前言
- 对于二维平面数据来说,pandas无疑是数据处理和数据分析的好帮手,接下来就细细的演示和讲解一下,一些关于pandas的操作,希望能对你有所帮助。
这里主要利用pandas从六个方面来对数据进行操作:
1 导入数据
自我生成数据
pandas 有两个常用的数据结构:Series 和 DataFrame,可以用来生成你想要的数组型对象。
pd.Series(data=None, index=None, dtype=None, name=None, copy=False, fastpath=False)
pd.DataFrame(data=None, index=None, columns=None, dtype=None, copy=False)
外部加载数据
但是,在一般的数据处理分析中,往往自我生成数据情况较少,更多的是导入数据。pandas提供了一些用于将表格型数据读取为DataFrame对象的函数。
这里导入本次需要的用到的数据(该数据来自天猫爬取的网页数据,有兴趣的可以自己去爬取,这里只是暂做示例):
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
data = pd.read_excel("E:/data/tianmao_phone.xlsx")
表1对我们常用的文件格式进行了总结,其中pd.read_csv()和pd.read_excel()可能会是你今后用得最多的。

这些pandas的解析函数参数较为复杂,具体了解可以在pandas官网上自行查阅,或者可以再Jupyter Notebook 中采用help(pd.read_excel)命令查阅。
注:这里使用的都是小规模的数据(500万以下),而在现实生活中的数据有时往往跟为复杂(动辄几个G到TB),pandas在读取的时候往往就会用到chunsize等参数(可以传入大小)分块读取。
但是,其效率也是低下,所以建议大数据还是用一些适合它的的工具(数据库等),没有最好的工具,只有最适合的工具。
2 审阅数据
在成功导入数据以后,需要对数据进行审阅,目的是,了解数据结构、类型、大小等情况。方便理解数据和为后续处理分析打下基础。
1.查看前5行(默认前5行,你也可以在括号里输入你想要的行数):
data.head()
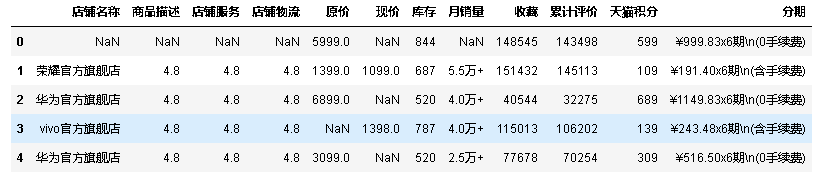
2.查看倒数5行:
data.tail()
3.查看维度信息:
data.shape
4.查看每一列的数据格式:
data.dtypes
5.查看数据表基本信息(维度、列名称、数据格式、所占空间等):
data.info()

6.查看某一列具体信息:
#两种处理效果一样
data['月销量']
data.月销量
7.也可以按索引提取单行或多行数值:
#提取第4行
data.iloc[4]
#提取到第4行
data.iloc[0:4]
#提取所有行,0到4列(也可以反过来)
data.iloc[:,0:4]
#提取第0、2、4行,第3、4列
data.iloc[[0,2,4].[3,4]]
注:数据的选取较为灵活,方法也较多,诸如:data["你要选取的列名称"],data.loc[],data.iloc[],data.ix[]等等。具体可以上官网了解一下他们的区别和作用,这里就不再继续详述了。
8.将数据进行排序
#按销量的大小进行排序,只取前8行
data.sort_values(by=['累计评价'],ascending=False).iloc[:8,:]
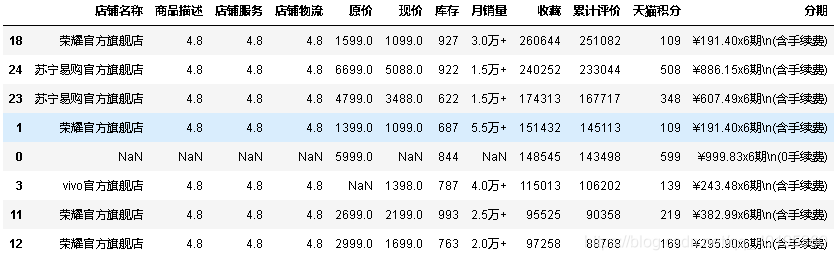
#查看类别信息
count_class = pd.value_counts(data['店铺名称'],sort=True).sort_index()
print(count_class)
9.查看基本的统计信息(最大值、最小值、平均值、中位值、四分位值、标准差等):
data.describe()
3 数据预处理
说完对表中的数据进行简单的查看,下面进行对数据进行的最关键操作:数据预处理
(1) 数据集成
由于我的数据较为规整,不需要合并和拼接,这里只是简单介绍一下原理。
1.pandas.merge可根据一个或多个键将不同DataFrame中的行连接起来。SQL或其他关系型数据库的用户对此应该会比较熟悉,因为它实现的就是数据库的join操作。
pandas.merge(left, right, how='inner', on=None,
left_on=None, right_on=None, left_index=False, right_index=False,
sort=False, suffixes=('_x', '_y'), copy=True, indicator=False, validate=None)
该函数主要用于通过一个或多个键将两个数据集的行连接起来,类似于 SQL 中的 JOIN。典型应用场景是,针对同一个主键存在两张包含不同字段的表,现在我们想把他们整合到一张表里。在此典型情况下,结果集的行数并没有增加,列数则为两个元数据的列数和减去连接键的数量。
2.pandas.concat该方法相当于数据库中的全连接(UNION ALL),可以指定按某个轴进行连接,也可以指定连接的方式join(outer,inner 只有这两种)。与数据库不同的是concat不会去重,要达到去重的效果可以使用drop_duplicates方法。
pandas.concat(objs, axis=0, join='outer',
join_axes=None, ignore_index=False, keys=None,
levels=None, names=None,verify_integrity=False, sort=None, copy=True)
轴向连接 pd.concat()只是单纯的把两个表拼在一起,这个过程也被称作连接(concatenation)。这个函数的关键参数应该是 axis,用于指定连接的轴向。在默认的 axis=0 情况下,pd.concat([data1,data2]) 函数的效果与 data1.append(data2) 是相同的;而在 axis=1 的情况下,pd.concat([data1,data2],axis=1) 的效果与pd.merge(data1,data2,left_index=True,right_index=True,how='outer') 是相同的。可以理解为 concat 函数使用索引作为“连接键”。
3.join方法提供了一个简便的方法用于将两个DataFrame中的不同的列索引合并成为一个DataFrame。
DataFrame.join(other, on=None, how='left', lsuffix='', rsuffix='', sort=False)
其中参数的意义与merge方法基本相同,只是join方法默认为左外连接how=left。
4.DataFrame.combine_first(other) 可以将重复数据拼接在一起,用一个对象中的值填充另一个对象中的缺失值。
5.update.如果要用一张表中的数据来更新另一张表的数据则可以用update来实现
DataFrame.update(other, join='left', overwrite=True, filter_func=None, raise_conflict=False)
注:使用combine_first会只更新左表的nan值。而update则会更新左表的所有能在右表中找到的值(两表位置相对应)。
具体了解可以在pandas官网上自行查阅,或者可以再Jupyter Notebook 中采用help()命令查阅。
(2) 数据清洗
数据整理
1.字符串处理
原始数据中,有很多字符串类型的数据,不便于分析,利用字符串函数对数据进行处理。
#将“收藏”字符串中的数值型数据取出来
data['收藏']=data['收藏'].str.extract('(\d+)')
#同理“库存”只要数据
data['库存']=data['库存'].str.extract('(\d+)')
#同理“天猫积分”只要数据
data['天猫积分']=data['天猫积分'].str.extract('(\d+)')
#“现价”中含有区间值,进行拆分,并取最低价
data['现价']=data['现价'].str.split('-',expand=True)[0]
#同理,“原价”拆分,与“现价”保持一致
data['原价']=data['原价'].str.split('-',expand=True)[0]
2.数据类型处理
将处理完的字符串数据,转换成有利于后续分析的数据。
#时间序列处理
data['当前时间']=pd.to_datetime(data['当前时间'],format='%Y%m%d')
#将时间序列设置为索引并按照索引进行排序
data=data.set_index(data['当前时间']).sort_index()
#由于月销量数据带有字符串,所以需要将字符串替换,并最终转化为数值型
data['月销量']=data['月销量'].str.replace('万','0000')
data['月销量']=data['月销量'].str.replace('+','')
data['月销量']=data['月销量'].str.replace('.','').astype(np.float64)
#其他数据类型处理
data['现价']=data['现价'].astype(np.float64)
data['原价']=data['原价'].astype(np.float64)
data['收藏']=data['收藏'].astype(np.float64)
data['库存']=data['库存'].astype(np.float64)
data['天猫积分']=data['天猫积分'].astype(np.float64)
注:在处理数据进行格式转换时,有时object无法转换成int64或者float64,这时就需要先处理内部格式,再进行转换。如:
data['orginal_shop_price']=data['orginal_shop_price'].str.replace(",",'').astype(np.float64)
缺失值处理:
1.查找缺失值。看那些列存在缺失值:
data.isnull().any()
2.定位缺失值。将含有缺失值的行筛选出来:
#筛选出任何含有缺失值的数据
data[data.isnull().values==True]
#统计某一列缺失值的数量
data['现价'].isnull().value_counts()
#筛选出某一列含有缺失值的数据
data[data['原价'].isnull().values==True]
3.删除缺失值:
data.dropna(axis=0, how='any', thresh=None, subset=None, inplace=False)`
#删除月销量中的缺失值
data.dropna(axis=0,subset=["月销量"])
可以利用subset和thresh参数来删除你需要删除的缺失值,inplace则表示是否在原表上替代。
4.填充缺失值:
固定值填充:
data.fillna(value=None, method=None, axis=None, inplace=False, limit=None, downcast=None, **kwargs)
#利用月销量的均值来对NA值进行填充
data["月销量"].fillna(data["月销量"].mean())
#利用月销量的中位数来对NA值进行填充
data["月销量"].fillna(data["月销量"].median())
#对于一些商品的现价和原价没有的数据,可采用现价填充原价,原价填充现价。
data["现价"]=data["现价"].fillna(data["原价"])
data["原价"]=data["原价"].fillna(data["现价"])
当然,缺失值的处理方法远不止这几种,这里只是简单的介绍一般操作,还有其他更高级的操作,比如:随机森林插值、拉格朗日插值、牛顿插值等等。针对这些高难度的插值方法,有兴趣可以自我去了解了解。
重复值处理
定位重复值:
#找出"店铺名称"存在重复的数据
data[data.duplicated(subset=["店铺名称"], keep='first')]
删除重复值:
#删除“店铺名称”存在重复的数据
data.drop_duplicates(subset=["店铺名称"], keep='first', inplace=False)
异常值处理:
在进行异常值处理之前,需先进行异常值检验,比较常用的有两种方法:
- 数据服从正态分布,采用3σ原则。
- 数据不服从正太分布,采用箱线图检验。
3σ原则:
#插入一列three_sigma又来表示是否是异常值
data['three_sigma'] = data['月销量'].transform( lambda x: (x.mean()-3*x.std()>x)|(x.mean()+3*x.std()<x))
#筛选出目标变量的异常值
data[data['three_sigma']==True]
#保留正常的数据
correct_data=data[data['three_sigma']==False]
箱线图处理异常值:
#定义一个下限
lower = data['月销量'].quantile(0.25)-1.5*(data['月销量'].quantile(0.75)-data['月销量'].quantile(0.25))
#定义一个上限
upper = data['月销量'].quantile(0.25)+1.5*(data['月销量'].quantile(0.75)-data['月销量'].quantile(0.25))
#重新加入一列,用于判断
data['qutlier'] = (data['月销量'] < lower) | (data['月销量'] > upper)
#筛选异常数据
data[data['qutlier'] ==True]
#过滤掉异常数据
qutlier_data=data[data['qutlier'] ==False]
细心的你可能会发现,采用两种方法来处理异常数据的结果往往是不同的,箱线图法更为严格(有兴趣的话,你可以去了解了解其中的原理)。
多余行/多余列删除
data.drop(labels=None, axis=0, index=None, columns=None, level=None, inplace=False, errors='raise')
该操作主要用于不需要的行(默认删除行)或者列进行删除,从而有利于数据精简。
(3) 数据变换
数据变换主要有以下几点内容:
1.简单函数变换。例如对数据开方、平方、取对数、倒数、差分、指数等。目的是为了后续分析提供想要的数据和方便分析(根据实际情况而定)。
#由于“累计评价”的值太大,我们新增一列对“累计评价”取对数处理
data['对数_累计评价']=np.sqrt(data['累计评价'])
#插入一列,计算“优惠力度”
data['优惠力度']=data1['现价']/data1['原价']
2.数据标准化。数据标准化是为了消除数据的量纲影响,为后续许多算法分析必要条件。常见的标准化方法很多,这里只是简单介绍一下:
Min-Max标准化
#使不使用函数,根据你的理解都可以,这里使用函数
data['标准化月销量']=data.月销量.transform(lambda x : (x-x.min())/(x.max()-x.min()))
Z-score标准化法
data['Z_月销量']=data['月销量'].transform(lambda x : (x-x.mean())/x.std())
3.数据离散化处理。连续值经常需要离散化或者分箱,方便数据的展示和理解,以及结果的可视化。比如最常见就是日常生活中对年龄的离散化,将年龄分为:幼儿、儿童、青年、中年、老年等。
#新增一列,将月销量划分成10个等级
data['data_cut']=pd.cut(data['月销量'],bins=10,labels=[1,2,3,4,5,6,7,8,9,10])
#新增一列,将月销量划分成10个等级
data['data_qcut']=pd.qcut(data['月销量'],q=10,labels=[1,2,3,4,5,6,7,8,9,10])
这两种都是对数据进行离散化,但通过结果仔细一看,你会发现,这两者的结果是不同的。说简单点就是,一个是等距分箱,一个是等频分享(分位数分箱),往往后者更常用。
(4) 数据精简
数据精简在数据分析和数据挖掘中至关重要,数据挖掘和分析的往往是海量数据,其海量特征主要体现在两个方面:第一,样本量庞大;第二,变量个数较多。海量数据无疑会影响建模的效率,为此主要的应对措施有:
1.压缩样本量。主要是指随机抽样
2.简约变量值。主要是指离散化处理
3.变量降维。主要是将许多变量用少数变量来分析(诸如因子分析等)
变量的离散化处理前面已经介绍,这里从随机抽样入手。关于变量降维,后续关于算法的学习在具体介绍。
#随机不重复抽取100行数据样本
data.sample(n=100)
关于随机抽样函数如下:
sample(n=None, frac=None, replace=False, weights=None, random_state=None, axis=None)
n和frac作用是相同的,n是抽样个数,frac是抽样比例(浮点数);
replace:是否为有放回抽样,取replace=True时为有放回抽样;
weights这个是每个样本的权重,具体可以看官方文档说明。
4 数据分析
终于来到了数据分析环节,前面所做的工作全是为了数据分析和数据可视化做准备。这里本文只是进行一些简单的数据分析,关于模型啊,算法啊……这些,这里不做介绍,在掌握这些简单的分析之后,可以去理解更高深的分析方法。
(1) 描述性分析
1.集中趋势
表示数据集中趋势的指标有:平均值、中位数、众数、第一四分位数和第三四分位数。
#通过定义一个函数,来查看数据的集中趋势
def f(x):
return pd.DataFrame([x.mean(),x.median(),x.mode(),x.quantile(0.25),x.quantile(0.75)],
index=['mean','median','mode','Q1','Q3'])
#调用函数
f(data['月销量'])
2.离散程度
表示数据离散程度的有:方差,标准差,极差,四分位间距。
#通过定义一个函数,来查看数据的离散程度
def k(x):
return pd.DataFrame([x.var(),x.std(),x.max()-x.min(),x.quantile(0.75)-x.quantile(0.25)],
index=['var','std','range','IQR'])
#调用函数
k(data['现价'])
2.分布形态
表示数据分布的有:偏度和峰度。
def g(x):
return pd.DataFrame([x.skew(),x.kurt()],
index=['skew','kurt'])
(2) 相关性分析
研究两个或两个以上随机变量之间相互依存关系的方向和密切程度的方法。线性相关关系主要采用皮尔逊(Pearson)相关系数r来度量连续变量之间线性相关强度;r>0,线性正相关;r<0,线性负相关;r=0,两个变量之间不存在线性关系,但是,并不代表两个变量之间不存在任何关系,有可能是非线性相关。
#相关系数矩阵
data.corr()
#协差阵
data.cov()
#任意两列相关系数
data['月销量'].corr(data['累计评价']
#因变量与所有变量的相关性
data.corrwith(data['月销量'])
5 pandas数据可视化
数据可视化的作用很多,而最常用的一般有两种功能:其一是对原始数据的探索性分析(EDA),其二是对结果数据的数据分析结果呈现。
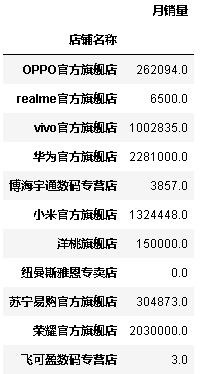
data_plot=data.groupby(by="店铺名称").agg({'月销量':sum})
#下面的代码与上面的效果等同
data.groupby(by='店铺名称')['月销量'].sum()
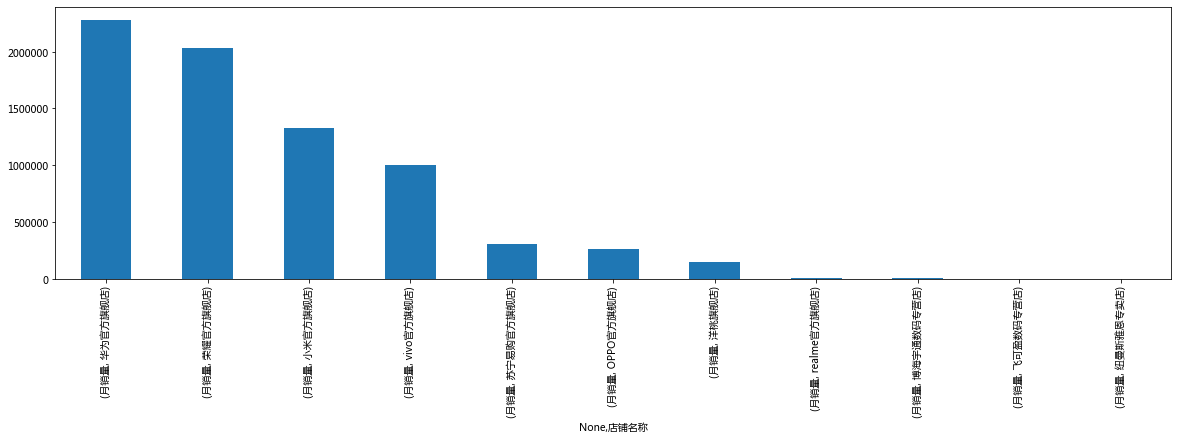
data_plot.unstack().sort_values(ascending=False).plot(kind='bar', figsize=(20, 5))
这里不再过多的讲解pandas可视化,因为pandas中的数据可视化已经可以满足我们大部分的要求了,也就省下了我们很多自己使用 如 matplotlib 来数据可视化的工作。所以我把pandas可视化放在下一篇博客单独来讲。
附上地址:pandas可视化