不久前 Kvrocks 发布 2.0.5 版本,该版本不仅增加了许多新功能,还使用了RocksDB 的新特性大大提升了性能。本文将重点介绍 Kvrocks 是如何使用这些特性来提升磁盘类型 Redis 服务的性能,希望能给大家带来一些参考。
背景
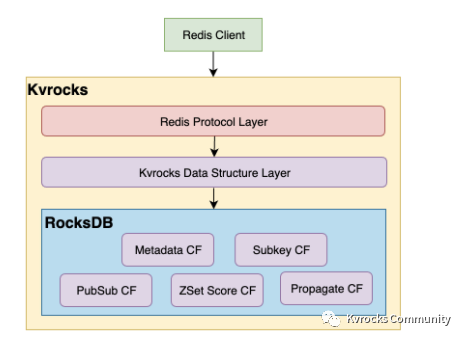
在介绍性能优化之前,首先简单介绍一下 Kvrocks 是如何与 RocksDB 交互的。从实现上来看,Kvrocks 会将 Redis 数据类型编码成 Key-Value 数据写入 RocksDB 的不同 Column Family (以下简称 CF)中。
目前主要有以下几种 CF:
Metadata CF:主要存储 String 类型的数据,以及 Hash/Set/List 这些复杂类型的元数据 (长度,过期时间等),不存储具体元素内容
Subkey CF:存储复杂类型元素内容
ZSetScore CF:存储 ZSet Score 信息
Pub/Sub CF:Pub/Sub 相关信息
Propagated CF: 作为主从同步和存放数据之外的内容,比如 Lua 脚本
此外,Kvrocks 还利用 RocksDB 的原生 WAL 日志实现主从同步,Kvrocks: 一款开源的企业级磁盘 KV 存储服务 一文详细介绍了 Kvrocks 的设计与实现,感兴趣的同学可以去看看。交互逻辑如图所示:
接下来重点看 Kvrocks 如何用 RocksDB 多维度的特性来优化性能:
优化细节
Memtable 优化
Kvrocks 当前使用的是 SkipList Memtable,相比 HashSkipList Memtable 跨多个前缀查找的性能更好,也更节省内存。同时针对 SkipList Memtable 打开 whole_key_filtering 选项,该选项会为 Memtable 中的 key 创建 Bloom Filter,这可以减少在跳表中的比较次数,从而降低点查询时的 CPU 使用率。
相关配置:
metadata_opts.memtable_whole_key_filtering = true
metadata_opts.memtable_prefix_bloom_size_ratio = 0.1
SST 优化
Data Block
在 Data Block 上使用 Hash 索引来提升点查询的效率。之前 Kvrocks 在查找 Data Block 时使用二分查找,这会导致 CPU Cache Miss,增加 CPU 使用率。如果在 Data Block 上使用 Hash 索引,可以避免二分查找,在点查询场景下降低 CPU 利用率。官方的测试数据显示:该特性可降低 21.8% 的CPU 利用率,提升 10% 的吞吐,但会增加 4.6% 的空间占用。相比磁盘资源,CPU 资源更加昂贵,权衡之下,Kvrocks 选择开启 Hash 索引来提升点查询的效率。
相关配置:
BlockBasedTableOptions::data_block_index_type = DataBlockIndexType::kDataBlockBinaryAndHash
// 如果此值小的话,说明 Hash 桶多,冲突就比较小。
BlockBasedTableOptions::data_block_hash_table_util_ratio = 0.75
Filter/Index Block
旧版本的 RocksDB 默认使用的是 BlockBasedFilter 类型的 Bloom Filter,这也是 LevelDB 的方式。基本原理是每 2KB 的 Key-Value 数据产生一个 Filter,最后组成一个 Filter 数组。查找的时候,先查 Index Block, 对于可能存在该 Key 的 Data Block,再通过对应的 Filter Block 来判断 Key 是否存在。
新版本的 RocksDB 通过引入 Full Filter 来对原有的 Filter 机制进行优化。每个 SST 都有一个 Filter,这样可以检查 Key 是否存在于 SST 中,避免读取 Index Block。但在 SST 中 key 较多的场景下,仍会导致 Filter Block 和 Index Block 较大。对于 256MB 的 SST 来说,Index 和 Filter Block 的大小约为 0.5MB 和 5MB,这比 Data Block(通常 4-32KB)大得多。最理想的情况下, Index/Filter Block 完全存于内存时,每个 SST 生命周期只会读取一次,但当与 Data Block 竞争 Block Cache 时,很可能因为被剔除的原因,从磁盘上重新读取很多次,导致读放大非常严重。
Kvrocks 以前的做法是动态的调节 SST 相关的配置,使得 SST 文件不会过大,从而避免 Index/Filter Block 过大。但是这种机制存在的问题是当数据量非常大时,SST 文件数量过多会占用比较多的系统资源,也会带来性能的衰减。新版本 Kvrocks 对此进行了优化,打开 Partitioned Block 相关的配置, Partitioned Block 的原理是在 Index/Filter Block 加一层二级索引,当读 Index 或者 Filter 时,先将二级索引读入内存,然后根据二级索引找到所需的分区 Index Block,将其加载进 Block Cache 里面。
Partitioned Block 带来的优点如下:
增加缓存命中率:大 Index /Filter Block 会污染缓存空间,将大的 Block 进行分区,允许以更细的粒度加载 Index/Filter Block,从而有效地利用缓存空间
提高缓存效率:分区 Index/Filter Block 将变得更小,在 Cache 中锁的竞争将进一步降低,提升了高并发下的效率
降低 IO 利用率:当索引 / 过滤器分区的缓存 Miss 时,只需要从磁盘加载一个小的分区,与读取整个 SST 文件的 Index/Filter Block 相比,这会使磁盘上的负载更小
相关配置:
format_version = 5
index_type = IndexType::kTwoLevelIndexSearch # 使用 partition index
NewBloomFilterPolicy(BITS, false) : 使用 Full Filter
BlockBasedTableOptions::partition_filters = true # 使用partition filter, index_type 必须为 kTwoLevelIndexSearch
cache_index_and_filter_blocks = true
pin_top_level_index_and_filter = true
cache_index_and_filter_blocks_with_high_priority = true
pin_l0_filter_and_index_blocks_in_cache = true
optimize_filters_for_memory = true
数据压缩优化
RocksDB 在数据落盘时会对数据进行压缩,我们在 Kvrocks 上对不同的压缩算法进行了对比测试,发现不同的压缩算法对性能影响非常大,特别是 CPU 资源紧张的情况下,会显著增加长尾延迟。
下图是不同压缩算法压缩速度和压缩比的测试数据:
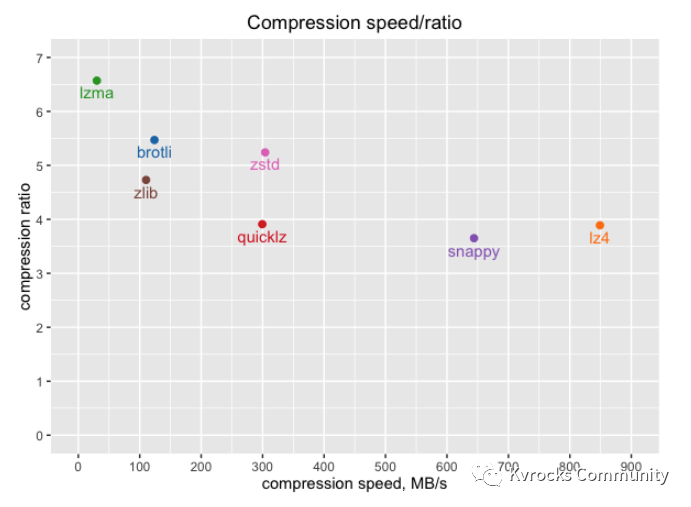
在 Kvrocks 中对 L0 层和 L1 层的 SST 不设置压缩,因为这两层数据量较少,压缩这些层级的数据并不能减少很多磁盘空间,但不压缩这些层级的数据可以节省 CPU。每个 L0 到 L1 的 Compaction 都需要访问 L1 中的所有文件,另外,范围扫描不能使用 Bloom Filter,需要查找 L0 中的所有文件。如果读 L0 和 L1 中的数据时不需要解压缩,写 L0 和 L1 中的数据不需要压缩,那么这两种频繁的 CPU 密集型操作会占用更少的 CPU,相比通过压缩节省的磁盘空间来说收益更大。
从压缩速度以及压缩比两方面权衡考虑,Kvrocks 主要选择 LZ4 和 ZSTD 两种算法。 对于其他层级,使用 LZ4 是因为该压缩算法速度更快,压缩比也较高,RocksDB 官方建议使用 LZ4。对于大数据量、低 QPS 的场景,还会将最后一层设置为 ZSTD,进一步降低存储空间和减少成本,ZSTD 的优点是压缩比更高,压缩速度也较快。
Cache 优化
对于简单数据类型 (String 类型),直接将数据存到 Metadata CF 中,而复杂数据类型只会将元数据存到 Metadata CF,实际数据存储在 Subkey CF。Kvrocks 之前默认为这两个 CF 分配了相同大小的 Block Cache,而线上场景复杂,无法预知用户的使用数据类型,所以不能提前给每个 CF 分配合适的 Block Cache 大小。如果用户使用简单类型和使用复杂类型比例不相当时,会使得 Block Cache 命中率降低。Kvrocks 通过共享同一个大 Block Cache 的方式来 Cache 的命令率,实现提升了 30% 的性能。
此外,还引入 Row Cache 应对热点 Key 的问题。RocksDB 先检查 Row Cache,再检查 Block Cache,对于存在热点的场景,数据会优先存放在 Row Cache 中,进一步提高 Cache 利用率。
Key-Value 分离
LSM 存储引擎会将 Key 和 Value 存放在一起,在 Compaction 的过程中,Key 和 Value 都会被重写一遍,当 Value 较大时,会带来严重的写放大问题。针对此问题,WiscKey[1](FAST'16)这篇论文提出了 Key-Value 分离的方案,业界也基于此论文实现了 LSM 型存储引擎的 KV 分离,比如:RocksDB 的 BlobDB、PingCAP 的 Titan 引擎、百度的 UNDB 所使用的 Quantum 引擎。
RocksDB 6.18 版本重新实现了 BlobDB(RocksDB 的 Key-Value 分离方案),将其集成到 RocksDB 的主逻辑中,并且也一直在完善和优化 BlobDB 相关特性。Kvrocks 在 2.0.5 引入此特性,应对大 Value 的场景。测试显示,当 Kvrocks 打开 KV 分离开关时,针对 Value 为 10KB 的场景,写性能提升 2.5 倍,读性能并没有衰减;Value 越大,写性能提升幅度越大,Value 为 50KB 场景下,写性能提升了 5 倍。
相关配置:
ColumnFamilyOptions.enable_blob_files = config_->RocksDB.enable_blob_files;
min_blob_size = 4096
blob_file_size = 128M
blob_compression_type = lz4
enable_blob_garbage_collection = true
blob_garbage_collection_age_cutoff = 0.25
blob_garbage_collection_force_threshold = 0.8
未来工作
2021 年已经接近尾声,Kvrocks 2.0[2] 的相关工作已基本完成,Kvrocks 3.0[3] 的计划也已经在 Github 上列出,本文列举如下两个重要的特性。
持久内存的应用
英特尔傲腾持久内存(Optane PMem)弥补了传统 SSD 和 DRAM 之间的空白,以创新的技术提供独特的操作模式,满足各种工作负载的需求。随着高性能存储硬件的发展,传统的存储架构逐渐无法发挥新硬件的性能,传统引擎的架构需要在 PMem 上重新调整。Intel 的 KVDK 对 Kvrocks 进行了适配,并进行了测试(详见 https://github.com/pmem/kvdk/tree/main/examples/kvrocks)。 Kvrocks 社区也在积极跟进新存储硬件的发展,探索在 RocksDB 上以及 Redis 场景下如何更好的使用 PMem,进而降低用户成本和提升访问性能。
计算存储分离架构
在 Rocksdb Virtual Meetup 2021 上, RocksDB 团队分享了计算存储分离方案,将 SST 文件存储到远程分布式文件系统之上,其团队负责人也透露未来将高优开发计算存储分离相关特性,尽快将此特性在 Facebook 内部落地。
LSM 型数据库需要进行 Compaction 来减少空间放大,Compaction 是 CPU 密集型的操作,传统架构下 Compaction 和上层服务耦合在一起,相互影响,甚至会阻塞上层写入(称为 Write Stall)。RocksDB 引入 Remote Compaction 特性将 CPU 密集型的 Compaction 转移到远程去执行,实现服务计算与存储引擎计算剥离,达到计算资源的极致弹性。为了降低访问远程存储的延迟 RocksDB 引入 Secondary Cache(可以是内存、PMem、NVMe-SSD 组成的多级 Cache),将 Block Cache 淘汰的数据缓存在本地,减少访问远程存储的次数。
未来 Kvrocks 社区也会持续跟进 RocksDB 的进展,尽快推出计算存储分离架构的 Kvrocks,积极拥抱云原生,实现计算、存储极致的弹性,进一步降低用户云上成本。
总结
Kvrocks 通过使用 RocksDB 的新特性进一步提升了性能,为用户带来了极致的性能体验。
目前 Kvrocks 已经在线上大规模运行两年之久,基本功能已充分验证,大家可以放心使用。如遇到问题,大家可以在微信群,Slack (见 GitHub README),Github issue 和 discussion 上反馈和交流,Kvrocks 社区也欢迎提大家提 PR 来一起完善 Kvrocks。
GitHub Repo: https://github.com/KvrocksLabs/kvrocks
在社区维护上,希望可以有更加开放的交流氛围,而不只是把代码放到 GitHub 的开源。不管是功能设计还是代码开发,都会尽量把相关细节在 GitHub 里面公开去讨论。
不久前,Kvrocks 荣获「2021 年度 OSCHINA 优秀开源技术团队」[4],感谢大家的支持!
参考资料
[1]
WiscKey: https://www.usenix.org/system/files/conference/fast16/fast16-papers-lu.pdf
[2]
Kvrocks 2.0: https://github.com/KvrocksLabs/kvrocks/projects/1
[3]
Kvrocks 3.0: https://github.com/KvrocksLabs/kvrocks/projects/2
[4]
2021 年度 OSCHINA 优秀开源技术团队: https://my.oschina.net/oscpyaqxylk/blog/5350757
参考阅读:
技术原创及架构实践文章,欢迎通过公众号菜单「联系我们」进行投稿。
高可用架构
改变互联网的构建方式