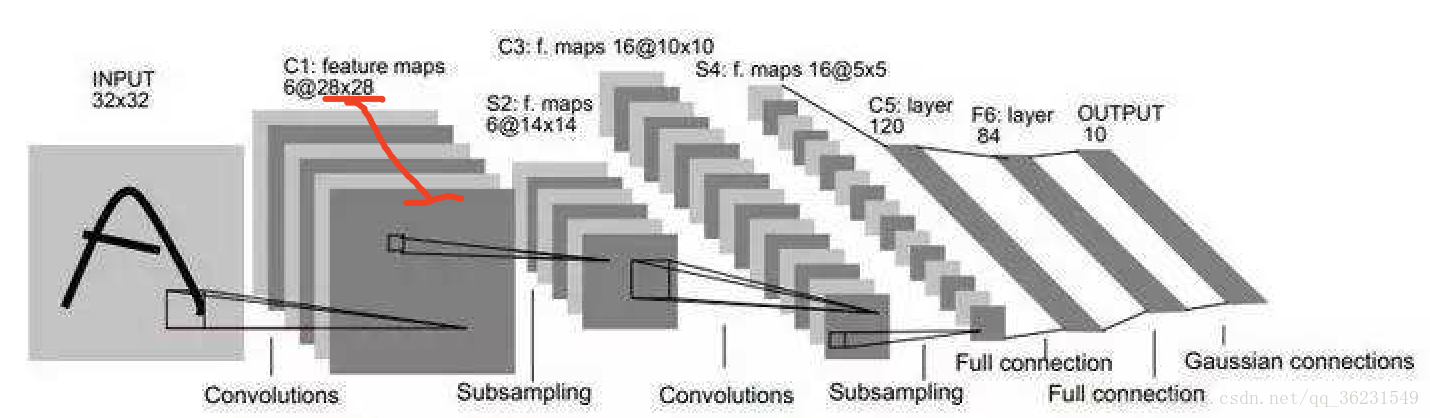
feature map、卷积核、卷积核个数、filter、channel的概念解释
feather map的理解
在cnn的每个卷积层,数据都是以三维形式存在的。你可以把它看成许多个二维图片叠在一起(像豆腐皮一样),其中每一个称为一个feature map。
feather map 是怎么生成的?
输入层:在输入层,如果是灰度图片,那就只有一个feature map;如果是彩色图片,一般就是3个feature map(红绿蓝)。
其它层:层与层之间会有若干个卷积核(kernel)(也称为过滤器),上一层每个feature map跟每个卷积核做卷积,都会产生下一层的一个feature map,有N个卷积核,下层就会产生N个feather map。
多个feather map的作用是什么?
在卷积神经网络中,我们希望用一个网络模拟视觉通路的特性,分层的概念是自底向上构造简单到复杂的神经元。楼主关心的是同一层,那就说说同一层。
我们希望构造一组基,这组基能够形成对于一个事物完备的描述,例如描述一个人时我们通过描述身高/体重/相貌等,在卷积网中也是如此。在同一层,我们希望得到对于一张图片多种角度的描述,具体来讲就是用多种不同的卷积核对图像进行卷,得到不同核(这里的核可以理解为描述)上的响应,作为图像的特征。他们的联系在于形成图像在同一层次不同基上的描述。
下层的核主要是一些简单的边缘检测器(也可以理解为生理学上的simple cell)。
上层的核主要是一些简单核的叠加(或者用其他词更贴切),可以理解为complex cell。
多少个Feature Map?真的不好说,简单问题少,复杂问题多,但是自底向上一般是核的数量在逐渐变多(当然也有例外,如Alexnet),主要靠经验。
卷积核的理解
卷积核在有的文档里也称为过滤器(filter):
- 每个卷积核具有长宽深三个维度;
- 在某个卷积层中,可以有多个卷积核:下一层需要多少个feather map,本层就需要多少个卷积核。
卷积核的形状
每个卷积核具有长、宽、深三个维度。在CNN的一个卷积层中:
- 卷积核的长、宽都是人为指定的,长X宽也被称为卷积核的尺寸,常用的尺寸为3X3,5X5等;
- 卷积核的深度与当前图像的深度(feather map的张数)相同,所以指定卷积核时,只需指定其长和宽 两个参数。例如,在原始图像层 (输入层),如果图像是灰度图像,其feather map数量为1,则卷积核的深度也就是1;如果图像是grb图像,其feather map数量为3,则卷积核的深度也就是3.
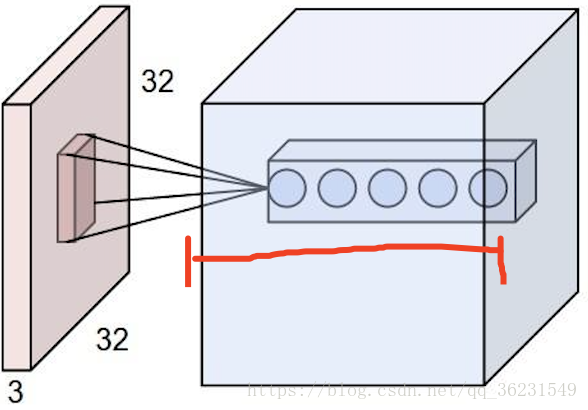
卷积核个数的理解
如下图红线所示:该层卷积核的个数,有多少个卷积核,经过卷积就会产生多少个feature map,也就是下图中 `豆腐皮儿`的层数、同时也是下图`豆腐块`的深度(宽度)!!这个宽度可以手动指定,一般网络越深的地方这个值越大,因为随着网络的加深,feature map的长宽尺寸缩小,本卷积层的每个map提取的特征越具有代表性(精华部分),所以后一层卷积层需要增加feature map的数量,才能更充分的提取出前一层的特征,一般是成倍增加(不过具体论文会根据实验情况具体设置)!
卷积核的运算过程
例如输入224x224x3(rgb三通道),输出是32位深度,卷积核尺寸为5x5。
那么我们需要32个卷积核,每一个的尺寸为5x5x3(最后的3就是原图的rgb位深3),每一个卷积核的每一层是5x5(共3层)分别与原图的每层224x224卷积,然后将得到的三张新图叠加(算术求和),变成一张新的feature map。 每一个卷积核都这样操作,就可以得到32张新的feature map了。 也就是说:
不管输入图像的深度为多少,经过一个卷积核(filter),最后都通过下面的公式变成一个深度为1的特征图。不同的filter可以卷积得到不同的特征,也就是得到不同的feature map。。。
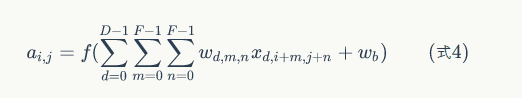

filter的理解
filter有两种理解:
在有的文档中,一个filter等同于一个卷积核:只是指定了卷积核的长宽深;
而有的情况(例如tensorflow等框架中,filter参数通常指定了卷积核的长、宽、深、个数四个参数),filter包含了卷积核形状和卷积核数量的概念:即filter既指定了卷积核的长宽深,也指定了卷积核的数量。
理解tensorflow等框架中的参数 channel(feather map、卷积核数量)
在深度学习的算法学习中,都会提到 channels 这个概念。在一般的深度学习框架的 conv2d 中,如 tensorflow 、mxnet,channels 都是必填的一个参数。
channels 该如何理解?先看一看不同框架中的解释文档。
首先,是 tensorflow 中给出的,对于输入样本中 channels 的含义。一般的RGB图片,channels 数量是 3 (红、绿、蓝);而monochrome图片,channels 数量是 1 。
channels : Number of color channels in the example images. For color images, the number of channels is 3 (red, green, blue). For monochrome images, there is just 1 channel (black). ——tensorflow
其次,mxnet 中提到的,一般 channels 的含义是,每个卷积层中卷积核的数量。
channels (int) : The dimensionality of the output space, i.e. the number of output channels (filters) in the convolution. ——mxnet
为了更直观的理解,下面举个例子,图片使用自 吴恩达老师的深度学习课程 。
如下图,假设现有一个为 6×6×36×6×3 的图片样本,使用 3×3×33×3×3 的卷积核(filter)进行卷积操作。此时输入图片的 channels 为 33 ,而卷积核中的 in_channels 与 需要进行卷积操作的数据的 channels 一致(这里就是图片样本,为3)。
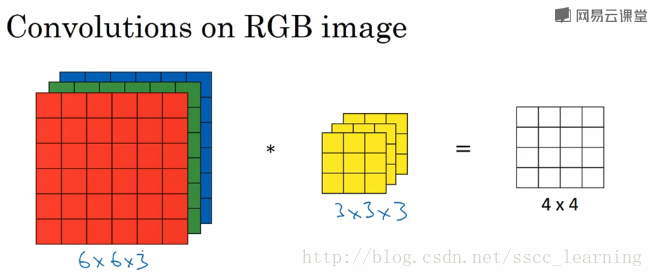
接下来,进行卷积操作,卷积核中的27个数字与分别与样本对应相乘后,再进行求和,得到第一个结果。依次进行,最终得到 4×4 的结果。
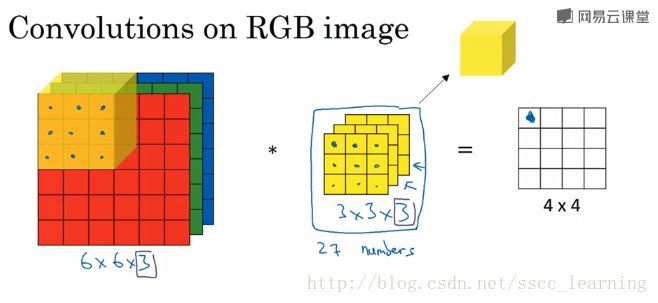
上面步骤完成后,由于只有一个卷积核,所以最终得到的结果为 4×4×1 , out_channels 为 1 。
在实际应用中,都会使用多个卷积核。这里如果再加一个卷积核,就会得到 4×4×2 的结果。
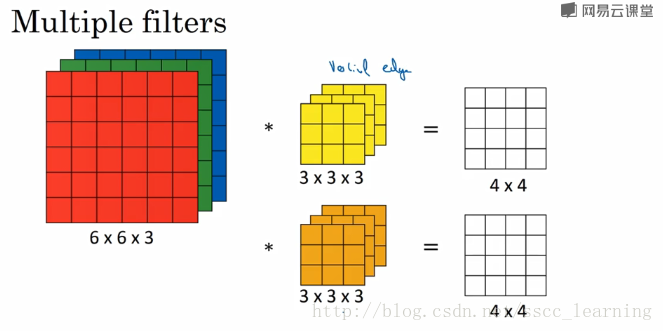
总结一下,我偏好把上面提到的 channels 分为三种:
- 最初输入的图片样本的
channels ,取决于图片类型,比如RGB;
-
卷积核中的
in_channels ,就是要操作的图像数据的feather map张数,也就是卷积核的深度。(刚刚2中已经说了,就是上一次卷积的 out_channels ,如果是第一次做卷积,就是1中样本图片的 channels) ;
- 卷积操作完成后输出的
out_channels ,取决于卷积核的数量(下层将产生的feather map数量)。此时的 out_channels 也会作为下一次卷积时的卷积核的 in_channels。
说到这里,相信已经把 channels 讲的很清楚了。在CNN中,想搞清楚每一层的传递关系,主要就是 height,width 的变化情况,和 channels 的变化情况。
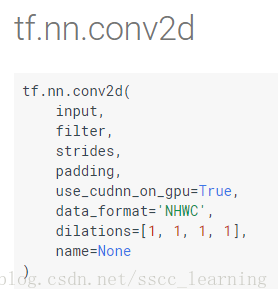
最后再看看 tensorflow 中 tf.nn.conv2d 的 input 和 filter 这两个参数。
input : [batch, in_height, in_width, in_channels] ,
filter : [filter_height, filter_width, in_channels, out_channels(卷积核的数量/下层将产生的feather map数量)] 。
里面的含义是不是很清楚了?
CNN的学习过程:更新卷积核的值(更新提取的图像特征)
因为卷积核实际上就是如3x3,5x5这样子的权值(weights)矩阵。我们的网络要学习的,或者说要确定下来的,就是这些权值(weights)的数值。网络不断前后向的计算学习,一直在更新出合适的weights,也就是一直在更新卷积核们。卷积核在更新了,学习到的特征也就被更新了(因为卷积核的值(weights)变了,与上一层的map卷积计算的结果也就变了,得到的新map就也变了。)。对分类问题而言,目的就是:对图像提取特征,再以合适的特征来判断它所属的类别。类似这种概念:你有哪些个子的特征,我就根据这些特征,把你划分到某个类别去。
这样就很说的通了,卷积神经网络的一整套流程就是:更新卷积核参数(weights),就相当于是一直在更新所提取到的图像特征,以得到可以把图像正确分类的最合适的特征们。(一句话:更新weights以得到可以把图像正确分类的特征。)