前言
在之前文章中,笔者写过一篇关于Ozone EC方案设计的文章(Ozone的Erasure Coding方案设计),不过当时那篇文章讨论的EC设计方案主要在Container级别以及Block级别做EC实现的方案对比,社区并没有敲定选用哪种最终的具体方案设计。最近社区更新了Ozone EC最新的设计方案,在Block级别做最终的实现方式,本文笔者聊聊此方案的实现细节。
Ozone EC概述
说到EC以及Ozone的EC,笔者上篇文章做过对此的简单介绍,以及Ozone在Block level和Container level做EC实现的优劣势的对比。笔者个人更偏向于在Block层面做EC,而且在实现语义上也是更接近于HDFS的EC实现。
在EC模式下,最重要的一个区别点在于一个block的数据存储将会变为striped的模式,即横向式的条带式的存储,而不是原来的连续存储方式。简单理解,就是一个block块的数据会被切为很多小的段,然后分别存储在不同的Containerer里面。如下图所示:
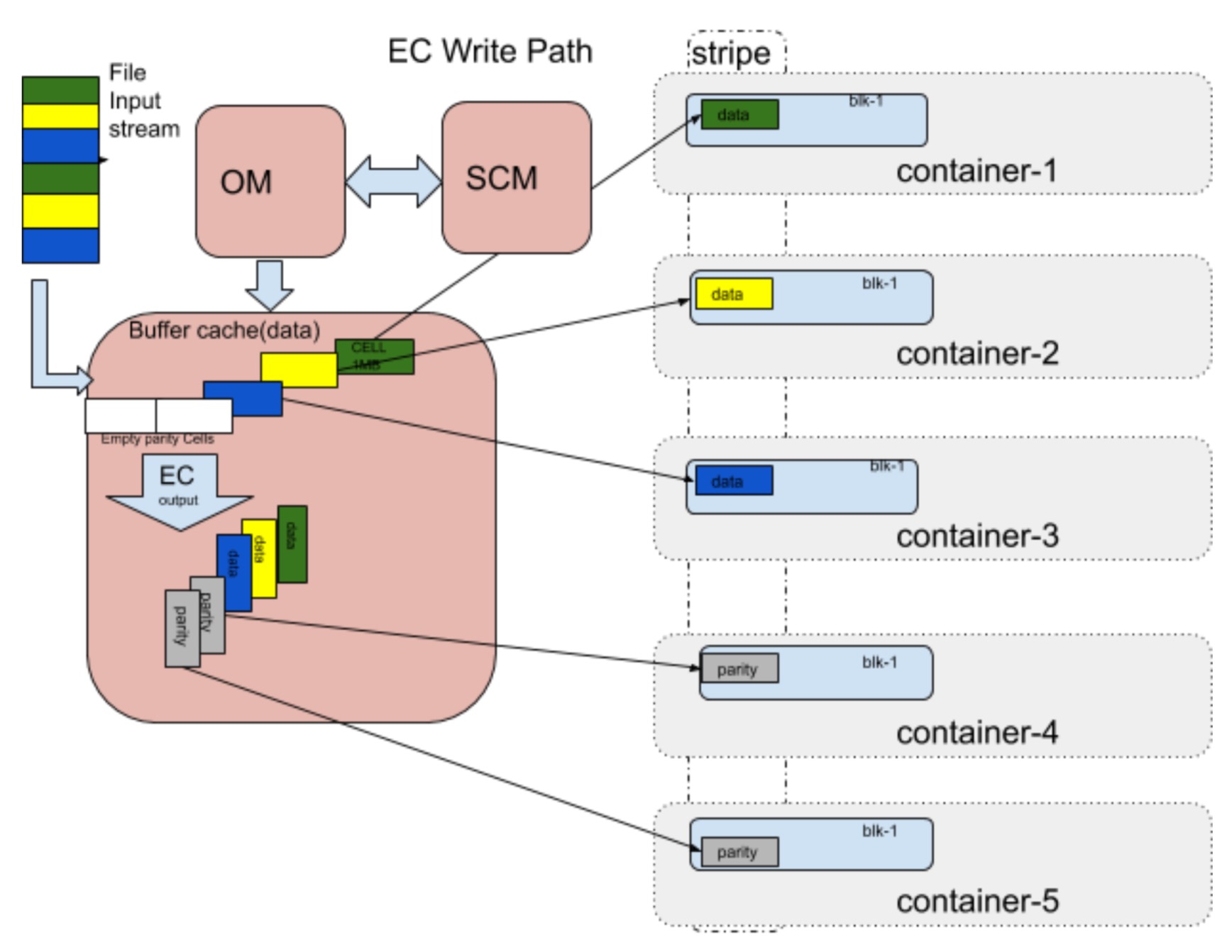
上图中灰色块的部分属于校验快,由数据块部分加密生成而来,用于EC数据的恢复。从上图Ozone EC数据的存储模式来看,这里的一个明显的变化是一个block将会以多片段的形式分散存储在不同的Container里,这些Container构成了一个Container Group组。
于是这里会有如下的对比区分:
- Ozone原生(数据连续)存储:一个Block存储在一个Container里,然后以多副本的方式存储在多个Container里。
- Ozone EC(数据条带式)存储一个Block以多个片段的方式存储在一个Container组里。
因此在这里,我们要重点谈论谈论Container组的概念,后续Ozone EC的block数据都要依赖这个Container组进行。
基于CGI的EC block数据的读写
在非EC模式下,block的写入过程比较简单,选择一个Container进行块的分配即可,此时block和Container就是1对1 的关系。但是在EC模式下,一个block可是要对应一组Container的,这个时候有什么高效的办法能做这样的关系映射呢?给每个block存储一个Container列表?
社区设计了一个Container Group的概念,以及给每个Group定义了一个Id(全称Container Group Id, CGI),然后通过这个CGI