nnU-Net:一种基于深度学习的自配置生物医学图像分割方法
Results
nnU-Net的自动配置基于将领域知识提取成三个参数组:固定的、基于规则的和经验的参数。
-
收集不需要在数据集之间进行调整的设计决策,并确定稳健的通用配置(“fixed parameters”)。
-
对于尽可能多的剩余决策,以启发式规则的形式,制定特定数据集属性(“dataset fingerprint”)(包括图像大小、体素间距信息或类别比率等关键属性)和设计选择(“pipeline fingerprint”)之间的显式依赖关系,以实现几乎即时的适应应用(“rule-based parameters”)。
-
仅从数据中凭经验学习剩余决策(“empirical parameters”)。
batch size、patch size和网络拓扑结构的配置基于以下三个原则
-
使用较大的batch size。
-
使用较大的patch size以吸收更多的上下文信息。
-
使用足够深的网络拓扑结构,以保证感受野至少与patch size一样大,从而不会丢失上下文信息。
方法配置中的细节比体系结构变化对性能的影响更大
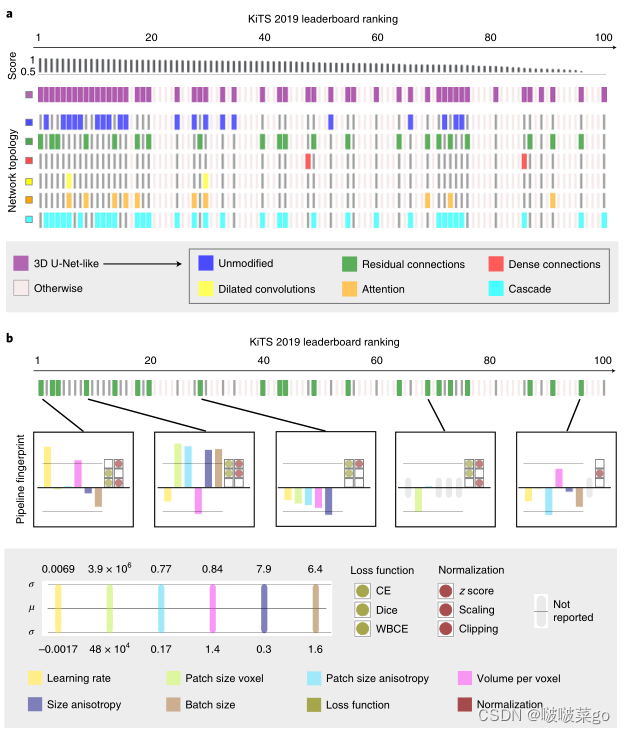
图a中前15种结构都来源于U-Net架构,证实了其对生物医学图像分割领域的影响。
前15种方法,没有一种常用的结构修改能被证明是在KiTS任务中表现良好的必要条件。
图4b体现了方法中细节的重要性,均使用了同种结构的方法,细节不同,取得的效果差别很大。
不同的数据集需要不同的配置

提取了23个数据集的数据指纹,证明了生物医学影像数据集的多样性,并揭示了模型缺少泛化能力的根本原因:在潜在的复杂关系下,合适的模型配置直接或间接地依赖于数据指纹,这一事实增大了方法配置的复杂性。