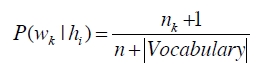from __future__ import print_function
import os, codecs, math
class BayesText:
def __init__(self, trainingdir, stopwordlist, ignoreBucket):
"""This class implements a naive Bayes approach to text
classification
trainingdir is the training data. Each subdirectory of
trainingdir is titled with the name of the classification
category -- those subdirectories in turn contain the text
files for that category.
The stopwordlist is a list of words (one per line) will be
removed before any counting takes place.
"""
self.vocabulary = {}
self.prob = {}
self.totals = {}
self.stopwords = {}
f = open(stopwordlist)
for line in f:
self.stopwords[line.strip()] = 1
f.close()
categories = os.listdir(trainingdir)
#filter out files that are not directories
self.categories = [filename for filename in categories
if os.path.isdir(trainingdir + filename)]
print("Counting ...")
for category in self.categories:
#print(' ' + category)
(self.prob[category],
self.totals[category]) = self.train(trainingdir, category,
ignoreBucket)
# I am going to eliminate any word in the vocabulary
# that doesn't occur at least 3 times
toDelete = []
for word in self.vocabulary:
if self.vocabulary[word] < 3:
# mark word for deletion
# can't delete now because you can't delete
# from a list you are currently iterating over
toDelete.append(word)
# now delete
for word in toDelete:
del self.vocabulary[word]
# now compute probabilities
vocabLength = len(self.vocabulary)
#print("Computing probabilities:")
for category in self.categories:
#print(' ' + category)
denominator = self.totals[category] + vocabLength
for word in self.vocabulary:
if word in self.prob[category]:
count = self.prob[category][word]
else:
count = 1
self.prob[category][word] = (float(count + 1)
/ denominator)
#print ("DONE TRAINING\n\n")
def train(self, trainingdir, category, bucketNumberToIgnore):
"""counts word occurrences for a particular category"""
ignore = "%i" % bucketNumberToIgnore
currentdir = trainingdir + category
directories = os.listdir(currentdir)
counts = {}
total = 0
for directory in directories:
if directory != ignore:
currentBucket = trainingdir + category + "/" + directory
files = os.listdir(currentBucket)
#print(" " + currentBucket)
for file in files:
f = codecs.open(currentBucket + '/' + file, 'r', 'iso8859-1')
for line in f:
tokens = line.split()
for token in tokens:
# get rid of punctuation and lowercase token
token = token.strip('\'".,?:-')
token = token.lower()
if token != '' and not token in self.stopwords:
self.vocabulary.setdefault(token, 0)
self.vocabulary[token] += 1
counts.setdefault(token, 0)
counts[token] += 1
total += 1
f.close()
return(counts, total)
def classify(self, filename):
results = {}
for category in self.categories:
results[category] = 0
f = codecs.open(filename, 'r', 'iso8859-1')
for line in f:
tokens = line.split()
for token in tokens:
#print(token)
token = token.strip('\'".,?:-').lower()
if token in self.vocabulary:
for category in self.categories:
if self.prob[category][token] == 0:
print("%s %s" % (category, token))
results[category] += math.log(
self.prob[category][token])
f.close()
results = list(results.items())
results.sort(key=lambda tuple: tuple[1], reverse = True)
# for debugging I can change this to give me the entire list
return results[0][0]
def testCategory(self, direc, category, bucketNumber):
results = {}
directory = direc + ("%i/" % bucketNumber)
#print("Testing " + directory)
files = os.listdir(directory)
total = 0
correct = 0
for file in files:
total += 1
result = self.classify(directory + file)
results.setdefault(result, 0)
results[result] += 1
#if result == category:
# correct += 1
return results
def test(self, testdir, bucketNumber):
"""Test all files in the test directory--that directory is
organized into subdirectories--each subdir is a classification
category"""
results = {}
categories = os.listdir(testdir)
#filter out files that are not directories
categories = [filename for filename in categories if
os.path.isdir(testdir + filename)]
correct = 0
total = 0
for category in categories:
#print(".", end="")
results[category] = self.testCategory(
testdir + category + '/', category, bucketNumber)
return results
def tenfold(dataPrefix, stoplist):
results = {}
for i in range(0,10):
bT = BayesText(dataPrefix, stoplist, i)
r = bT.test(theDir, i)
for (key, value) in r.items():
results.setdefault(key, {})
for (ckey, cvalue) in value.items():
results[key].setdefault(ckey, 0)
results[key][ckey] += cvalue
categories = list(results.keys())
categories.sort()
print( "\n Classified as: ")
header = " "
subheader = " +"
for category in categories:
header += "% 2s " % category
subheader += "-----+"
print (header)
print (subheader)
total = 0.0
correct = 0.0
for category in categories:
row = " %s |" % category
for c2 in categories:
if c2 in results[category]:
count = results[category][c2]
else:
count = 0
row += " %3i |" % count
total += count
if c2 == category:
correct += count
print(row)
print(subheader)
print("\n%5.3f percent correct" %((correct * 100) / total))
print("total of %i instances" % total)
# change these to match your directory structure
prefixPath = "reviewPolarityBuckets/review_polarity_buckets/"
theDir = prefixPath + "/txt_sentoken/"
stoplistfile = prefixPath + "stopwords25.txt"
tenfold(theDir, stoplistfile)