实验目的:
掌握词典编码的基本原理,阅读C语言实现的LZW算法并用C++按自己理解实现LZW解码器并分析编解码算法,以及LZW算法对不同文件的压缩效果。
LZW算法原理:
关于更具体的图解LZW编解码可以参考:超级简单的数据压缩算法—LZW算法
编码部分:

简单地讲,LZW的编码就是不断将目前字符‘c’与上一个字符串P串成一个新串,并与词典中已有串进行不断比对,若新串P+‘c’在词典中,则将P+‘c’的索引赋给P并读取下一个字符;若P+‘c’不在词典中,则发送码字P的索引,并将P+‘c’写入词典。该算法压缩任何文件时均以字符串的形式读入数据。
注:原理上是这样解释,但在编程时有个坑,在C++中使用fstream操作文件流时仍需按ios::binary形式打开文件,否则会遇到读入的时候若读到与EOF相同的字节程序会认为文件结束,从而引发错误。这里读入一个字符更准确的解释是读入一个unsigned char型数据。
以下是教材中对于LZW编码的解释:
LZW编码原理和实现算法
LZW的编码思想是不断地从字符流中提取新的字符串,通俗地理解为新“词条”,然后用“代号”也就是码字表示这个“词条”。这样一来,对字符流的编码就变成了用码字去替换字符流,生成码字流,从而达到压缩数据的目的。LZW编码是围绕称为词典的转换表来完成的。LZW编码器通过管理这个词典完成输入与输出之间的转换。LZW编码器的输入是字符流,字符流可以是用8位ASCII字符组成的字符串,而输出是用N位(例如12位)表示的码字流。LZW编码算法的步骤如下:
步骤1:将词典初始化为包含所有可能的单字符,当前前缀P初始化为空。
步骤2:当前字符C=字符流中的下一个字符。
步骤3:判断P+C是否在词典中
(1)如果“是”,则用C扩展P,即让P=P+C,返回到步骤2。
(2)如果“否”,则
输出与当前前缀P相对应的码字W;
将P+C添加到词典中;
令P=C,并返回到步骤2
解码部分:

对于LZW的解码,可以认为是这样的:解码器不断接收新的码字索引,根据索引查得当前码字C,并将每一个新码字C的第一个字符C[0]与上一个码字P组合成一个新的码字加入字典。
需要注意的是,新码字索引C有可能会不在词典当中。当编码端对类似ABABABA这样具有对称性的字符串进行编码时,会出现如接收端接收到230号码字但实际词典中只有0-299号码字。在这种情况下,根据LZW算法的编码原理,可推知230号码字由299号码字串接230号码字的第一个字符组成,于是,230号码字为299号码字+299号码字中的第一个字符,完成对230号码字的解码。
以下是教材中对于LZW编码的解释:
LZW解码原理和实现算法 LZW解码算法开始时,译码词典和编码词典相同,包含所有可能的前缀根。具体解码算法如下:
步骤1:在开始译码时词典包含所有可能的前缀根。
步骤2:令CW:=码字流中的第一个码字。
步骤3:输出当前缀-符串STRING.CW到码字流。
步骤4:先前码字PW:=当前码字CW。
步骤5:当前码字CW:=码字流的下一个码字。
步骤6:判断当前缀-符串STRING.CW 是否在词典中。
(1)如果”是”,则把当前缀-符串STRING.CW输出到字符流。
当前前缀P:=先前缀-符串STRING.PW。
当前字符C:=当前前缀-符串STRING.CW的第一个字符。
把缀-符串P+C添加到词典。
(2)如果”否”,则当前前缀P:=先前缀-符串STRING.PW。
当前字符C:=当前缀-符串STRING.CW的第一个字符。
输出缀-符串P+C到字符流,然后把它添加到词典中。
步骤7:判断码字流中是否还有码字要译。
(1)如果”是”,就返回步骤4。
(2)如果”否”,结束。
数据结构:
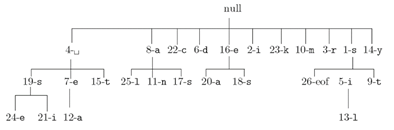
词典采用动态建立的树的结构,便于查找。
每个节点包含信息如下:
| 内容 |
大小 |
| 尾缀字符(suffix) |
1Byte |
| 母节点(parent) |
1Byte |
| 第一个孩子节点( firstchild ) |
1Byte |
| 下一个兄弟节点(nextsibling) |
1Byte |
树中的每一个结点包含如下信息:尾缀字符(suffix)、母节点(parent)、第一个孩子节点( firstchild )、下一个兄弟节点(nextsibling)。
词典的初始化:初始化0-255号条目,每个条目的尾缀字符suffix就是其索引号,下一个兄弟结点nextsibling为其索引+1(第255号的nextsibling为-1,即不存在),每一项的母结点parent、第一个孩子结点firstchild均为-1,表示不存在。
词典的查找:在查找时某个码字m加上前缀c是否存在于词典中时,先访问码字m,根据码字m的firstchild查找到第一个子节点,根据该子节点及其兄弟结点nextsibling依次访问,便可查找以码字m为前缀的所有词条,若存在,则返回该结点索引,若不存在,返回-1。
词典的添加:将m+‘c’添加进词典。添加时有两种情况,其一,若m没有子节点firstchild,则将‘c’作为其子节点;若m存在子节点,则沿着第一个子节点的兄弟结点nextsibling依次访问,直至末尾,将‘c’添加至该末尾。
此外,为便于解压,需要向压缩后的文件写入原始文件大小。本次实验的程序中所编写的程序每一个码字为2Byte,范围0-65535。
实验素材:
测试LZW压缩效果的文件有:
- 未经压缩的bmp图像文件
- YUV图像文件
- 文本文件
- 经过压缩的png图像文件
- 经过压缩的jpg图像文件
- 无损压缩flac音频文件
- 有损压缩mp3音频文件
- 索尼相机arw RAW图像文件
- exe程序文件
- word文档文件
- pdf文件
实验中所使用的文件并不能很好地代表一般情况
实验结果:
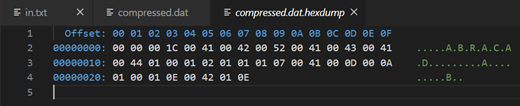
测试用文本文件“in.txt”:

二进制表示:

压缩后结果:
解压结果:
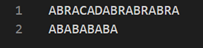
可见,由于一个码字使用16bit表示,在压缩小文件时文件体积不减反增。
对不同种类文件压缩的结果:
| 文件 |
说明 |
输入字节数 |
输出字节数 |
压缩率 |
| test1.bmp |
8bit有调色板bmp文件 |
308278 |
224122 |
72.7% |
| test2.bmp |
24bit真彩色bmp文件 |
196664 |
189832 |
96.5% |
| test3.png |
经过压缩编码的PNG文件 |
163978 |
219674 |
140.0% |
| test4.jpg |
经过压缩编码的JPG文件 |
24200 |
40796 |
168.6% |
| miss.cif |
未经压缩的YUV文件 |
3649536 |
2161456 |
59.2% |
| text_test.txt |
未经压缩的文本文件 |
4723 |
3960 |
83.8% |
| flac_test.flac |
无损音频flac文件 |
39745636 |
49351988 |
124.2% |
| mp3_test.mp3 |
有损音频mp3文件 |
12158251 |
15113846 |
124.3% |
| arw_test.arw |
索尼相机arw RAW图像文件 |
24674304 |
29674756 |
120.3% |
| devenv.exe |
exe程序文件 |
747952 |
650210 |
87.0% |
| docx_test.docx |
word文档文件 |
21954 |
34434 |
156.8% |
| pdf_test.pdf |
pdf文件 |
2357605 |
2791542 |
118.4% |
结果分析
- 实验中的编码由于一个码字为2Byte,所以在传送255以内的码字时会浪费1Byte,造成编码效率下降。
- 从不同文件的压缩结果可以看出,对于未压缩的文件,LZW算法可以进行一定程度的压缩,文件中数据的冗余度越高,压缩性能越好,如一个24fps的CIF分辨率420采样YUV文件,由于每一帧之间存在较高相关性,而且帧内相邻像素之间存在一定相关性,因此获得了比较好的压缩效果。
- 对于未经压缩的BMP文件,由于相邻像素间存在相关性,仍然可以获得一定的压缩效果。
- LZW算法存在固有限制:字符串重复概率低时,影响压缩效率;词典中的字符串不再出现,影响压缩效率。对于已经压缩的文件类型,由于其压缩编码已经文件中大部分相关性去除,每个符号近似于等概分布,其信息熵接近于每符号最大值。在这种情况下文件中很少出现重复字符串,严重影响LZW算法效率,且一个码字为2Byte使得文件体积不减反增。
程序代码
lzw.h
#pragma once
#include "bitio.h"
#include <iostream>
#include <fstream>
#define MAX_size 65535
using namespace std;
typedef unsigned char uint1;
typedef unsigned short uint2;
typedef unsigned int uint4;
bool LZWencode(ifstream& file_in, BitFileOut& bit_out);
bool LZWdecode(ofstream& file_out, BitFileIn& bit_in);
class LZW_Dictionary
{
public:
LZW_Dictionary();
~LZW_Dictionary();
void initDictionary();
int InDict(uint1 character, int string_code);
void AddtoDict(uint1 character, int string_code);
void PrintDict();
int get_next_code();
int DecodeString(int code, int last_code, int start = 0);
uint1* d_stack;
private:
typedef struct {
int suffix;
int parent;
int firstchild;
int nextsibling;
}node;
node* dict;
uint4 next_code;
};
lzw.cpp
#include "lzw.h"
#include <iostream>
using namespace std;
LZW_Dictionary::LZW_Dictionary()
{
initDictionary();
}
LZW_Dictionary::~LZW_Dictionary()
{
delete[] dict;
delete[] d_stack;
}
void LZW_Dictionary::initDictionary()
{
dict = new node[MAX_size + 1];
d_stack = new uint1[MAX_size];
for (int i = 0; i < 256; i++) {
dict[i].suffix = i;
dict[i].parent = -1;
dict[i].firstchild = -1;
dict[i].nextsibling = i + 1;
}
dict[255].nextsibling = -1;
next_code = 256;
}
int LZW_Dictionary::InDict(uint1 character, int string_code)
{
//using -1 to show string_code is null
int sibling;
if (string_code < 0) { return character; }
sibling = dict[string_code].firstchild;
while (sibling > -1) {
if(dict[sibling].suffix == character){
return sibling; //find
}
sibling = dict[sibling].nextsibling; //search the next
}
return -1; //not find
}
void LZW_Dictionary::AddtoDict(uint1 character, int string_code)
{
int firstsibling, nextsibling;
if (0 > string_code) return;
dict[next_code].suffix = character;
dict[next_code].parent = string_code;
dict[next_code].firstchild = -1;
dict[next_code].nextsibling = -1;
firstsibling = dict[string_code].firstchild;
if (-1 < firstsibling) { // the parent has child
nextsibling = firstsibling;
while (-1 < dict[nextsibling].nextsibling)
nextsibling = dict[nextsibling].nextsibling; //searching the last nextsibling
dict[nextsibling].nextsibling = next_code;
}
else {// no child before, modify it to be the first
dict[string_code].firstchild = next_code;
}
next_code++; //important!!!!!
}
void LZW_Dictionary::PrintDict()
{
//print dict after index of 255
for (int i = 256; i < next_code; i++) {
cout << i << ": ";
cout << dict[i].suffix << " ";
cout << dict[i].parent << " ";
cout << dict[i].firstchild << " ";
cout << dict[i].nextsibling << endl;
}
}
int LZW_Dictionary::get_next_code()
{
return next_code;
}
int LZW_Dictionary::DecodeString(int code, int last_code, int start)
{
int count = 0; //using d_stack to storage string
if (code >= next_code) { //case ABABA, the code is made by last code and it's fitst character
count = 1;
while (last_code >= 0) {
start = 1;
d_stack[count] = dict[last_code].suffix;
last_code = dict[last_code].parent;
count++;
}
d_stack[0] = d_stack[count - 1];
}
else { //normal case
while (code >= 0) {
d_stack[count] = dict[code].suffix;
code = dict[code].parent;
count++;
}
}
return count;
}
bool LZWencode(ifstream& file_in, BitFileOut& bit_out)
{
LZW_Dictionary dictionary;
int character(0), string_code(-1), index(0);
uint4 file_length(0);
if (!(file_in.is_open() && bit_out.is_open())) {
cerr << __func__ << "\t Can not open file!" << endl;
return false;
}
//get the length of file and output
file_in.seekg(0, ios::end);
file_length = file_in.tellg();
file_in.seekg(0, 0);
bit_out.BitsOutput(file_length, 4 * 8);
//encode
for (int current_len = 0; current_len < file_length; current_len++) {
file_in.read(reinterpret_cast<char*>(&character), 1);
index = dictionary.InDict(character, string_code);
if (index >= 0) {
string_code = index;
}
else {
bit_out.BitsOutput((uint2)string_code, 16);
if (dictionary.get_next_code() < MAX_size) {
dictionary.AddtoDict(character, string_code);
}
string_code = character;
}
}
bit_out.BitsOutput((uint2)string_code, 16);
return true;
}
bool LZWdecode(ofstream& file_out, BitFileIn& bit_in)
{
if (!(file_out.is_open() && bit_in.is_open())) {
cerr << __func__ << "\t Can not open file!" << endl;
return false;
}
LZW_Dictionary dic;
bool is_end(false);
int new_code(0), last_code(-1);
int word_length(0);
int character;
int file_length = bit_in.BitsInput(4*8,is_end);
if (is_end) {
cerr << __func__ << "\t the number of bits incorrect!" << endl;
return false;
}
//decode
while (file_length > 0) {
new_code = bit_in.BitsInput(16, is_end);
if (is_end) {
cerr << __func__ << "\t the number of bits incorrect!" << endl;
return false;
}
word_length = dic.DecodeString(new_code, last_code);
//add to dict
if (dic.get_next_code() < MAX_size) {
//Addtodict() will handle the case ABABA
dic.AddtoDict(dic.d_stack[word_length - 1], last_code);
}
//out put bit stream to file
while (0 < word_length) {
word_length--;
file_out.write(reinterpret_cast<const char*>(dic.d_stack + word_length), 1);
file_length--;
}
last_code = new_code;
}
return true;
}
bitio.h
#pragma once
#ifndef __bitio__
#define __bitio__
#include <fstream>
using namespace std;
typedef unsigned char uint1;
typedef unsigned short uint2;
typedef unsigned int uint4;
class BitFileIn: public ifstream
{
public:
BitFileIn(const char* path);
~BitFileIn();
uint1 BitInput(bool& flag);
uint4 BitsInput(int count, bool& flag);
private:
uint1 mask;
uint1 rack;
};
class BitFileOut : public ofstream
{
public:
BitFileOut(const char* path);
~BitFileOut();
void BitOutput(uint1 bit);
void BitsOutput(uint4 code, uint4 count);
void close();
private:
uint1 mask;
uint1 rack;
};
#endif // ! __bitio__
bitio.cpp
#include "bitio.h"
#include <iostream>
using namespace std;
BitFileIn::BitFileIn(const char* path): ifstream(path,ios::binary)
{
mask = 0x80;
rack = 0;
}
BitFileIn::~BitFileIn()
{
ifstream::close();
}
uint1 BitFileIn::BitInput(bool& flag)
{
//Using flag to mark reaching the end
int value;
if (mask == 0x80) {
this->read(reinterpret_cast<char*>(&rack), 1);
if (this->eof()) { //if reach end
cerr << __func__ << "\tRead after the end!" << endl;
system("pause");
flag = true; //indicate reach the end
return 0;
}
}
value = mask & rack;
mask >>= 1;
if (mask == 0) { mask = 0x80; }
return ((value)?1:0);
}
uint4 BitFileIn::BitsInput(int count, bool& flag)
{
uint4 mask = 1L << (count - 1);
uint4 value = 0L;
while (mask != 0) {
if (this->BitInput(flag)) { value |= mask; }
mask >>= 1;
}
return value;
}
BitFileOut::BitFileOut(const char* path): ofstream(path, ios::binary)
{
mask = 0x80;
rack = 0;
}
BitFileOut::~BitFileOut()
{
this->close();
}
void BitFileOut::BitOutput(uint1 bit)
{
if (bit != 0) { rack |= mask; }
mask >>= 1;
if (mask == 0) {
this->write(reinterpret_cast<const char*>(&rack), 1);
//*(this) << rack;
rack = 0;
mask = 0x80;
}
}
void BitFileOut::BitsOutput(uint4 code, uint4 count)
{
uint4 mask = 1 << (count - 1);
while (mask != 0) {
this->BitOutput((code & mask) ? 1 : 0);
mask >>= 1;
}
}
void BitFileOut::close()
{
//output remaining bits
if (mask != 0x80) {
this->write(reinterpret_cast<const char*>(&rack), 1);
//*(this) << rack;
}
ofstream::close();
}
main.cpp
#define _CRT_SECURE_NO_WARNINGS
#include "bitio.h"
#include "lzw.h"
#include <iostream>
#include <string.h>
using namespace std;
#if 1
int main(int argc, char** argv)
{
if (argc < 2) {
cout << "usage: <filepath>" << endl;
system("pause");
exit(1);
}
ifstream file_in(argv[1], ios::binary);
BitFileOut bit_out("./compressed.dat");
if (!file_in.is_open()) {
cerr << "Can not open file!" << endl;
system("pause");
exit(1);
}
if (!bit_out.is_open()) {
cerr << "Can not create compressed file!" << endl;
system("pause");
exit(1);
}
if (LZWencode(file_in, bit_out)) { cout << "compress finish!" << endl; }
else { cout << "fail to compress" << endl; system("pause"); exit(1); }
file_in.seekg(0, 0);
file_in.seekg(0, ios::end);
int file_length = file_in.tellg();
cout << "The file length is:" << file_length << " Bytes" << endl;
file_in.close();
bit_out.close();
char h[64]("decode_");
char* outname = strcat(h, argv[1]);
ofstream file_out(outname,ios::binary);
BitFileIn bit_in("./compressed.dat");
if (!file_out.is_open()) {
cerr << "Can not open decode file!" << endl;
system("pause");
exit(1);
}
if (!bit_in.is_open()) {
cerr << "Can not create compressed file!" << endl;
system("pause");
exit(1);
}
if(LZWdecode(file_out, bit_in)){ cout << "compress finish!" << endl; }
else{ cout << "fail to decode" << endl; system("pause"); exit(1); }
bit_in.seekg(0, 0);
bit_in.seekg(0, ios::end);
int out_file_length = bit_in.tellg();
cout << "The compressed file length is:" << out_file_length << " Bytes" << endl;
bit_in.close();
file_out.close();
system("pause");
return 0;
}
#endif