问:使用简单的函数解决回归问题时更容易过拟合?
答:使用简单的函数解决回归问题可能更容易欠拟合,而不是过拟合。这是因为简单的函数通常具有较低的灵活性,不能很好地拟合复杂的数据模式。因此,如果使用简单的函数来解决复杂的回归问题,则可能会发生欠拟合,使模型无法捕捉数据中的关键特征。
过拟合通常是在使用复杂的模型或具有大量参数的模型时发生的。这些模型通常具有高度的灵活性,可以很好地拟合数据,但也可能过度拟合噪声和无关特征。
回归问题中的曲线过拟合问题
我们先来了解一组概念:方差与偏差
偏差:(bias)是指一个模型的在不同训练集上的平均性能和最优模型的差异。偏差可以用来衡量一个模型的拟合能力。偏差越大,预测值平均性能越偏离最优模型。偏差衡量模型的预测能力,对象是一个在不同训练集上模型,形容这个模型平均性能对最优模型的预测能力。
方差:( variance)描述的是一个模型在不同训练集上的差异,描述的是一个模型在不同训练集之间的差异,表示模型的泛化能力,方差越小,模型的泛化能力越强。可以用来衡量一个模型是否容易过拟合。预测值的变化范围,离散程度,也就是离其期望值的距离。方差越大,预测结果数据的分布越散。方差用于衡量一个模型在不同训练集之间的关系,和最优模型无关。对象是不同训练集上的一个模型,表示选取不同的训练集,得出的模型之间的差异性。

①左侧的拟合方式:存在高偏差(High bias)的问题,预测值平均性能越偏离最优模型。
②中侧的拟合方式:优秀的拟合方式
③右侧的拟合方式:存在高方差的问题,虽然在这个模型中代价函数可能很少,但是它的泛化能力很差,难以泛化...
逻辑回归中的曲线过拟合问题

左侧拟合高偏差;中间为优秀拟合;右侧为过拟合。
如何解决过拟合问题
减少特征数量:手动选择要保留的特征;模型选择算法(后章介绍)
正则化参数:保留所有特征,但减小参数的权值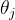 ;当我们有很多特征时,效果很好,每个特征都对预测
;当我们有很多特征时,效果很好,每个特征都对预测 有所贡献。
有所贡献。
原则上任意复杂的模型能完全拟合训练数据。我们称之为过拟合。
• 过拟合( overfitting ):过于复杂的模型与训练数据拟合得太好,但和测试数据拟合得不好。
• 欠拟合(underfitting):过于简单的模型与训练数据拟合得欠佳(和测试数据自然也拟合得不好)


防止模型过拟合的方法——正则化
前面使用多项式回归,如果多项式最高次项比较大,模型就容易出现过拟合。正则化是一种常见的防止过拟合的方法,一般原理是在代价函数后面加上一个对参数的约束项,这个约束项被叫做正则化项(regularizer)。在线性回归模型中,通常有两种不同的正则化项:
加上所有参数(不包括θo)的绝对值之和,即L1范数(L1正则化),此时叫做Lasso回归;
加上所有参数(不包括θo)的平方和,即L2范数(L2正则化),此时叫做岭回归.

- 增加训练样本数量
- 使用正则化约束
- 减少特征数
- 使用丢弃 (Dropout) 法
- 提前停止训练