernel”,但是这些操作比较耗费计算和内存,导致速度慢。出于较大感受野和较高计算效率兼得的考量,本文提出 Context Path,它充分利用轻量级模型与全局平均池化以提供大感受野。
TF版本的网络结构大致如下:

文章除了最后的pred的softmax loss外,还添加了额外的两个特殊的辅助损失函数监督 Context Path 的输出,就像多层监督一样。最后借助参数 α 以平衡主损失函数与辅助损失函数的权重。
