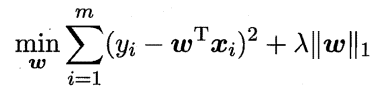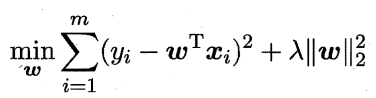-
重要性:调参带来的效果增幅是非常有限的,但特征工程的好坏往往会决定了最终的排名和成绩。特征工程可以将数据转换为能更好地表示潜在问题的特征,从而提高机器学习的性能
-
具体情况具体分析:不同模型对于数据集的要求不同,因此处理完的数据应该分开来存储。

-
缺失:加入先验知识 异常:清除噪声
-
集中:数据集中(归一化、标准化)、变量集中(特征筛选、降维)
-
有价值:数据有价值(数据分桶)、变量有价值(特征构造)
一、自动化EDA
# pip install pandas_profiling
import pandas as pd
import seaborn as sns
mpg = sns.load_dataset('mpg')
mpg.head()
from pandas_profiling import ProfileReport
profile = ProfileReport(mpg, title='MPG Pandas Profiling Report', explorative = True)
profile
二、准备工作
(一)合并数据
# 训练集和测试集放在一起,方便构造特征
Train_data['train']=1
Test_data['train']=0
data = pd.concat([Train_data, Test_data], ignore_index=True) # ignore_index=True被拼接的两个表的索引都不重要
#
df2 非空DataFrame
df0=pd.DataFrame(columns=df2.columns) # concat时如果df0是空的会报错
df1=pd.concat([df0,df2])
(二)groupby聚合观察数据特征
#求分组后y1的min,y2的max,y3的std
df1=df.groupby(['x1','x2','x3'],as_index=False)['y1','y2','y3'].agg({'y1':min,'y2':max,'y3':np.std})
#求分组后y1的min
df1=df.groupby(['x1','x2','x3'],as_index=False)['y1'].min()
(三)去重
data2=data.drop_duplicates(subset=['x2','x3']).reset_index(drop=True) #去重之后索引会改变,需要重置。并且一定要改名字,防止重复累积计算。
df.drop_duplicates(keep='first',inplace=True) #inplace=True是直接在df的基础上操作,最好还是构造新表
(四)按列排序
df2=df1.sort_index(by=['x1','x2']).reset_index(drop=True) #排序后要重置索引
(五)随机抽数
df2=df1.sample(n=8000,random_state=123).reset_index(drop=True) #抽数后要重置索引
(六)保存、创建、与拼接
包含大数据量的计算,如果能够持久化存储,一定要存下来,节省下次计算的大量的宝贵时间。
# 保存
data.to_csv('data.csv',encoding='utf-8',index_label=False,header=1) #不包含索引列,包含列名
# 创建新表
df=pd.DataFrame() #空表
df['a']=range(1,100)
df['b']=0
## 等同于
df=pd.DataFrame({'a':range(1,100),'b':0})
# 拼接
#列相同,做行连接
df = pd.concat([df1, df2, df3]) #keys=['x', 'y', 'z']识别来源于哪张表
#列连接,推荐用merge
df = pd.concat([df1, df2], axis=1) #join='inner'/'outer':交集/并集
df0=pd.merge(df,df_temp2[['device_id','ds','rw']],how='right',on=['device_id','ds','rw']) #从df中删除这异常的13个片段
(七)转换数据格式
df[2] = df[2].astype('int')
在使用Toad包时,需要把string转换成float,如果不转换会报错,怎样找到报错的变量是哪个,并一次性记录下来?
list_drop=[]
for x in df_v1.columns:
if 'n' in df_v1[x].value_counts():
list_drop.append(x)
print(df_v1[x].value_counts())
print('\n')
print(list_drop)
(八)删除列
to_drop = ['APP_ID_C','month'] # 去掉ID列和month列
data.drop(to_drop,axis=1) # 用新的数据
三、特征中的异常值处理
- 作用:去除噪声
- 步骤:01-箱线图、直方图看分布;02-删:箱线图公式删除异常值,真实场景中除了设置scale之外,更重要的是根据先验知识;03-不删:尝试箱线图或先验的异常值截断、box-cox的幂变换/对数变换/导数变换处理有偏分布
(一)箱线图公式处理异常值
1. 删除
- 删除需谨慎,除非是根据先验知道数据确实异常,否则随意删除很容易改变数据分布。并且只能对训练集删除,测试集不能删。
def outliers_proc(data, col_name, scale=1.5):
"""
用于清洗异常值,默认用 box_plot(scale=1.5)进行清洗(scale=1.5表示异常值,scale=3表示极端值)
:param scale: 尺度
"""
def box_plot_outliers(data_ser, box_scale):
"""
利用箱线图去除异常值
:param data_ser: 接收 pandas.Series 数据格式
:param box_scale: 箱线图尺度,
:return:
"""
iqr = box_scale * (data_ser.quantile(0.75) - data_ser.quantile(0.25))
val_low = data_ser.quantile(0.25) - iqr
print('val_low:',val_low)
val_up = data_ser.quantile(0.75) + iqr
print('val_up:',val_up)
rule_low = (data_ser < val_low) # 下离群点
rule_up = (data_ser > val_up) # 上离群点
return (rule_low, rule_up), (val_low, val_up)
data_n = data.copy()
data_series = data_n[col_name]
rule, value = box_plot_outliers(data_series, box_scale=scale)
index = np.arange(data_series.shape[0])[rule[0] | rule[1]]
print("Delete number is: {}".format(len(index)))
data_n = data_n.drop(index)
data_n.reset_index(drop=True, inplace=True)
print("Now row number is: {}".format(data_n.shape[0]))
index_low = np.arange(data_series.shape[0])[rule[0]]
outliers = data_series.iloc[index_low]
print('\n',"Description of data less than the lower bound is:")
print(pd.Series(outliers).describe())
index_up = np.arange(data_series.shape[0])[rule[1]]
outliers = data_series.iloc[index_up]
print('\n',"Description of data larger than the upper bound is:")
print(pd.Series(outliers).describe())
fig, ax = plt.subplots(1, 2, figsize=(10, 7))
sns.boxplot(y=data[col_name], data=data, palette="Set3", ax=ax[0])
sns.boxplot(y=data_n[col_name], data=data_n, palette="Set3", ax=ax[1])
return data_n
2. 截尾
def outliers_proc(data, col_name, scale=3):
"""
用于截尾异常值, 默认用box_plot(scale=3)进行清洗
param:
data:接收pandas数据格式
col_name: pandas列名
scale: 尺度
"""
data_col = data[col_name]
Q1 = data_col.quantile(0.25) # 0.25分位数
Q3 = data_col.quantile(0.75) # 0,75分位数
IQR = Q3 - Q1
data_col[data_col < Q1 - (scale * IQR)] = Q1 - (scale * IQR)
data_col[data_col > Q3 + (scale * IQR)] = Q3 + (scale * IQR)
return data[col_name]
num_data['power'] = outliers_proc(num_data, 'power')
四、缺失值处理
作用:加入先验知识
方法:要么不处理,要么删补分(删除,插值补全,单独分箱)
模型自带的缺失值处理:01-xgboost包含缺失值处理,但是不妨碍要做缺失值处理;02-OneHot的时候,会把空值处理成全0的一种表示。
注意点:可以在特征选择后进行处理,也可以提前处理,因为删除可能会影响数据分布
(一)查看缺失值
df.info()
df.isnull().sum()
注:有些缺失值会于隐藏类别型变量中
df.x1.value_counts() # 发现缺失值被表示成-
df['x1'].replace('-', np.nan, inplace=True)
(二)处理缺失值
1. 删除
一般情况下一定不能随便删除异常值,因为对于分类型变量,删除很可能影响其分布。除非缺失值很少。
- 如果缺失的太多,可以考虑删除该列
- 如果很小一般选择填充
- 如果使用lgb等树模型可以直接空缺,让树自己去优化
# dropna
df=df.dropna().reset_index(drop=True)
df['x1'].dropna(inplace=True)
df.dropna(axis=0, how='any', subset=['x1'],inplace=True) #在原数据上进行操作
# notnull
data2= data1[data1.x1.notnull()]
# default ‘any’指带缺失值的所有行;'all’指清除全是缺失值的行
2. 不处理
xgboost建模时会自动处理缺失值,但是前提是训练集和预测集的分布相同。
3. 插值补全
包括均值/中位数/众数/建模预测/多重插补/压缩感知补全/矩阵补全等
# 删除重复值
data.drop_duplicates()
# dropna()可以直接删除缺失样本,但是有点不太好
# 填充固定值
train_data.fillna(0, inplace=True) # 填充 0
data.fillna({0:1000, 1:100, 2:0, 4:5}) # 可以使用字典的形式为不用列设定不同的填充值
train_data.fillna(train_data.mean(),inplace=True) # 填充均值
train_data.fillna(train_data.median(),inplace=True) # 填充中位数
train_data.fillna(train_data.mode(),inplace=True) # 填充众数
train_data.fillna(method='pad', inplace=True) # 填充前一条数据的值,但是前一条也不一定有值
train_data.fillna(method='bfill', inplace=True) # 填充后一条数据的值,但是后一条也不一定有值
"""插值法:用插值法拟合出缺失的数据,然后进行填充。"""
for f in features:
train_data[f] = train_data[f].interpolate()
"""填充KNN数据:先利用knn计算临近的k个数据,然后填充他们的均值"""
from fancyimpute import KNN
train_data_x = pd.DataFrame(KNN(k=6).fit_transform(train_data_x), columns=features)
# 还可以填充模型预测的值
4. 分箱
缺失值一个箱
data.x1 = data.x1.fillna(-1) # x1一般情况下只有正值
test.x1 = test.x1.fillna(-1)
(三)缺失值可视化
# 白线越多,缺失越多
import missingno as msno
msno.matrix(data.sample(500))
# 热度值越大,两个特征同时缺失的比例越大
msno.heatmap(data,figsize=(16, 7))#figsize是指图的大小
# 查看缺失的数量和比例
msno.bar(Test_data.sample(1000))
五、因变量的处理
(一)画直方图观察拟合状况
import scipy.stats as st
y = Train_data['price']
plt.figure(1); plt.title('Johnson SU')
sns.distplot(y, kde=False, fit=st.johnsonsu) # 不画核密度曲线
plt.figure(2); plt.title('Normal')
sns.distplot(y, kde=False, fit=st.norm)
plt.figure(3); plt.title('Log Normal')
sns.distplot(y, kde=False, fit=st.lognorm)
# 价格不服从正态分布,所以在进行回归之前,它必须进行转换。
# 虽然对数变换做得很好,但最佳拟合是无界约翰逊分布
# 不过约翰逊分布的逆转换很麻烦,一般情况不会用
(二)box-cox幂变换
from scipy.stats import boxcox # 1:确定lambda
from scipy.special import boxcox, inv_boxcox # 2:转化和逆转化
#01-确定幂数
y_box, lambda0 = boxcox(y, lmbda=None, alpha=None)
#02-转换幂次
y_box=boxcox(y,2.5) #正态变化就是2.5
#03-若是因变脸,最后估计的时候需要转换回去
#如果在训练集Box-Cox变换时使用了C常数进行了自变量的非零处理,那么还需要再反变换之后减去这个C常数
y_predict=inv_boxcox(y_box, lambda0)
(三)其他变换
- log变换
import numpy as np
log_y=np.log(y)
- 导数变换
六、特征构造
作用:增强数据的表达
(一)构造新特征
借助背景知识,发挥想象力,尽可能多的创造特征
- 数值特征:加减组合
- 分类特征:交叉组合
- 时间特征:时间差,使用时间分箱–分箱之后可以独热编码–分箱之后也可以分组统计描述统计量,淡旺季独热编码
【重命名变量】
df.rename(columns={'a1':'b1','a2':'b2'},inplace=True)
【apply+lambda】
df['x2']=df['x1'].apply(lambda x:1 if x>0 else 0) #if-else
df['x2']=df['x1'].apply(lambda x:10-df.x3) #运算
def function(x): #自定义函数
return y
df['x1'] = df.x2.apply(lambda x:function(x))
df['x3']=df.apply(lambda y:y['x1']/y['x2'], axis=1) #涉及两列,必须有axis=1
df['x3']=df.x1/df.x2
【一阶差分】
df['x_delta']=pd.DataFrame(df.x.diff())
【变量在特定行赋值】
data.loc[2:10,'x1']=3
【特征的描述统计量计算】
# 计算某品牌的销售统计量,同学们还可以计算其他特征的统计量
# 这里要以 train 的数据计算统计量
Train_gb = Train_data.groupby("brand") #不是表格,但是可以用来遍历,根据类别分类
all_info = {} #用来记录各种特征统计量
for kind, kind_data in Train_gb:
info = {}
kind_data = kind_data[kind_data['price'] > 0] #筛选数据减少计算成本
info['brand_amount'] = len(kind_data)
info['brand_price_max'] = kind_data.price.max()
info['brand_price_median'] = kind_data.price.median()
info['brand_price_min'] = kind_data.price.min()
info['brand_price_sum'] = kind_data.price.sum()
info['brand_price_std'] = kind_data.price.std()
info['brand_price_average'] = round(kind_data.price.sum() / (len(kind_data) + 1), 2)
all_info[kind] = info #用两层嵌套字典来记录
brand_fe = pd.DataFrame(all_info).T.reset_index().rename(columns={"index": "brand"})
data = data.merge(brand_fe, how='left', on='brand') #列合并用merge,左连接
【时间特征】
# 选出淡旺季
low_seasons = ['3', '6', '7', '8']
time_data['is_low_seasons'] = time_data['creatDate'].apply(lambda x: 1 if str(x)[5] in low_seasons else 0)
time_data = pd.get_dummies(time_data, columns=['is_low_seasons'])# 独热,构造出稀疏向量
(二.a)连续型变量:离散化——数据分桶
1做数据分桶的原因:
模型表达能力的提升( 多变量拟合、特征交叉的运用);模型稳定性提升(对于异常值的鲁棒性、对于变量值改变的稳定性);运算速度更快。
- 离散后稀疏向量内积乘法运算速度更快,计算结果也方便存储,容易扩展;
- 离散后的特征对异常值更具鲁棒性,如 age>30 为 1 否则为 0,对于年龄为 200 的也不会对模型造成很大的干扰;
- LR 属于广义线性模型,表达能力有限,经过离散化后,每个变量有单独的权重,这相当于引入了非线性,能够提升模型的表达能力,加大拟合;
- 离散后特征可以进行特征交叉,提升表达能力,由 M+N 个变量编程 M*N 个变量,进一步引入非线形,提升了表达能力;
- 特征离散后模型更稳定,如用户年龄区间,不会因为用户年龄长了一岁就变化
当然还有很多原因,LightGBM 在改进 XGBoost 时就增加了数据分桶,增强了模型的泛化性
2数据分桶的方法
等频分桶、等距分桶、Best-KS分桶(类似利用基尼指数进行二分类)、卡方分桶
# 数据分桶 以 power 为例
# 这时候我们的缺失值也进桶了
data['power_bin'] = pd.cut(data['power'], bin, labels=False)
data[['power_bin', 'power']].head()
# 定义箱子的边
bins = [18, 25, 35, 60, 100]
bins = [i*10 for i in range(31)]
# 分割数据
cats = pd.cut(ages, bins) #right=False左闭右开
group_names = ['Youth', 'YonngAdult', 'MiddleAged', 'Senior']
data = pd.cut(ages, bins, labels=group_names)
print(cats) # 这是个categories对象 通过bin分成了四个区间, 然后返回每个年龄属于哪个区间
# codes属性
print(cats.codes) # 这里返回一个数组,指明每一个年龄属于哪个区间
print(cats.categories)
print(pd.value_counts(cats)) # 返回结果是每个区间年龄的个数
# 4个等长的箱子
data2 = np.random.rand(20)
print(pd.cut(data2, 4, precision=2)) # precision=2 将十进制精度限制在2位
# qcut基于样本分位数进行分箱
cats = pd.qcut(data3, 4)
(二.b)连续型变量:分布调整
BOX-COX 转换调整有偏分布、正态分布标准化,幂律分布取 log 等
Train_data['power'].plot.hist() #先看数据分布
from sklearn import preprocessing
min_max_scaler = preprocessing.MinMaxScaler()
data['power'] = np.log(data['power'] + 1)
data['power'] = ((data['power'] - np.min(data['power'])) / (np.max(data['power']) - np.min(data['power'])))
data['power'].plot.hist()
(二.c)连续型变量:标准化/归一化
对于NN回归和线性回归,需要标准化/归一化处理
在这里插入代码片
(三)分类型变量:one-hot编码
OneHot不要太早,否则有些特征就没法提取潜在信息了
hot_features = ['bodyType', 'fuelType', 'gearbox', 'notRepairedDamage']
cat_data_hot = pd.get_dummies(cat_data, columns=hot_features)
高势集特征model,也就是类别中取值个数非常多的, 一般可以使用聚类的方式,然后独热,这里就采用了这种方式:
#KMeans聚类和层次聚类都可以尝试
from scipy.cluster.hierarchy import linkage, dendrogram
#from sklearn.cluster import AgglomerativeClustering
from sklearn.cluster import KMeans
ac = KMeans(n_clusters=3)
ac.fit(model_price_data)
model_fea = ac.predict(model_price_data)
plt.scatter(model_price_data[:,0], model_price_data[:,1], c=model_fea)
cat_data_hot['model_fea'] = model_fea
cat_data_hot = pd.get_dummies(cat_data_hot, columns=['model_fea'])
决策树模型不推荐对离散特征进行 one-hot,主要有两个原因:
其本质在于,特征的预测能力被人为的拆分成多份,每一份与其他特征竞争最优划分节点时都会失败,所以特征的重要性会比实际值低。
- 会产生样本不平衡问题,本来特征是:红的白的绿的,现在变为是否红的、是否白的、是否绿的。。只有少量样本为 1,大量样本为 0。这种特征的危害是,本来节点的划分增益还可以,但是拆分后的特征,占总样本的比例小的特征,所以无论增益多大,乘以该比例之后会很小,占比例大的特征其增益也几乎为 0,影响模型学习;
- 决策树依赖的是数据的统计信息,one-hot 会把数据切分到零散的小空间上,在这些零散的小空间上,统计信息是不准确的,学习效果变差。
但是实际处理还是要多尝试,比较模型效果。
(四)匿名特征的处理
有些比赛的特征是匿名特征,这导致我们并不清楚特征相互直接的关联性,这时我们就只有单纯基于特征进行处理,比如装箱,groupby,agg 等这样一些操作进行一些特征统计,此外还可以对特征进行进一步的 log,exp 等变换,或者对多个特征进行四则运算(如上面我们算出的使用时长),多项式组合等然后进行筛选。由于特性的匿名性其实限制了很多对于特征的处理,当然有些时候用 NN 去提取一些特征也会达到意想不到的良好效果。
七、特征筛选(模型选择)
Step1-过滤式——初步观察,是训练模型前根绝数据波动和特征相关性,来进行特征选择;
Step2-包裹式——模型实验,是选定学习器,对特征进行打分排序;
(0)准备工作
根据前面的缺失值、异常值情况先初步选出备选特征
numerical_cols = Train_data.select_dtypes(exclude = 'object').columns
categorical_cols = Train_data.select_dtypes(include = 'object').columns
feature_cols = [col for col in numerical_cols if col not in ['SaleID','name','regDate','creatDate','price','model','brand','regionCode','seller']]
feature_cols = [col for col in feature_cols if 'Type' not in col] #筛选掉包含‘Type’字段的列
# data.select_dtypes().columns
# 用生成器来进一步筛选特征符合的条件
(一)方法
1. 过滤式
- 波动性:对于数值型特征,方差很小的特征可以不要,因为太小没有什么区分度,提供不了太多的信息,对于分类特征,也是同理,取值个数高度偏斜的那种可以先去掉。
- 相关性:根据与目标的相关性等选出比较相关的特征。离散与离散:卡方检验、相关性信息增益和信息增益比(可以通过决策树模型来评估来看);连续与连续的线性相关关系:person系数。筛选出与因变量相关程度高的自变量,删除相关性很高的自变量。
相关性分析:相关系数+热力图
- 相关系数:pearson相关系数只对线性关系敏感,连续数据,正态分布,线性关系,用pearson相关系数是最恰当;其他情况用spearman系数。
#打印相关系数
print(data['power'].corr(data['price'], method='spearman'))
#相关系数排序图
corr=data['power'].corr(data['price'], method='spearman')
plt.tight_layout()
#热力图
data_numeric = data[['power', 'kilometer', 'brand_amount', 'brand_price_average',
'brand_price_max', 'brand_price_median']]
correlation = data_numeric.corr()
f , ax = plt.subplots(figsize = (7, 7))
plt.title('Correlation of Numeric Features with Price',y=1,size=16)
sns.heatmap(correlation,square = True, vmax=0.8)
2. 包裹式
- 方法:01-前向选择,结合边际效益图确定最佳的特征;02-模型自带特征重要性函数。
- 技巧:基于树的方法比较易于使用,因为他们对非线性关系的建模比较好,并且不需要太多的调试。
【随机森林:根据R^2对特征打分并排序,自己写】
from sklearn.model_selection import cross_val_score, ShuffleSplit
from sklearn.ensemble import RandomForestRegressor
from sklearn.model_selection import KFold
X = select_data.iloc[:, :-1]
Y = select_data['price']
names = select_data.columns
rf = RandomForestRegressor(n_estimators=20, max_depth=4)
kfold = KFold(n_splits=5, shuffle=True, random_state=7)
scores = []
for column in X.columns:
print(column)
tempx = X[column].values.reshape(-1, 1)
score = cross_val_score(rf, tempx, Y, scoring="r2",cv=kfold)
scores.append((round(np.mean(score), 3), column))
print(sorted(scores, reverse=True))
【封装】
# k_feature 太大会很难跑,没服务器,所以提前 interrupt 了
from mlxtend.feature_selection import SequentialFeatureSelector as SFS
from sklearn.linear_model import LinearRegression
sfs = SFS(LinearRegression(),k_features=10,forward=True,floating=False,scoring = 'r2',cv = 0)
x = data.drop(['price'], axis=1)
x = x.fillna(0)
y = data['price']
sfs.fit(x, y)
sfs.k_feature_names_
# 画出来,可以看到边际效益
from mlxtend.plotting import plot_sequential_feature_selection as plot_sfs
import matplotlib.pyplot as plt
fig1 = plot_sfs(sfs.get_metric_dict(), kind='std_dev')
plt.grid() #设置网格线
plt.show()
【xgboost:自带特征重要性排序】
# 下面再用xgboost跑一下
from xgboost import XGBRegressor
from xgboost import plot_importance
xgb = XGBRegressor()
xgb.fit(X, Y)
plt.figure(figsize=(20, 10))
plot_importance(xgb)
plt.show()
3. 嵌入式(嵌入惩罚项)
from sklearn.linear_model import LinearRegression, Ridge,Lasso
models = [LinearRegression(), Ridge(), Lasso()]
result = dict() #用字典来记录三种模型的差异
for model in models:
model_name = str(model).split('(')[0]
scores = cross_val_score(model, X=train_X, y=train_y, verbose=0, cv=5, scoring='r2')
result[model_name] = scores
参考:https://blog.csdn.net/weixin_43374551/article/details/83688913
4. PCA降维(特征压缩)
- 优点:减少需要分析的指标,而且尽可能多的保持原来数据的信息
- 缺点:特征选择是从已存在的特征中选取携带信息最多的,选完之后的特征依然具有可解释性,而PCA,将已存在的特征压缩,降维完毕后不是原来特征的任何一个,也就是PCA降维之后的特征我们根本不知道什么含义了。
from sklearn.decomposition import PCA
pca = PCA(n_components=10)
X_new = pca.fit_transform(X)
"""查看PCA的一些属性"""
print(X_new.shape) # (200000, 10)
print(pca.explained_variance_) # 属性可以查看降维后的每个特征向量上所带的信息量大小(可解释性方差的大小)
print(pca.explained_variance_ratio_) # 查看降维后的每个新特征的信息量占原始数据总信息量的百分比
print(pca.explained_variance_ratio_.sum()) # 降维后信息保留量
(二)平衡模型复杂度与拟合优度的统计量
1. 原理
模型越复杂,拟合优度往往越高,但是很容易造成过拟合,AIC和BIC可以衡量这种平衡度。AIC和BIC越小越好,希望在拟合优秀的情况下特征个数尽可能少。前一项相同,后一项的惩罚项稍有不同。

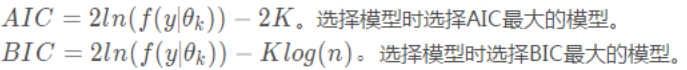
当n>=8时,klog(n)>=2k,BIC相比AIC在大数据量时对模型参数惩罚得更多,导致BIC更倾向于选择参数少的简单模型。
2.Python实现
#AIC
def aic(y,y_pred,k):
resid = y - y_pred.ravel()
sse = sum(resid ** 2)
AIC = 2*np.log(sse)-2*k
return AIC
#BIC
def bic(y,y_pred,k,n):
resid = y - y_pred.ravel()
sse = sum(resid ** 2)
BIC = 2*np.log(sse)-k*np.log(n)
return BIC
参考文章:https://blog.csdn.net/algorithmPro/article/details/105608756