目录
1.1 TensorRT构建和编译一个模型
1.2 Interference
1.3 动态shape
1.4 ONNX
-
TensorRT的核心在于对模型算子的优化(合并算子、利用GPU特性选择特定核函数等多种策略),通过tensorRT,能够在Nvidia系列GPU上获得最好的性能
-
因此tensorRT的模型,需要在目标GPU上实际运行的方式选择最优算法和配置
-
也因此tensorRT生成的模型只能在特定条件下运行(编译的trt版本、cuda版本、编译时的GPU型号)
-
主要知识点,是模型结构定义方式、编译过程配置、推理过程实现、插件实现、onnx理解
合并算子:
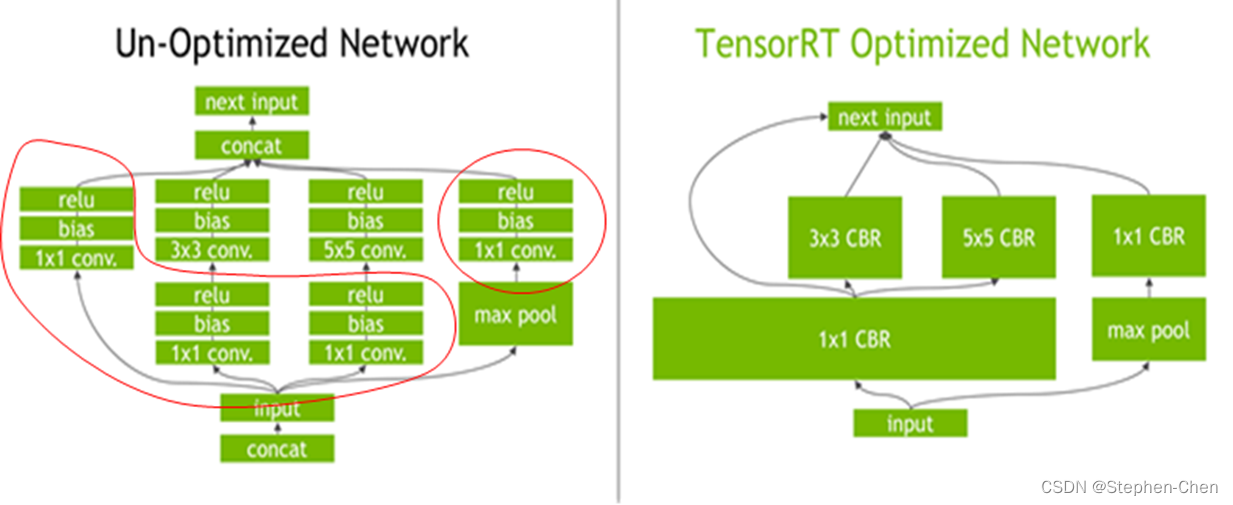
工作流程:

常见的方案:
方案一:基于tensorRT的发布,又有人在之上做了工作https://github.com/wang-xinyu/tensorrtx。为每个模型写硬代码,并已写好了大量的常见模型代码

方案二:onnx路线的模型编译、推理和部署,原因主要有
若使用onnx,则导出或者修改好的onnx模型,可以轻易的移植到其他引擎上、例如ncnn、rknn,这一点硬代码无法做到。并且用于排查错误,修改调整时也非常方便

TensorRT库文件:

1.1 TensorRT构建和编译一个模型
学习使用TensorRT-CPP的API构建网络模型,并进行编译的流程
TensorRT工作流程如下图:
- 首先定义网络
- 优化builder参数
- 通过builder生成engine,用于模型保存、推理等
- engine可以通过序列化和逆序列转化模型数据类型(转化为二进制byte文件,加快传输速率),再进一步推动模型由输入张量到输出张量的推理)

// tensorRT include
#include <NvInfer.h>
#include <NvInferRuntime.h>
// cuda include
#include <cuda_runtime.h>
// system include
#include <stdio.h>
class TRTLogger : public nvinfer1::ILogger{
public:
virtual void log(Severity severity, nvinfer1::AsciiChar const* msg) noexcept override{
if(severity <= Severity::kVERBOSE){ //自己判断日志的级别来打印哪些
printf("%d: %s\n", severity, msg);
}
}
};
nvinfer1::Weights make_weights(float* ptr, int n){
nvinfer1::Weights w;
w.count = n;
w.type = nvinfer1::DataType::kFLOAT;
w.values = ptr;
return w;
}
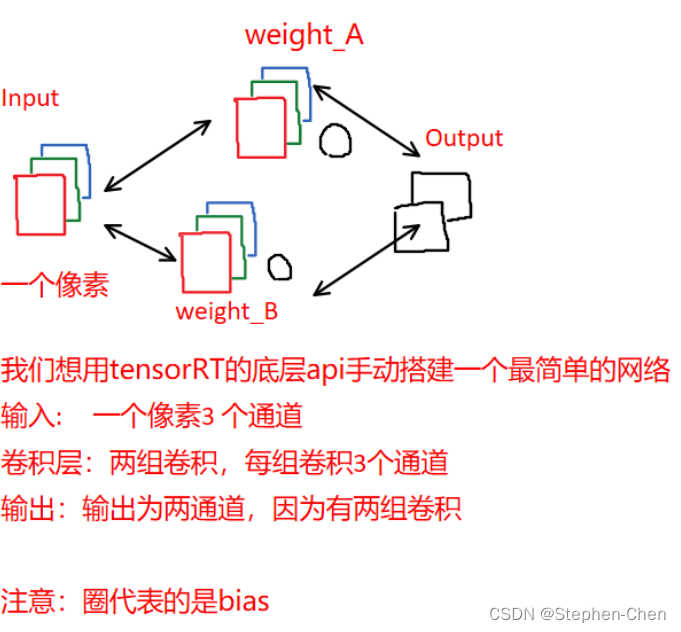
int main(){
// 本代码主要实现一个最简单的神经网络 figure/simple_fully_connected_net.png
TRTLogger logger; // logger是必要的,用来捕捉warning和info等
// ----------------------------- 1. 定义 builder, config 和network -----------------------------
// 这是基本需要的组件
//形象的理解是你需要一个builder去build这个网络,网络自身有结构,这个结构可以有不同的配置
nvinfer1::IBuilder* builder = nvinfer1::createInferBuilder(logger);
// 创建一个构建配置,指定TensorRT应该如何优化模型,tensorRT生成的模型只能在特定配置下运行
nvinfer1::IBuilderConfig* config = builder->createBuilderConfig();
// 创建网络定义,其中createNetworkV2(1)表示采用显性batch size,新版tensorRT(>=7.0)时,不建议采用0非显性batch size
// 因此贯穿以后,请都采用createNetworkV2(1)而非createNetworkV2(0)或者createNetwork
nvinfer1::INetworkDefinition* network = builder->createNetworkV2(1);
// 构建一个模型
/*
Network definition:
image
|
linear (fully connected) input = 3, output = 2, bias = True w=[[1.0, 2.0, 0.5], [0.1, 0.2, 0.5]], b=[0.3, 0.8]
|
sigmoid
|
prob
*/
// ----------------------------- 2. 输入,模型结构和输出的基本信息 -----------------------------
const int num_input = 3; // in_channel
const int num_output = 2; // out_channel
float layer1_weight_values[] = {1.0, 2.0, 0.5, 0.1, 0.2, 0.5}; // 前3个给w1的rgb,后3个给w2的rgb
float layer1_bias_values[] = {0.3, 0.8};
//输入指定数据的名称、数据类型和完整维度,将输入层添加到网络
nvinfer1::ITensor* input = network->addInput("image", nvinfer1::DataType::kFLOAT, nvinfer1::Dims4(1, num_input, 1, 1));
nvinfer1::Weights layer1_weight = make_weights(layer1_weight_values, 6);
nvinfer1::Weights layer1_bias = make_weights(layer1_bias_values, 2);
//添加全连接层
auto layer1 = network->addFullyConnected(*input, num_output, layer1_weight, layer1_bias); // 注意对input进行了解引用
//添加激活层
auto prob = network->addActivation(*layer1->getOutput(0), nvinfer1::ActivationType::kSIGMOID); // 注意更严谨的写法是*(layer1->getOutput(0)) 即对getOutput返回的指针进行解引用
// 将我们需要的prob标记为输出
network->markOutput(*prob->getOutput(0));
printf("Workspace Size = %.2f MB\n", (1 << 28) / 1024.0f / 1024.0f); // 256Mib
config->setMaxWorkspaceSize(1 << 28);
builder->setMaxBatchSize(1); // 推理时 batchSize = 1
// ----------------------------- 3. 生成engine模型文件 -----------------------------
//TensorRT 7.1.0版本已弃用buildCudaEngine方法,统一使用buildEngineWithConfig方法
nvinfer1::ICudaEngine* engine = builder->buildEngineWithConfig(*network, *config);
if(engine == nullptr){
printf("Build engine failed.\n");
return -1;
}
// ----------------------------- 4. 序列化模型文件并存储 -----------------------------
// 将模型序列化,并储存为文件
nvinfer1::IHostMemory* model_data = engine->serialize();
FILE* f = fopen("engine.trtmodel", "wb");
fwrite(model_data->data(), 1, model_data->size(), f);
fclose(f);
// 卸载顺序按照构建顺序倒序
model_data->destroy();
engine->destroy();
network->destroy();
config->destroy();
builder->destroy();
printf("Done.\n");
return 0;
}
注意:
-
必须使用createNetworkV2,并指定为1(表示显性batch)。createNetwork已经废弃,非显性batch官方不推荐。这个方式直接影响推理时enqueue还是enqueueV2
-
builder、config等指针,记得释放,否则会有内存泄漏,使用ptr->destroy()释放
-
markOutput表示是该模型的输出节点,mark几次,就有几个输出,addInput几次就有几个输入。这与推理时相呼应
-
workspaceSize是工作空间大小,某些layer需要使用额外存储时,不会自己分配空间,而是为了内存复用,直接找tensorRT要workspace空间。指的这个意思
-
一定要记住,保存的模型只能适配编译时的trt版本、编译时指定的设备。也只能保证在这种配置下是最优的。如果用trt跨不同设备执行,有时候可以运行,但不是最优的,也不推荐
1.2 Interference
编译好的模型进行推理
void inference(){
// ------------------------------ 1. 准备模型并加载 ----------------------------
TRTLogger logger;
auto engine_data = load_file("engine.trtmodel");
// 执行推理前,需要创建一个推理的runtime接口实例。与builer一样,runtime需要logger:
nvinfer1::IRuntime* runtime = nvinfer1::createInferRuntime(logger);
// 将模型从读取到engine_data中,则可以对其进行反序列化以获得engine
nvinfer1::ICudaEngine* engine = runtime->deserializeCudaEngine(engine_data.data(), engine_data.size());
if(engine == nullptr){
printf("Deserialize cuda engine failed.\n");
runtime->destroy();
return;
}
nvinfer1::IExecutionContext* execution_context = engine->createExecutionContext();
cudaStream_t stream = nullptr;
// 创建CUDA流,以确定这个batch的推理是独立的
cudaStreamCreate(&stream);
/*
Network definition:
image
|
linear (fully connected) input = 3, output = 2, bias = True w=[[1.0, 2.0, 0.5], [0.1, 0.2, 0.5]], b=[0.3, 0.8]
|
sigmoid
|
prob
*/
// ------------------------------ 2. 准备好要推理的数据并搬运到GPU ----------------------------
float input_data_host[] = {1, 2, 3};
float* input_data_device = nullptr;
float output_data_host[2];
float* output_data_device = nullptr;
cudaMalloc(&input_data_device, sizeof(input_data_host));
cudaMalloc(&output_data_device, sizeof(output_data_host));
cudaMemcpyAsync(input_data_device, input_data_host, sizeof(input_data_host), cudaMemcpyHostToDevice, stream);
// 用一个指针数组指定input和output在gpu中的指针。
float* bindings[] = {input_data_device, output_data_device};
// ------------------------------ 3. 推理并将结果搬运回CPU ----------------------------
bool success = execution_context->enqueueV2((void**)bindings, stream, nullptr);
cudaMemcpyAsync(output_data_host, output_data_device, sizeof(output_data_host), cudaMemcpyDeviceToHost, stream);
cudaStreamSynchronize(stream);
printf("output_data_host = %f, %f\n", output_data_host[0], output_data_host[1]);
// ------------------------------ 4. 释放内存 ----------------------------
printf("Clean memory\n");
cudaStreamDestroy(stream);
execution_context->destroy();
engine->destroy();
runtime->destroy();
// ------------------------------ 5. 手动推理进行验证 ----------------------------
const int num_input = 3;
const int num_output = 2;
float layer1_weight_values[] = {1.0, 2.0, 0.5, 0.1, 0.2, 0.5};
float layer1_bias_values[] = {0.3, 0.8};
printf("手动验证计算结果:\n");
for(int io = 0; io < num_output; ++io){
float output_host = layer1_bias_values[io];
for(int ii = 0; ii < num_input; ++ii){
output_host += layer1_weight_values[io * num_input + ii] * input_data_host[ii];
}
// sigmoid
float prob = 1 / (1 + exp(-output_host));
printf("output_prob[%d] = %f\n", io, prob);
}
}
-
bindings是tensorRT对输入输出张量的描述,bindings = input-tensor + output-tensor。比如input有a,output有b, c, d,那么bindings = [a, b, c, d],bindings[0] = a,bindings[2] = c。此时看到engine->getBindingDimensions(0)你得知道获取的是什么
-
enqueueV2是异步推理,加入到stream队列等待执行。输入的bindings则是tensors的指针(注意是device pointer)。其shape对应于编译时指定的输入输出的shape(这里只演示全部shape静态)
-
createExecutionContext可以执行多次,允许一个引擎具有多个执行上下文,不过看看就好,别当真。
1.3 动态shape
动态shape,即编译时指定可动态的范围[L-H],推理时可以允许 L <= shape <= H
// --------------------------------- 2.1 关于profile ----------------------------------
// 如果模型有多个输入,则必须多个profile
auto profile = builder->createOptimizationProfile();
// 配置最小允许1 x 1 x 3 x 3
profile->setDimensions(input->getName(), nvinfer1::OptProfileSelector::kMIN, nvinfer1::Dims4(1, num_input, 3, 3));
profile->setDimensions(input->getName(), nvinfer1::OptProfileSelector::kOPT, nvinfer1::Dims4(1, num_input, 3, 3));
// 配置最大允许10 x 1 x 5 x 5
// if networkDims.d[i] != -1, then minDims.d[i] == optDims.d[i] == maxDims.d[i] == networkDims.d[i]
profile->setDimensions(input->getName(), nvinfer1::OptProfileSelector::kMAX, nvinfer1::Dims4(maxBatchSize, num_input, 5, 5));
config->addOptimizationProfile(profile);
-
OptimizationProfile是一个优化配置文件,用来指定输入的shape可以变换的范围的,不要被优化两个字蒙蔽了双眼
-
如果onnx的输入某个维度是-1,表示该维度动态,否则表示该维度是明确的,明确维度的minDims, optDims, maxDims一定是一样的
1.4 ONNX
用python将torch转为onnx:
class Model(torch.nn.Module):
def __init__(self):
super().__init__()
self.conv = nn.Conv2d(1, 1, 3, padding=1)
self.relu = nn.ReLU()
self.conv.weight.data.fill_(1)
self.conv.bias.data.fill_(0)
def forward(self, x):
x = self.conv(x)
x = self.relu(x)
return x
# 这个包对应opset11的导出代码,如果想修改导出的细节,可以在这里修改代码
# import torch.onnx.symbolic_opset11
print("对应opset文件夹代码在这里:", os.path.dirname(torch.onnx.__file__))
model = Model()
dummy = torch.zeros(1, 1, 3, 3)
torch.onnx.export(
model,
# 这里的args,是指输入给model的参数,需要传递tuple,因此用括号
(dummy,),
# 储存的文件路径
"demo.onnx",
# 打印详细信息
verbose=True,
# 为输入和输出节点指定名称,方便后面查看或者操作
input_names=["image"],
output_names=["output"],
# 这里的opset,指,各类算子以何种方式导出,对应于symbolic_opset11
opset_version=11,
# 表示他有batch、height、width3个维度是动态的,在onnx中给其赋值为-1
# 通常,我们只设置batch为动态,其他的避免动态
dynamic_axes={
"image": {0: "batch", 2: "height", 3: "width"},
"output": {0: "batch", 2: "height", 3: "width"},
}
)
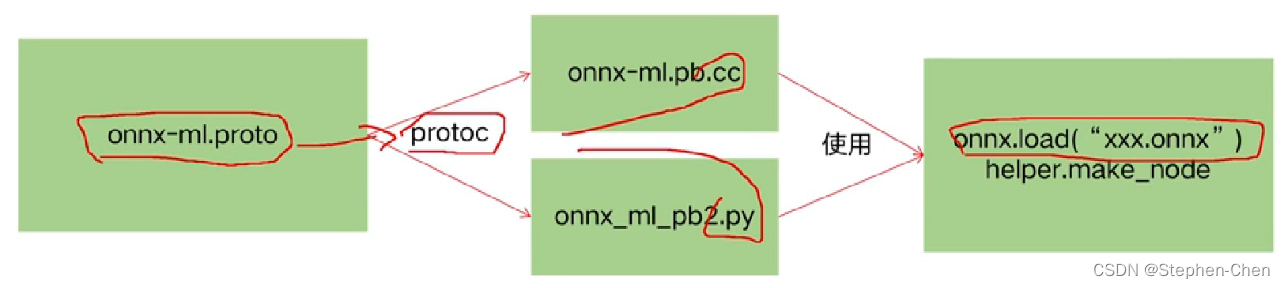
-
ONNX的本质,是一种Protobuf格式文件
-
Protobuf则通过onnx-ml.proto编译得到onnx-ml.pb.h和onnx-ml.pb.cc或onnx_ml_pb2.py
-
然后用onnx-ml.pb.cc和代码来操作onnx模型文件,实现增删改
-
onnx-ml.proto则是描述onnx文件如何组成的,具有什么结构,他是操作onnx经常参照的东西
Onnx主要结构:日日日日日日日日日日日日日日

model:表示整个onnx的模型,包含图结构和解析器格式、opset版本、导出程序类型
model.graph:表示图结构,通常是我们netron看到的主要结构
model.graph.node:表示图中的所有节点,数组,例如conv、bn等节点就是在这里的,通过input、output表示节点之间的连接关系
model.graph.initializer:权重类的数据大都储存在这里
model.graph.input:整个模型的输入储存在这里,表明哪个节点是输入节点,shape是多少
model.graph.output:整个模型的输出储存在这里,表明哪个节点是输出节点,shape是多少
表示onnx中有节点类型叫node
-
input属性,是repeated,即重复类型,数组
-
output属性,是repeated,即重复类型,数组
-
name属性是string类型
-
对于repeated是数组,对于optional无视他
-
对于input = 1,后面的数字是id,无视他
我们只关心是否数组,类型是什么
查看onnx信息:
model = onnx.load("demo.change.onnx")
#打印信息
print("==============node信息")
# print(helper.printable_graph(model.graph))
print(model)
conv_weight = model.graph.initializer[0]
conv_bias = model.graph.initializer[1]
# 数据是以protobuf的格式存储的,因此当中的数值会以bytes的类型保存,通过np.frombuffer方法还原成类型为float32的ndarray
print(f"===================={conv_weight.name}==========================")
print(conv_weight.name, np.frombuffer(conv_weight.raw_data, dtype=np.float32))
print(f"===================={conv_bias.name}==========================")
print(conv_bias.name, np.frombuffer(conv_bias.raw_data, dtype=np.float32))
创建onnx:
import onnx # pip install onnx>=1.10.2
import onnx.helper as helper
import numpy as np
# https://github.com/onnx/onnx/blob/v1.2.1/onnx/onnx-ml.proto
nodes = [
helper.make_node(
name="Conv_0", # 节点名字,不要和op_type搞混了
op_type="Conv", # 节点的算子类型, 比如'Conv'、'Relu'、'Add'这类,详细可以参考onnx给出的算子列表
inputs=["image", "conv.weight", "conv.bias"], # 各个输入的名字,结点的输入包含:输入和算子的权重。必有输入X和权重W,偏置B可以作为可选。
outputs=["3"],
pads=[1, 1, 1, 1], # 其他字符串为节点的属性,attributes在官网被明确的给出了,标注了default的属性具备默认值。
group=1,
dilations=[1, 1],
kernel_shape=[3, 3],
strides=[1, 1]
),
helper.make_node(
name="ReLU_1",
op_type="Relu",
inputs=["3"],
outputs=["output"]
)
]
initializer = [
helper.make_tensor(
name="conv.weight",
data_type=helper.TensorProto.DataType.FLOAT,
dims=[1, 1, 3, 3],
vals=np.array([1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0], dtype=np.float32).tobytes(),
raw=True
),
helper.make_tensor(
name="conv.bias",
data_type=helper.TensorProto.DataType.FLOAT,
dims=[1],
vals=np.array([0.0], dtype=np.float32).tobytes(),
raw=True
)
]
inputs = [
helper.make_value_info(
name="image",
type_proto=helper.make_tensor_type_proto(
elem_type=helper.TensorProto.DataType.FLOAT,
shape=["batch", 1, 3, 3]
)
)
]
outputs = [
helper.make_value_info(
name="output",
type_proto=helper.make_tensor_type_proto(
elem_type=helper.TensorProto.DataType.FLOAT,
shape=["batch", 1, 3, 3]
)
)
]
graph = helper.make_graph(
name="mymodel",
inputs=inputs,
outputs=outputs,
nodes=nodes,
initializer=initializer
)
# 如果名字不是ai.onnx,netron解析就不是太一样了
opset = [
helper.make_operatorsetid("ai.onnx", 11)
]
# producer主要是保持和pytorch一致
model = helper.make_model(graph, opset_imports=opset, producer_name="pytorch", producer_version="1.9")
onnx.save_model(model, "my.onnx")
print(model)
print("Done.!")
ONNX重点:
-
ONNX的主要结构:graph、graph.node、graph.initializer、graph.input、graph.output
-
ONNX的节点构建方式:onnx.helper,各种make函数
-
ONNX的proto文件,https://github.com/onnx/onnx/blob/main/onnx/onnx-ml.proto
-
理解模型结构的储存、权重的储存、常量的储存、netron的解读对应到代码中的部分
-
ONNX的解析器的理解,包括如何使用nv发布的解析器源代码https://github.com/onnx/onnx-tensorrt
预处理preprocess.onnx
import torch
'''用pytorch写好预处理,生成再加载'''
class Preprocess(torch.nn.modules):
def __init__(self) -> None:
super().__init__()
self.mean = torch.rand(1,1,1,3)
self.std = torch.rand(1,1,1,3)
def forward(self,x):
# x = B*H*W*C Uint8
# y = B*C*H*W F=loart32 减去均值除以标准差
x.float()
x = (x/255.0 - self.mean) /self.std
return x
pre = Preprocess()
torch.onnx.export(
pre,(torch.zeros(1,640,640,3,dtype=torch.uint8),), "preprocess.onnx"
)
pre_onnx = onnx.load("preprocess.onnx")
#0.先把pre_onnx的所有节点以及输入输出名称都加上前缀
#1.yolov5中的image输入节点修改为pre_onnx的输出节点
#2.把pre_onnx的node全部放到yolov5s的node中
#3.把pre_onnx的输入名称作为yolov5s的input名称
for n in pre_onnx.graph.node:
n.name = f"pre/{n.name}"
for n in model.graph.node:
if n.name == "Conv_0":
n.imput[0] = "pre/" + pre_onnx.graph.output[0].name
#2.将pre_onnxpre_onnx的node全部放到yolov5s的node中
for n in pre_onnx.graph.node:
model.graph.node.append(n)
input_name = "pre/" + pre_onnx.graph.input[0].name
model.input[0].CopyFrom(pre_onnx.graph.input[0])
model.input[0].name = input_name
正确导出ONNX:
-
对于任何用到shape、size返回值的参数时,例如:tensor.view(tensor.size(0), -1)这类操作,避免直接使用tensor.size的返回值,而是加上int转换,tensor.view(int(tensor.size(0)), -1),断开跟踪。
-
对于nn.Upsample或nn.functional.interpolate函数,使用scale_factor指定倍率,而不是使用size参数指定大小。
-
对于reshape、view操作时,-1的指定请放到batch维度。其他维度可以计算出来即可。batch维度禁止指定为大于-1的明确数字
-
torch.onnx.export指定dynamic_axes参数,并且只指定batch维度,禁止其他动态
-
使用opset_version=11,不要低于11
-
避免使用inplace操作,例如y[…, 0:2] = y[…, 0:2] * 2 - 0.5
-
尽量少的出现5个维度,例如ShuffleNet Module,可以考虑合并wh避免出现5维
-
尽量把让后处理部分在onnx模型中实现,降低后处理复杂度
-
掌握了这些,就可以保证后面各种情况的顺利了
ONNX解析器:
onnx解析器有两个选项:
- libnvonnxparser.so
-
https://github.com/onnx/onnx-tensorrt(源代码)。 使用源代码的目的,是为了更好的进行自定义封装,简化插件开发或者模型编译的过程,更加具有定制化,遇到问题可以调试
插件的实现:
重点:
1.
如何在
pytorch里面导出一个插件
2.
插件解析时如何对应,在
onnx
parser
中如何处理
3.
插件的
creator实现
4.
插件的具体实现,
继承自IPluginV2DynamicExt
5.
插件的序列化与反序列化
MYSELU:
#include "onnx-tensorrt/onnxplugin.hpp"
using namespace ONNXPlugin;
static __device__ float sigmoid(float x){
return 1 / (1 + expf(-x));
}
static __global__ void MYSELU_kernel_fp32(const float* x, float* output, int edge) {
int position = threadIdx.x + blockDim.x * blockIdx.x;
if(position >= edge) return;
output[position] = x[position] * sigmoid(x[position]);
}
class MYSELU : public TRTPlugin {
public:
SetupPlugin(MYSELU); //定义宏
virtual void config_finish() override{
printf("\033[33minit MYSELU config: %s\033[0m\n", config_->info_.c_str());
printf("weights count is %d\n", config_->weights_.size());
}
int enqueue(const std::vector<GTensor>& inputs, std::vector<GTensor>& outputs, const std::vector<GTensor>& weights, void* workspace, cudaStream_t stream) override{
int n = inputs[0].count();
const int nthreads = 512;
int block_size = n < nthreads ? n : nthreads;
int grid_size = (n + block_size - 1) / block_size;
//执行核函数
MYSELU_kernel_fp32 <<<grid_size, block_size, 0, stream>>> (inputs[0].ptr<float>(), outputs[0].ptr<float>(), n);
return 0;
}
};
RegisterPlugin(MYSELU); //注册插件
Int8量化:
int8量化是利用int8乘法替换float32乘法实现性能加速的一种方法
1.
对于常规模型有:
y =
kx
+ b
,此时
x
、
k
、
b
都是
float32,
对于
kx
的计算使用
float32
的乘法
2.
对于
int8
模型有:
y = tofp32(toint8(k) * toint8(x)) + b,
其中
int8 * int8
结果为
int16
3.
因此
int8
模型解决的问题是如何将
float32
合理的转换为
int8
,使得精度损失最小
4.
也因此,经过
int8
量化的精度会受到影响
Int8量化步骤:
1. 配置setFlag nvinfer1::BuilderFlag::kINT8
2. 实现Int8EntropyCalibrator类并继承自IInt8EntropyCalibrator2
3. 实例化Int8EntropyCalibrator并且设置到config.setInt8Calibrator
4. Int8EntropyCalibrator的作用,是读取并预处理图像数据作为输入
- 标定过程的理解:对于输入图像A,使用FP32推理后得到P1再用INT8推理得到 P2,调整int8权重使得P1与P2足够的接近
- 因此标定时需要使用一些图像,正常发布时,使用100张图左右即可
Int8EntropyCalibrator类主要关注:
-
getBatchSize,告诉引擎,这次标定的batch是多少
-
getBatch,告诉引擎,这次标定的输入数据是什么,把指针赋值给bindings即可,返回false表示没有数据了
-
readCalibrationCache,若从缓存文件加载标定信息,则可避免读取文件和预处理,若该函数返回空指针则表示没有缓存,程序会重新通过getBatch重新计算
- writeCalibrationCache,当标定结束后,会调用该函数,我们可以储存标定后的缓存结果,多次标定可以使用该缓存实现加速
参考文献:TensorRT(1)-介绍-使用-安装 | arleyzhang