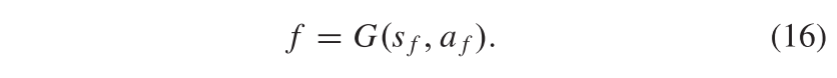DRF: Disentangled Representation for Visible and Infrared Image Fusion
(DRF: 可见光和红外图像融合的解纠缠表示)
在本文中,我们通过将 解纠缠表示 应用于可见光和红外图像融合 (DRF),提出了一种新颖的分解方法。根据成像原理,我们根据可见光和红外图像中的信息源进行分解。更具体地说,我们分别通过相应的编码器将图像分解为与场景和传感器模态 (属性) 相关的表示形式。以这种方式,由属性相关表示定义的唯一信息更接近于由每种类型的传感器单独捕获的信息。因此,可以缓解不适当提取唯一信息的问题。然后,将不同的策略应用于这些不同类型的表示形式的融合。最后,将融合的表示输入到预训练的生成器中以生成融合结果。
介绍
实际上,由于仪器的不完善,从热红外仪器获得的红外图像总是遭受严重的噪声和模糊的细节。为了提高仪器的成像质量,我们需要克服冲动噪声的客观影响或承担高昂的成本,这具有挑战性或昂贵。相比之下,可见成像仪器的发展相对更加完善。它们具有更好的成像质量和更低的成本。因此,IVIF可以看作是使用可见仪器来增强热红外仪器并提高其成像质量。
为了实现IVIF的目标,IVIF算法致力于从不同源图像中提取特征及其融合规则。其中,许多算法旨在将源图像分解为不同的部分以提取各种特征。然后,根据这些部分的特点设计了多种融合策略。在这些方法中,为了便于手工设计融合策略,提取的特征往往是同一类型或具有相同的含义。根据该理论,这些方法主要包括基于多尺度变换的方法、基于稀疏表示的方法和基于低秩表示的方法。例如,在多尺度变换中,金字塔变换旨在将源图像分解为多尺度的空间频带,而小波变换将源图像分解为一系列高频和低频子图像。对于不同类型的源图像,频带的设置是相同的。在基于稀疏表示的方法中,不同类型的源图像由相同的学习过完备字典及其各自的稀疏表示系数稀疏表示。在低秩表示中,低秩结构和显着分量从源图像中分解。为了提取显着分量,学习了一个名为显着系数矩阵的投影矩阵,并为不同的源图像共享了该投影矩阵。但是,即使源图像被分解为一系列部分,这些方法仍然在VIS和IR图像的这些分解分量中使用相同的表示形式,而不管它们的不同形式如何。例如,即使小波变换将源图像分解为不同频率的子图像,相同频率的IVIS和IR图像的子图像仍然具有相同的表示形式。尽管如此,即使它们都是高频信息,它们的物理含义也大不相同。在IR图像中,高频信息表示不同材料或物体的边界。例如,如图1所示,掩体和背景的边界是高频的,而IVIS图像中的高频信息代表了丰富的纹理特征。因此,IVIS和IR图像中的高频信息都应保留在融合图像中。然而,在这种尺度上执行的融合过程必然会导致一些有价值的信息失真,而在其他尺度上,可能存在IR和IVIS图像的子图像都包含很少信息的情况。但是,该带的存在导致保留价值较低的信息。因此,对于VIS和IR图像使用相同的表示是不合适的,因为它可能导致信息的冗余或失真。
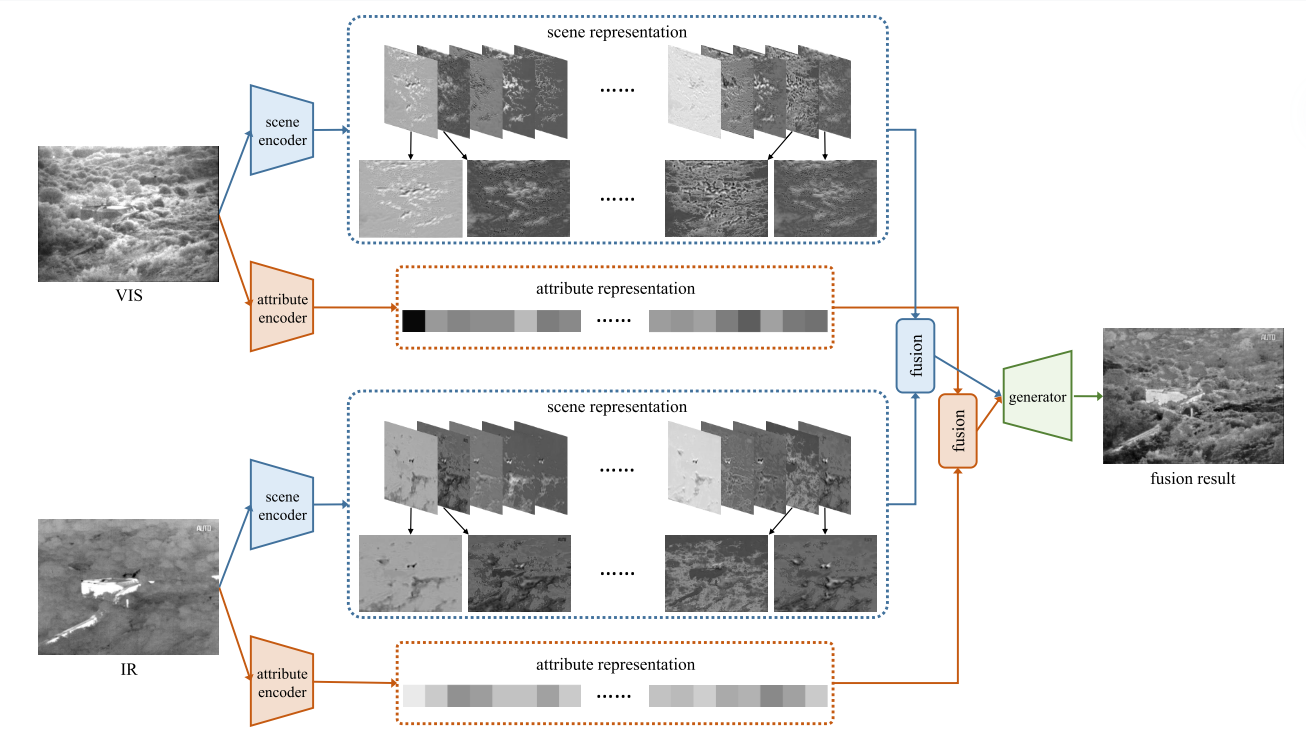
(DRF框架。这两个场景编码器是伪暹罗网络 (它们具有相同的网络体系结构,但不共享相同的权重),这两个属性编码器也是如此。属性表示是z维向量。在该图中,为了便于观察,它以四行显示。)
为了解决该问题,我们旨在尽可能地从源图像中的公共信息中分离出唯一信息。为此,我们将注意力转向源图像的成像过程。无论源图像是从可见光传感器还是红外传感器捕获的,它们都是从同一场景拍摄的,其中包含大量信息。不同之处在于,这两种类型的传感器使用其特定的成像方式来捕获原始信息的一部分。这些成像方式可以看作是原始海量信息的后处理。在捕获的场景和传感器的特定成像方式的共同作用下,IVIS和IR图像以独特的表示形式呈现相同的场景,包括梯度,对比度和照度。因此,我们不是根据信息表示的形式 (例如频率,稀疏系数和显着分量) 对源图像进行拆分,而是根据信息源进行分解。更具体地说,我们将源图像分解为两个部分: 来自场景的信息和与传感器模态有关的信息。由于与传感器模态有关的信息反映了传感器或源图像的属性,因此我们将此类信息定义为唯一的属性表示,而来自场景的信息,即场景表示,是两种类型的源图像的通用信息。基于这种新颖的分解方法,我们提出了一种新的VIF方法,称为可见光和红外图像融合 (DRF) 的解纠缠表示。
在DRF中,我们应用解纠缠的表示来解纠缠源图像中的场景和属性表示。用场景编码器提取场景表示作为公共信息,用属性编码器提取属性表示作为唯一信息,如图1所示,独特信息可以从具有可解释物理意义的公共信息中分离出来,因为独特信息与成像模态有关。然后,分别对不同源图像的解纠缠场景和属性表示执行适当的融合策略。最后,可以根据融合的表示通过预先训练的生成器生成融合结果。
贡献
-
介绍了一种新颖的图像融合分解方法。我们提出了一种新的观点,即源图像是由场景和传感器模态的共同作用形成的。在此基础上,在现有的基于分解的融合方法中,我们根据信息的来源而不是信息表示的形式对源图像进行分解(即,解纠缠表示)。
-
我们通过编码器将VIS和IR图像分解为与场景和属性相关的表示形式。然后,分别应用不同的策略来融合这些表示。最后,将融合的表示输入到预先训练的生成器中以生成融合结果。因此,我们方法中的每个网络也具有更好的可解释性。
相关工作
Visible and Infrared Image Fusion Methods
除了第一部分中的上述融合方法外,还有一些基于其他理论的方法。例如,Han等人提出了一种显着性感知的融合算法,以增强IVIS图像(带有IR图像中客观信息的)的可视化。首先应用显着性检测来描绘IR图像中的前景对象。然后,它使最终结果偏向于VIS图像,除了具有清晰的热显着性的区域。相反,GTF旨在通过IVIS图像中丰富的纹理来增强IR图像。因此,保留了IR图像的出色对比度以突出显示热目标。更具体地说,它用梯度表征IVIS图像中的反射光信息,并使用像素强度分布来描述。
许多基于深度学习的图像融合方法。例如,Li等人将源图像分解为细节和基本内容。深度学习框架用于从详细内容中提取多个特征。基于它们,它会为最终详细内容生成一些候选项,并通过max选择策略选择为最终内容。又提出了一种生成与RGB图像高度相似性的融合结果的方法。同时,通过培训网络来学习人类外观的一些相关特征,可以提高行人的可见性。Zhang等人尝试融合RGB和IR图像。它首先从RGB/IR图像中提取粗略特征,并进一步提取多级细化特征。然后,在每个级别上融合这些功能,以通过多分支模块生成跨模式功能。最后,集成了多级融合功能。在这些方法中,使用网络从原始源图像中提取深层或多层特征,而无需考虑其含义。此外,根据生成对抗网络 (GANs) 的理论,研究人员提出了几种基于GAN的VIF方法。例如,FusionGAN使用生成器生成融合图像。同时,训练鉴别器以区分结果和可见图像之间的差异。这样,融合图像被迫具有可见图像的更多细节。在此基础上,DDcGAN添加了红外鉴别器来区分结果与红外图像之间的差异,并改进了生成器体系结构以解决多分辨率图像融合问题。此外,ResNetFusion设计了两个额外的损失函数。细节损失用于提高细节质量,而目标边缘增强损失有助于锐化热目标的边缘。此外,AttentionFGAN集成了多尺度注意力机制。它帮助生成器专注于前景和背景细节中的目标。鉴别器专注于注意力区域。但是,这些手动设计的拆分方式 (例如像素强度分布和梯度) 无法完全表征每个源图像中的唯一信息。
Disentangled Representation
解纠缠表示是一种旨在对数据变化因素进行建模的理论。然后,可以学习输入图像的解纠缠表示。Tran等人提出了DR-GAN从面部变化中学习显式解纠缠表示。基于此表示,可以实现姿态不变的人脸识别。Lee等人将图像明确地嵌入到两个空间中: 域不变内容空间和域特定属性空间。通过改变领域特定的属性,它可以实现两个视觉领域之间的图像翻译。对于单图像去模糊,Lu等人从模糊图像中解开内容特征和模糊特征。Wang等人提出了解纠缠特征的高效解纠缠表示,以解决跨域人脸呈现攻击检测问题。在本文中,由于IVIS和IR图像属于两个视觉域,因此我们致力于将源图像分解为两个空间: 域不变场景空间和域特定属性空间。因此,可以使用域不变场景信息和域特定属性来表示每个源图像。
方法
Disentangle Scene and Attribute Representations
给定分别属于两个视觉域的VIS图像X和IR图像y,
我们的主要目标是将源图像拆分为共享的,域不变的场景空间S和特定的场景空间A。鉴于属性空间对于每个域都是唯一的,我们将X和Y的属性空间分别表示为AX和AY。由于场景信息在VIS和IR图像中以不同的方式表示,因此无法以相同的方式实现映射X → S和Y → S。
换句话说,不能通过相同的函数/参数从x和y提取场景信息。因此,我们设计了两个场景编码器 {Es X : X → S,Es Y : Y → S},如图2所示,这两个编码器共享相同的网络架构,但权重不相同。此外,由于两个模态属性差异很大,我们设计了两个属性编码器 {Ea X,Ea Y} 分别学习X → AX和Y → Ay。
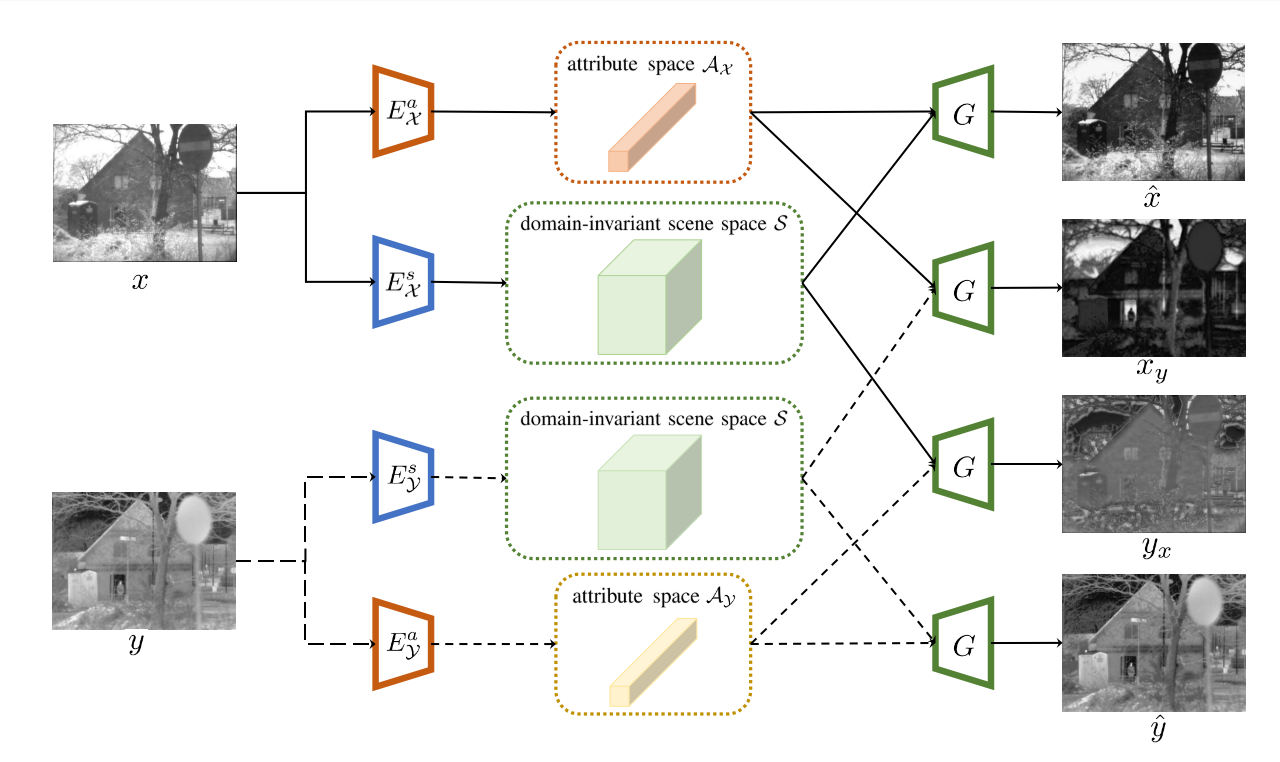
考虑到场景信息与空间和位置直接相关,场景表示以特征图的形式呈现,如图1所示,而属性与传感器模态相关并且不期望携带场景信息。因此,与特征图相比,向量的形式更适合属性信息。对于源图像x,可以将场景特征sx和属性向量ax编码为
为了实现表示解纠缠,我们执行三种策略:
1)我们共享Es X和Es Y的最后一层的权重。这样,可以将两个域中的图像的场景特征嵌入到一个公共空间中。但是,共享高级层权重的方式不能保证场景编码器对来自两个不同域的相同信息进行编码。
2)因此,对场景特征执行约束,这使得Es X和Es Y编码来自两个域的相同场景特征。
3)最后,为了抑制来自属性空间的场景信息,我们对属性向量ax和ay的分布进行了约束。因此,属性编码器将不会对场景相关信息进行编码。
然后,为了使这两种类型的信息能够表示源图像,应该有可能将空间S和A映射到原始视觉域。因此,我们采用生成器网络G来学习逆映射。考虑到AX和AY对于生成器是不一致的,并且考虑到随后的融合过程,{S,AX}→ X和 {S,AY}→ Y共享同一生成器。该生成器具有两种能力
1)一方面,原始源图像将根据场景和与之分离的属性表示进行重建。具体而言,以 {sx,ax} 和 {sy,ay} 为条件,重建图像可以定义为
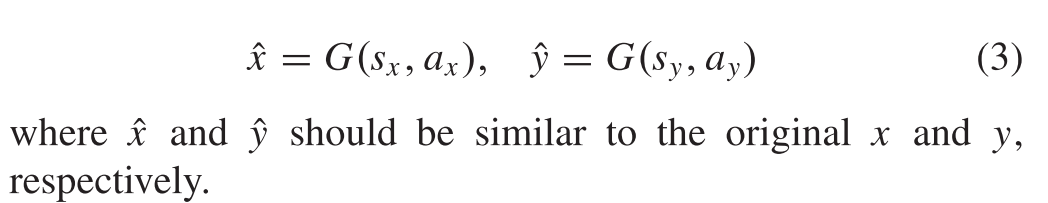
另一方面,期望S捕获跨域X和Y的信息,而AX和AY应该捕获域特定的属性,而不携带各自域的场景相关提示。鉴于x和y是同一场景的描述,sx和sy应该是相似的。因此,给定不同的属性向量,由G生成的图像应该与从中提取属性向量的那些原始图像相同。例如,以sx和ay为条件,G执行转换为
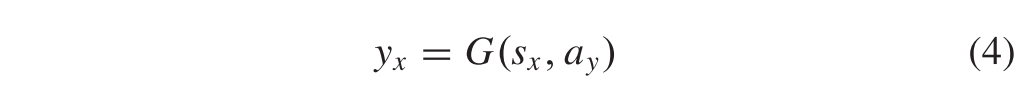
其中yx是由x变换而成的y_like图像,属性向量为y,如图2所示,yx和y属于同一个域Y。因为图像融合问题中存在成对的源图像,所以yx和y应该保持像素级的一致性。类似地,变换后的类x图像可以定义为
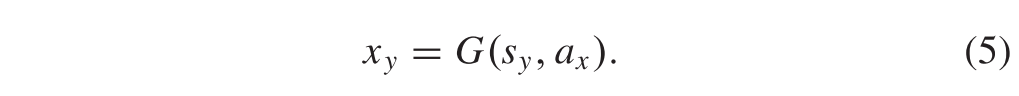
Loss Functions
1) Scene Feature Consistency Loss:
鉴于x和y是同一场景的描述,它们的场景特征应该是相似的。因此,在sx和sy上定义场景特征一致性损失为:
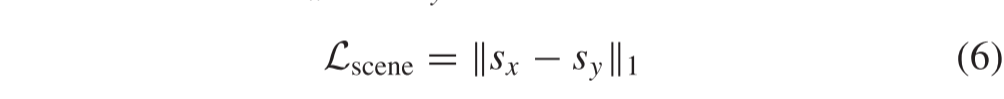
其中||·||1表示l1-norm。此外,Frobenius-范数是限制特征图之间一致性的自然选择。但是,l1-norm更适合此问题,原因如下: 由于红外和可见光传感器的成像原理不同,因此这两种类型的源图像中的场景信息不可能完全相同。例如,如图10中的第三列所示,当烟雾后面有士兵时,VIS传感器无法捕获关于他们的信息。自然,关于它们的信息不会被分解并出现在场景特征中。相反,关于它们的信息清楚地呈现在红外图像中。由于它们属于捕获的场景,因此解开的场景表示将包含这个信息场景。这是场景表示之间的显着差异,但它占场景的一小部分。我们期望场景表示的大多数比例必须相同,并对这种特殊情况给予一定的容忍度。换句话说,我们期望场景表示之间的差异是稀疏的。因此,与Frobenius-范数相比,该l1-norm更适合此问题。
2)Attribute Distribution Loss:
基于解纠缠表示,我们期望从属性空间尽可能抑制场景信息。预计属性表示将与先前的高斯分布一样接近。已经表明,KL术语鼓励解纠缠。有人认为,后验匹配因子分解单位高斯先验的更强压力会对潜在瓶颈的隐式容量施加额外的约束。为了实现这一目标,我们通过测量属性向量ax和ay的分布与先验高斯分布之间的KL散度来对它们的分布进行约束
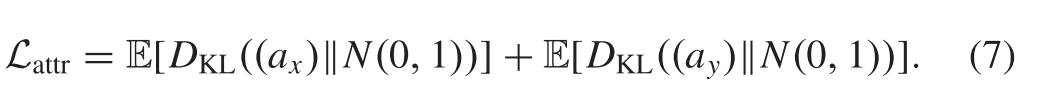
3) Self-Reconstruction Loss:
预计原始源图像将根据场景和与之分离的属性表示进行重建。也就是说,生成器G应该能够将场景特征和属性向量解码回原始源图像。因此,我们进行了自我重建损失,以使重建图像与原始图像实现高保真度。自我重建损失具体定义为
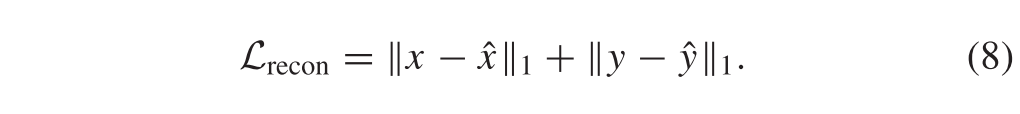
4) Domain-Translation Loss:
转换后的图像是根据一个源图像的场景特征和另一个源图像的属性向量生成的,定义为 {xy,yx }={ G(sy,ax),G(sx,ay)}。在图像融合问题中,给定x和y是成对的源图像,y是x的域Y中的理想变换图像。类似地,x是xy的期望结果。因此,可以对变换后的图像执行像素级约束,其定义如下:
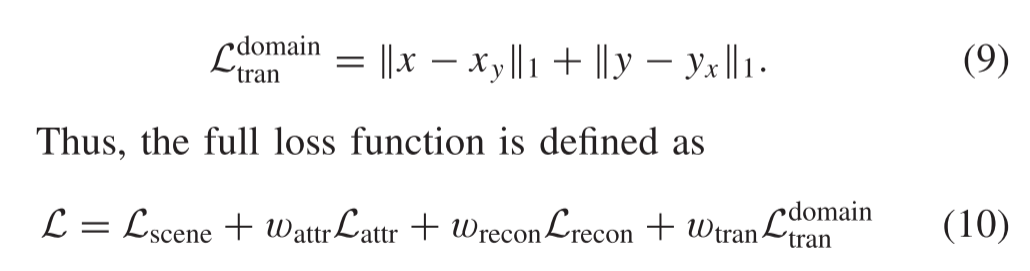
其中Wattr、Wrecon和Wtran是控制每个项权衡的超参数。通过最小化定义的L来优化四个编码器 {Es X,Ea X,Es Y,Ea Y} 和生成器G中的参数。
Network Architecture
1) Scene Encoders:
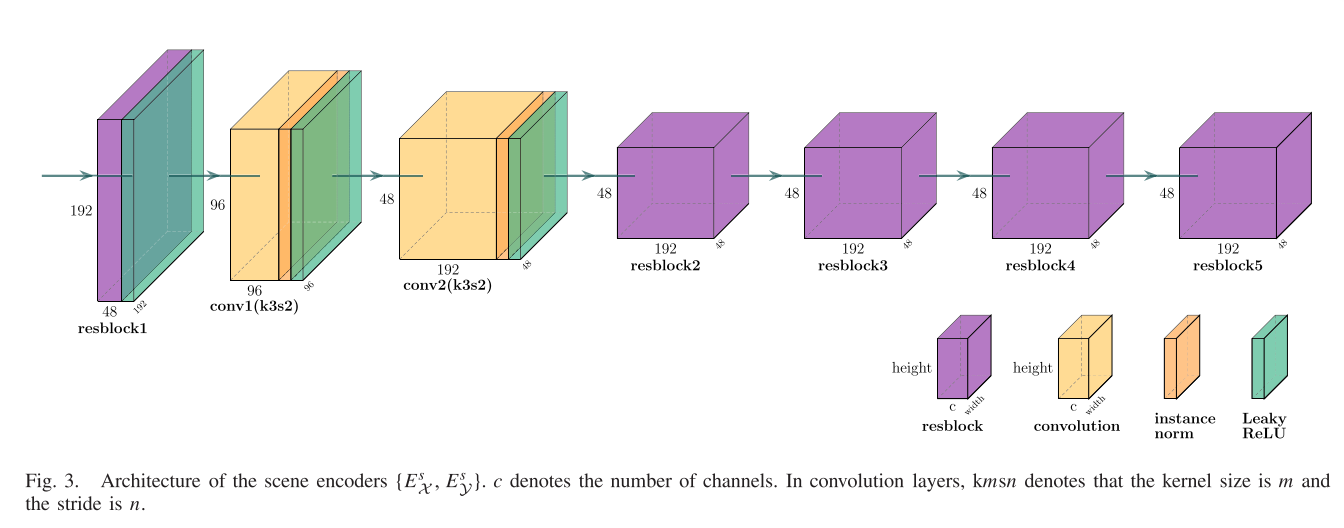
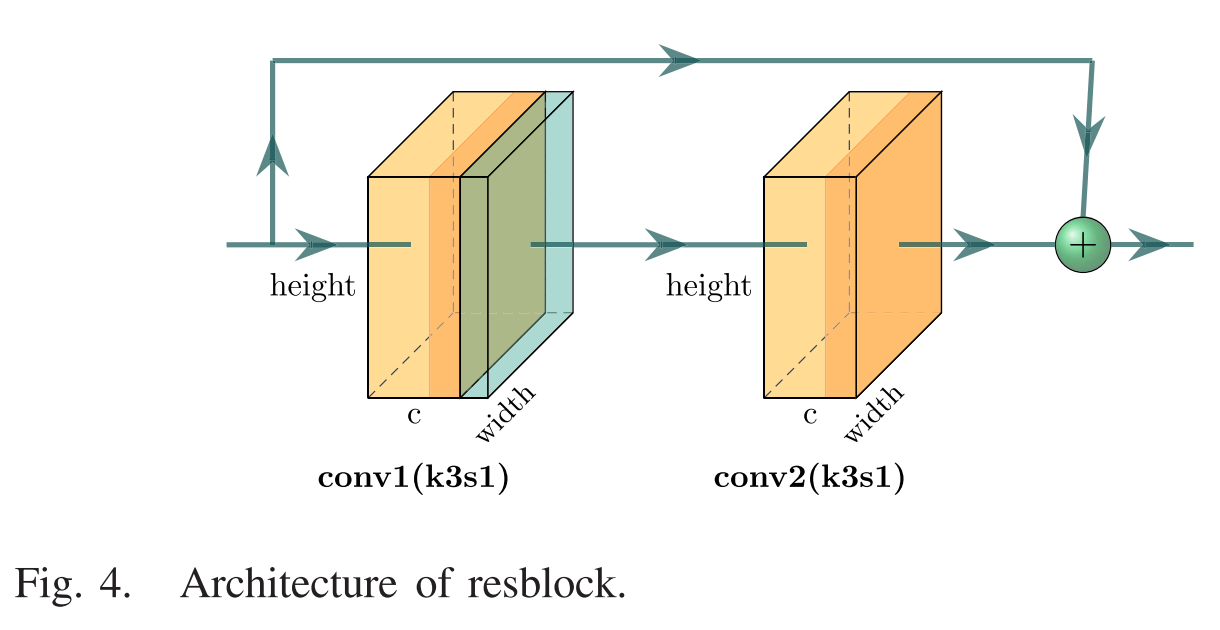
两个场景编码器 {Es X和Es Y} 的网络架构如图3所示,它由七个层组成,包括五个残差块和两个卷积层。通过输入和输出之间的直接连接,应用残余块来缓解消失的梯度和退化问题。残差块的具体架构如图4所示,激活函数为Leaky ReLU。
值得注意的是,在卷积层之后,我们采用实例归一化,因为它通过归一化特征统计来执行样式归一化。已发现这些特征统计信息带有图像的样式信息,即我们方法中的属性信息。与基于每个特征通道的minbatch统计值对均值和标准差 (SD) 进行归一化的批归一化不同,实例归一化不仅针对每个特征通道而且针对每个样本,独立地计算跨空间维度的均值和SD。数学上,给定输入批次u ∈ R(n × h × w × c),归一化的u计算为:
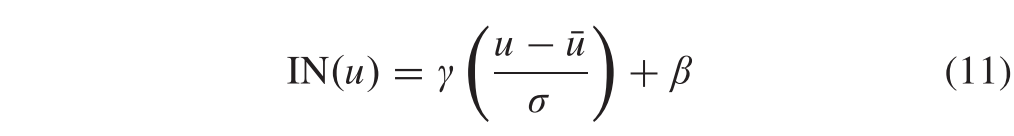
其中N,H,W和C分别表示批量大小,高度,宽度和通道数。Γ 和 β 是仿射参数,
此外,基于从域X和Y提取的场景特征共享相同的场景空间S的假设,我们共享场景编码器中最后一个残差块的权重。更具体地,Es X和Es Y共享图3中的Resblock5的权重。这样,场景表示被强制映射到公共场景空间中。
2) Attribute Encoders:
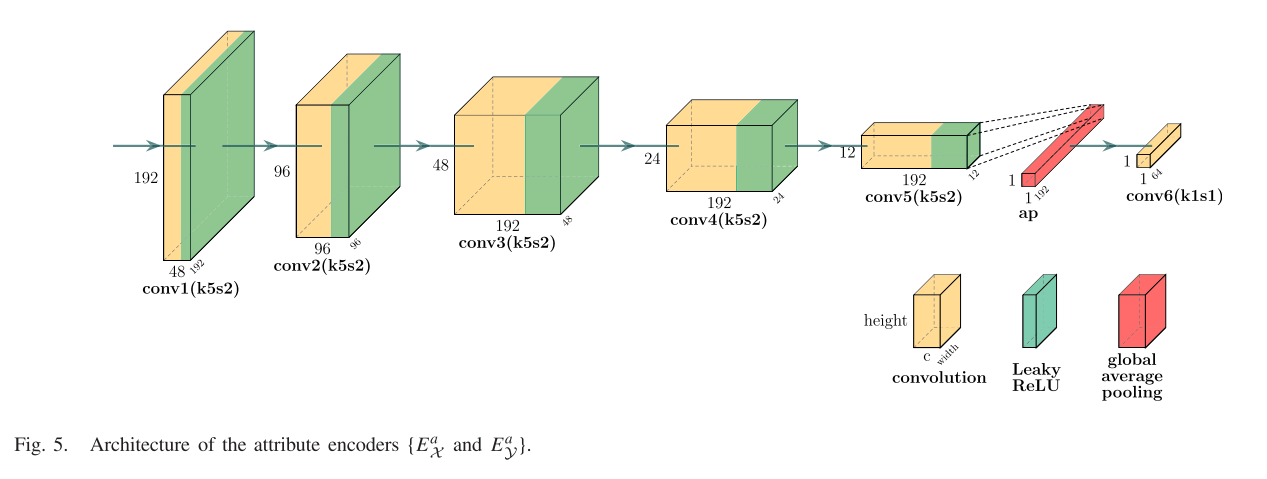
如图5所示,属性编码器的前五层是传统的卷积层,其内核大小设置为5 × 5,步幅设置为2。然后,通过跨空间维度的全局平均池化层,将属性信息映射到向量中。通过第六卷积层,得到最终的z维属性向量。为了使Ax和Ay为生成器提供两个独特的属性空间,我们对Ay中的属性向量进行了偏置,使它们与Ax中的属性向量区分开。
3) Generator:
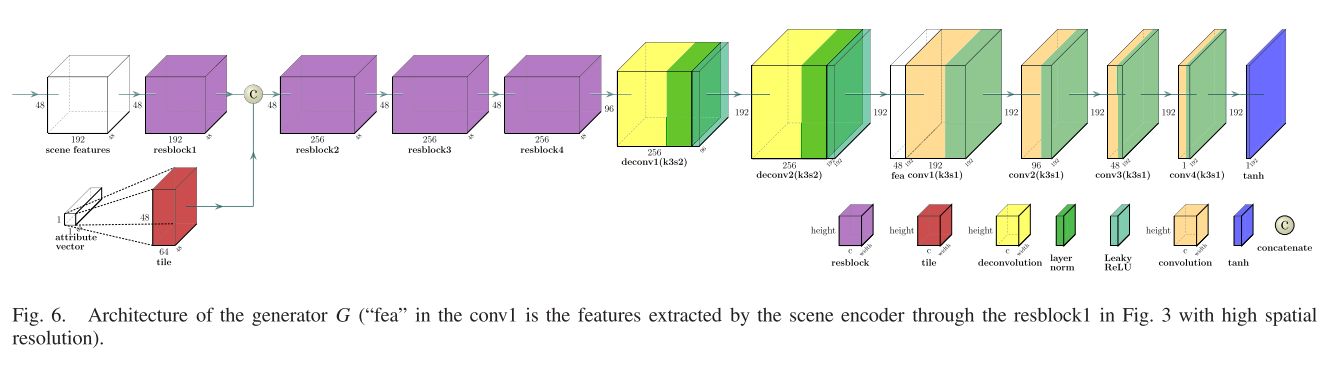
生成器G的网络架构如图6所示,对于场景特征,首先通过一个残差块。对于属性向量,它被平铺成与场景特征相同的宽度和高度。所述第一残差块的输出和所述tile 层的输出被串联并馈送到后续残差块中。然后,使用两个反卷积层对特征图进行上采样。值得注意的是,场景特征的空间分辨率降低到原始图像的四分之一,因此丢失了许多高质量的纹理细节。受U-net 的启发,为了保留丢失的信息,场景编码器中第一残差块的输出,即低级特征,也被用作场景信息的一部分。它与第二反卷积层的输出连接,并馈入发生器中的第一卷积层。经过以下四个卷积层后,特征图的通道逐渐减小到原始图像的通道中。通过tanh激活函数,生成重建图像。
值得注意的是,由于实例归一化统一了图像的样式 (属性),因此引入实例归一化不利于生成具有各种样式的图像。因此,在生成器中的卷积层之后不应用实例归一化
Fusion Block
使用预训练的编码器和生成器,根据解纠缠的表示分别在场景空间S和属性空间A上执行融合过程:
1) Scene Representation Fusion:
假设场景特征sx和sy共享同一场景。此外,基于两个场景编码器的最后残差块之间的权重共享策略以及 等式(6) 中定义的场景特征一致性损失,将sx和sy映射到一个公共场景空间中。因此,我们执行平均策略来获得融合的场景特征
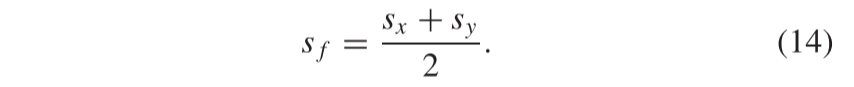
2) Attribute Representation Fusion:
对于属性向量,我们直接应用加法融合策略。融合属性向量定义为
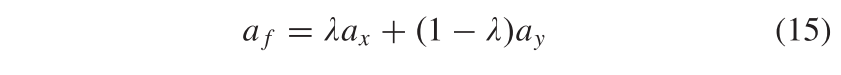
其中 λ 是介于0和1之间的超参数,用于调制融合结果的呈现属性。具体地,当 λ = 0时,融合结果看起来像属于视域Y的图像; 而 λ = 1时,结果似乎与域X中的图像相似。对于随后的各种应用目标,可以通过设置不同的 λ 来调制融合结果以呈现不同的属性。由于场景特征已被解缠,融合并固定为融合结果的s f,因此 λ 的不同设置对场景信息失真的影响很小。
最后,将融合后的场景特征和融合后的属性向量送入预训练的生成器,生成最终的融合后的图像f,可以表示为