golang表达式中,语句末加“;“和不加都可,建议不加。
Main注意点
简要描述go中的main和init函数的区别
//方法一:声明一个变量 默认值是0
var a int
//方法二:声明一个变量 初始化一个值
var b int = 100
//方法三:在初始化的时候,可以省去数据类型,通过自动匹配当前变量的数据类型
var c = 100
//方法四:(常用)省去var 关键字,直接自动匹配
e := 100
同上,方法四不支持全局变量
var xx, yy = 100 , "hej"
多行写法
var (
ww int = 100
jj = true
)
go语法糖 := for range
const a int = 10
const (
a = 10
b = 20
)
–//iota 与const来表示枚举类型
const (
//可以在const()添加一个iota,每行的iota都会累加1,第一行默认为0
BEIGIN = 10 * iota //iota = 0
SHNGHAI //iota = 1
SHENHEN //iota = 2
)
两者因数据结构不同,其衍生出来的方法也不同,要跟据实际应用场景来选择
nil空值的赋值
const块中每一行在GO中使用spec数据结构描述,spec声明如下:
ValueSpec.Names:这个切片中保存了一行中定义的常量
可以更清晰的看出iota实际上是遍历const块的索引
数据类型的本质 固定内存⼤⼩的别名
存放代码逻辑的内存
struct结构体是否能比较
返回多个返回值
new 的作用是初始化一个指向类型的指针(*T)
new函数是内建函数,函数定义:func new(Type) *Type
var once sync. Once
type manager struct { name string }
var single * manager
func Singleton ( ) * manager{
once. Do ( func ( ) {
single = & manager{ "a" }
} )
return single
}
for循环支持continue和break来控制循环,但是它提供了一个更高级的break,可以选择中断哪一个循环
单个case中,可以出现多个结果选项
方法施加的对象显式传递,没有被隐藏起来
数组切片、字典(map)、通道(channel)、接口(interface)
可以通过“&”取指针的地址
import _ “fmt” 给fmt包起一个别名,匿名,无法使用当前包的方法,但是会执行当前包内部的init()方法。
用于延迟函数的调用
栈 先进后出
规则一:延迟函数的参数在defer语句出现时就已经确定下来了函数返回过程
defer后面一定要接一个函数,所以defer的数据结构跟一般函数类似
源码包 src/runtime/panic.go 定义了两个方法分别用于创建和执行defer
defer定义的延迟函数参数在defer语句出时就已经确定
声明数组的方式
var myArray1 [ 10 ] int
myArray2 := [ 10 ] int { 1 , 2 , 3 , 4 }
myArray3 := [ 4 ] int { 1 , 2 , 3 , 4 }
数组的长度是固定的,固定长度的数组在传参时候,要严格匹配数组的类型的。
func printArray ( myArray [ 4 ] int ) {
//值拷贝
}
myArray := [ ] int { 1 , 2 , 3 , 4 }
func printArray ( myArray [ ] int ) {
//引用传递 而 且不同元素长度的动态数组他们的形参一致。
}
声明方式
//声明slice1是一个切片,并且初始化,默认值是1,2,3,长度len=3
slice1 := [ ] int { 1 , 2 , 3 }
//声明slice1是一个切片,但是没有给slice分配空间
var slice1 [ ] int
slice1 = make ( [ ] int , 3 ) //开辟3个空间,默认值是0
//声明slice1是一个切片,同时给slice分配3个空间,初始化是0
var slice1 [ ] int = make ( [ ] int , 3 )
//声明slice1是一个切片,同时给slice分配3个空间,初始化是0,通过:=推导出slice是一个切片
slice1 := make ( [ ] int , 3 )
切片长度与容量不同,长度表示左指针到右指针的距离,容量表示左指针到底层数组末尾的距离
s := [ ] int { 1 , 2 , 3 }
s1 := s[ 0 , 2 ] //[0,2)
= > s1 = [ 1 , 2 ]
//s和s1都指向同一空间,改变任意一个值,s和s1里面的值都改变
s2 := make ( [ ] int , 3 )
copy ( s2, s)
如果想要分开指向,可使用copy函数深拷贝
扩容
数组
nil切片和空切片指向的地址一样吗
这个与:
2.切片指针的变量是否发生了逃逸
1)如果变量明确被函数外部所引用,那么肯定会在堆上分配内存
第一种
//声明myMap是一种map类型,key是string,value是string
var myMap map [ string ] string
if myMap == nil {
fmt. Println ( "myMap是一个空map" )
}
//在使用map前,需要使用make给map分配数据空间
myMap = make ( map [ string ] string , 10 )
//添加
myMap[ "one" ] = "java"
myMap[ "two" ] = "C++"
myMap[ "three" ] = "Python"
第二种
myMap := make ( map [ int ] string )
myMap[ 1 ] = "java"
myMap[ 2 ] = "C++"
myMap[ 3 ] = "Python"
第三种
myMap := map [ string ] string {
"one" : "php" ,
"two" : "c" ,
"three" : "python" ,
}
//遍历
for key, value := range myMap{
0
}
//删除
delete ( myMap, "one" )
//修改
myMap[ "one" ] = "DC0"
map 传参是引用传递,
func printMap ( myMap map [ string ] string ) {
}
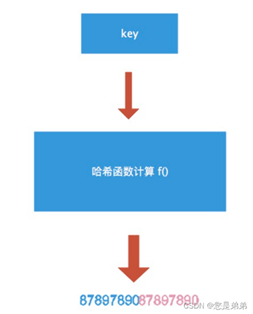
Golang中map的底层实现是一个散列表
每个bucket可以存储8个键值对
Golang的map中也有这么一个哈希函数
如图所示
当有两个或以上数量的键被哈希到了同一个bucket时,我们称这些键发生了冲突
bucket数据结构指示下一个bucket的指针称为overflow bucket,意为当前bucket盛不下而溢出的部分
扩容的前提条件
当前map存储了7个键值对,只有1个bucket。此负载因子为7。再次插入数据时将会触发扩容操作,扩容之后再将 新插入键写入新的bucket
hmap数据结构中oldbuckets成员指原bucket
数据搬迁过程中
所谓等量扩容,实际上并不是扩大容量
sync.Map 的实现原理可概括为:
sync.Map通过内部存储的两个map来实现了优化:分别是键(key) 固定的read表和包含所有键值对的dirty。所有对read上已有的键值对的增删改查操作都是无锁实现,考虑到的是“写特别少几乎固定”的场景,因为基本用不上锁,从而大大提高了性能。
map+读写锁RWMutex
sync.Map
单协程操作map,用channel通信
//如果类名首字母大写,表示其他包也能访问,
//this是调用该方法的对象的一个副本(拷贝)
interfa本质是一个指针 父类指针,子类继承
通用万能类型 interface{} 引用任意类型的数据类型
interface{} 和 interface{}interface{}本身不是万能指针, 就是eface结构体的地址。 interface{}作为形参,那么他只能够接收 interface{}类型的实参
反射提供一种让程序检查自身结构的能力
反射第三定律:反射对象可修改,value值必须是可设置的
值接收者,指针接收者
对接口进行的操作
这样,即使断言失败也不会 panic
可见
select语句中除default外,每个case操作一个channel,要么读要么写
select机制用来处理异步IO问题
goroutine超时设置,防止goroutine一直执行导致内存不释放等问题。
判断channel是否已满或空。如实现一个池线程,当channel已被写满,暂无空闲worker在进行读取,进入default,返回一个暂无可分配资源错误。
goroutine就是一段代码,一个函数入口,以及在堆上为其分配的一个堆栈。所以它非常廉价
channel是Golang在语言层面提供的goroutine间的通信方式
环形队列
被阻塞的goroutine将会挂在channel的等待队列中:
创建channel
类型信息和缓冲区长度由make语句传入
从channel读数据
会把recvq中的G全部唤醒,本该写入G的数据位置为nil
单向channel
无缓冲和有冲突的channel的区别
(1) 当一个goroutine获得了Mutex后,其他goroutine就只能乖乖的等待,除非该goroutine释放这个Mutex
A. 给一个 nil channel 发送数据,造成永远阻塞
goroutine是按照抢占式调度的,一个goroutine最多执行10ms就会换作下一个
创建一个G对象,加入到本地队列或者全局队列
如果还有空闲的P,则创建一个M
M会启动一个底层线程,循环执行能找到的G任务
G任务的执行顺序是,先从本地队列找,本地没有则从全局队列找(一次性转移(全局G个数/P个数)个,再去其它P中找(一次性转移一半)
https://www.jianshu.com/p/6def5063c1eb
当一个计算任务被goroutine承接了之后,由于某种原因(超时,或者强制退出)我们希望中止这个goroutine的计算任务,那么就用得到这个Context了。
在主goroutine上有4个RPC,RPC2/3/4是并行请求的,我们这里希望在RPC2请求失败之后,直接返回错误,并且让RPC3/4停止继续计算。这个时候,就使用的到Context。
场景三:超时请求
场景四:HTTP服务器的request互相传递数据
空指针解析
抛弃了C/C++中的开发者管理内存的方式
代码中使用的内存地址都是虚拟内存地址
当我们说内存管理的时候
释放内存实质是
概述
垃圾回收、三色标记原理
进程、线程、协程之间的区别?
我们对Markdown编辑器进行了一些功能拓展与语法支持,除了标准的Markdown编辑器功能,我们增加了如下几点新功能,帮助你用它写博客:
全新的界面设计 ,将会带来全新的写作体验;
在创作中心设置你喜爱的代码高亮样式,Markdown 将代码片显示选择的高亮样式 进行展示;
增加了 图片拖拽 功能,你可以将本地的图片直接拖拽到编辑区域直接展示;
全新的 KaTeX数学公式 语法;
增加了支持甘特图的mermaid语法1 功能;
增加了 多屏幕编辑 Markdown文章功能;
增加了 焦点写作模式、预览模式、简洁写作模式、左右区域同步滚轮设置 等功能,功能按钮位于编辑区域与预览区域中间;
增加了 检查列表 功能。
撤销:Ctrl/Command + Z Ctrl/Command + Y Ctrl/Command + B Ctrl/Command + I Ctrl/Command + Shift + H Ctrl/Command + Shift + U Ctrl/Command + Shift + O Ctrl/Command + Shift + C Ctrl/Command + Shift + K Ctrl/Command + Shift + L Ctrl/Command + Shift + G Ctrl/Command + F Ctrl/Command + G
直接输入1次# ,并按下space 后,将生成1级标题。# ,并按下space 后,将生成2级标题。TOC语法后生成一个完美的目录。
强调文本 强调文本
加粗文本 加粗文本
标记文本
删除文本
引用文本
H2 O is是液体。
210 运算结果是 1024.
链接: link .
图片:
带尺寸的图片:
居中的图片:
居中并且带尺寸的图片:
当然,我们为了让用户更加便捷,我们增加了图片拖拽功能。
去博客设置 页面,选择一款你喜欢的代码片高亮样式,下面展示同样高亮的 代码片.
// An highlighted block
var foo = 'bar' ;
项目1
项目2
项目3
一个简单的表格是这么创建的:
项目
Value
电脑
$1600
手机
$12
导管
$1
使用:---------:居中:----------居左----------:居右
第一列
第二列
第三列
第一列文本居中
第二列文本居右
第三列文本居左
SmartyPants将ASCII标点字符转换为“智能”印刷标点HTML实体。例如:
TYPE
ASCII
HTML
Single backticks
'Isn't this fun?'‘Isn’t this fun?’
Quotes
"Isn't this fun?"“Isn’t this fun?”
Dashes
-- is en-dash, --- is em-dash– is en-dash, — is em-dash
Markdown
Text-to-
HTML conversion tool
Authors
John
Luke
一个具有注脚的文本。2
Markdown将文本转换为 HTML 。
您可以使用渲染LaTeX数学表达式 KaTeX :
Gamma公式展示
Γ
(
n
)
=
(
n
−
1
)
!
∀
n
∈
N
\Gamma(n) = (n-1)!\quad\forall n\in\mathbb N
Γ ( n ) = ( n − 1 )! ∀ n ∈ N
Γ
(
z
)
=
∫
0
∞
t
z
−
1
e
−
t
d
t
.
\Gamma(z) = \int_0^\infty t^{z-1}e^{-t}dt\,.
Γ ( z ) = ∫ 0 ∞ t z − 1 e − t d t .
你可以找到更多关于的信息 LaTeX 数学表达式here .
Mon 06
Mon 13
Mon 20
已完成
进行中
计划一
计划二
现有任务
Adding GANTT diagram functionality to mermaid
可以使用UML图表进行渲染。 Mermaid . 例如下面产生的一个序列图:
张三
李四
王五
你好!李四, 最近怎么样?
你最近怎么样,王五?
我很好,谢谢!
我很好,谢谢!
李四想了很长时间, 文字太长了
不适合放在一行.
打量着王五...
很好... 王五, 你怎么样?
张三
李四
王五
这将产生一个流程图。:
我们依旧会支持flowchart的流程图:
Created with Raphaël 2.3.0
开始
我的操作
确认?
结束
yes
no
关于 Flowchart流程图 语法,参考 这儿 .
如果你想尝试使用此编辑器, 你可以在此篇文章任意编辑。当你完成了一篇文章的写作, 在上方工具栏找到 文章导出 ,生成一个.md文件或者.html文件进行本地保存。
如果你想加载一篇你写过的.md文件,在上方工具栏可以选择导入功能进行对应扩展名的文件导入,